











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






TensorFlow 2.0实战入门(下)
2019年06月16日 由 sunlei 发表
700225
0
在昨天的文章中,我们介绍了TensorFlow 2.0的初学者教程中实现一个基本神经网络的知识,今天我们继续昨天没有聊完的话题。开始学习吧~
传送门:TensorFlow 2.0实战入门(下)
与神经网络的布局和结构一样重要的是,最好记住,在一天结束时,神经网络所做的是大量的数学运算。每个节点接受上一层中节点的值,并计算它们的加权和,生成一个标量值,称为logit。就像人脑中的神经元在特定输入的提示下如何“触发”一样,我们必须指定网络中的每个节点(有时也称为神经元)在给定特定输入时如何“触发”。这就是激活函数的作用。它们取上述加权和的结果logits,并根据所使用的函数将其转换为“激活”。
一个常见的激活函数,在我们的网络中的第一个Dense()层中使用的,叫做“ReLU”,它是校正线性单元的缩写。
[caption id="attachment_41253" align="aligncenter" width="908"]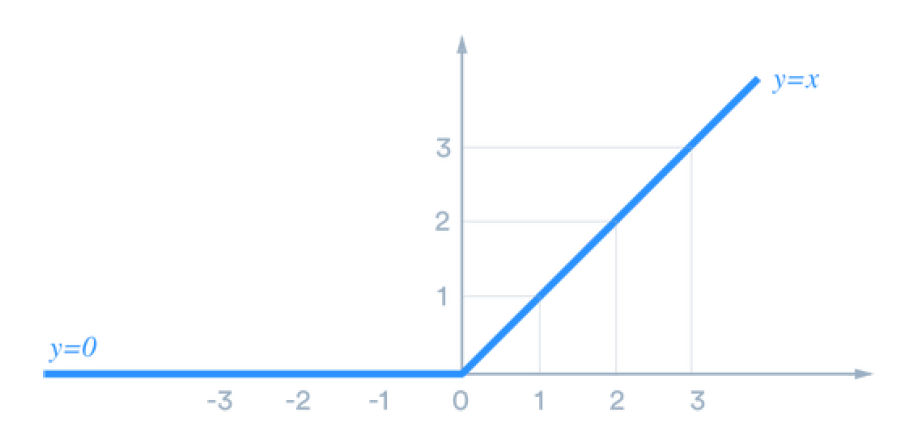 ReLU激活函数[/caption]
ReLU激活函数[/caption]
ReLU所做的是激活任何负logits 0(节点不触发),而保持任何正logits不变(节点以与输入强度成线性比例的强度触发)。有关ReLU的功能以及为什么它有用的更多信息,请参阅本文。
另一个常用的激活函数Dense()的第二个实例中使用称为“softmax”。
[caption id="attachment_41254" align="aligncenter" width="825"]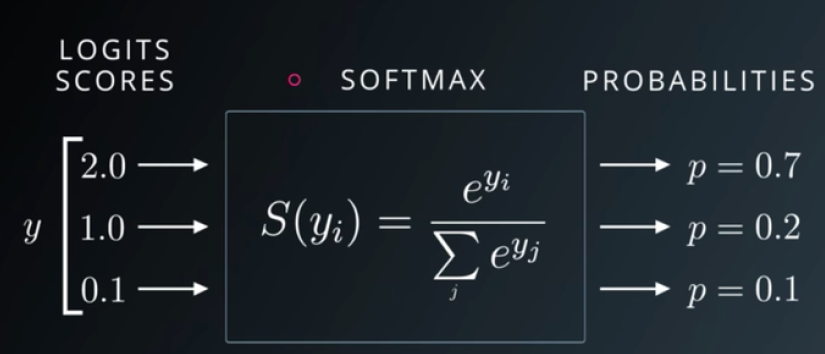 在SoftMax上的Udacity深度学习[/caption]
在SoftMax上的Udacity深度学习[/caption]
如上图所示,softmax采用由上一层激活的加权和计算的logits,并将其转换为总和为1.0的概率。这使得在输出层中使用它成为一个非常有用的激活函数,因为它为图像成为特定数字的可能性提供了易于解释的结果。
还有许多其他的激活函数,决定使用哪一个通常是一个实验或启发式判断(或两者兼而有之)的问题。
到目前为止,我们研究的最后一个未解释的代码片段是tf.keras.layers.Dropout()的调用。dropout的概念可以追溯到早期关于层之间连接性的讨论,并且必须特别处理与密集连接层相关的一些缺点。密集连接层的一个缺点是,它可能导致非常昂贵的计算神经网络。随着每一个节点向下一层的每一个节点传输信息,计算每一个节点加权和的复杂度随着每一层节点数量的增加呈指数增长。另一个缺点是,随着如此多的信息从一层传递到另一层,模型可能有过度适应训练数据的倾向,最终损害性能。
这就是Dropout存在的原因。Dropout使得给定层中的一些节点不会将它们的信息传递到下一层。这有助于计算时间和过拟合。因此,在初学者的记事本中,在两个colse()层之间调用Dropout(0.2)使得第一个colse ()层中的每个节点从计算下一层的激活中被删除的概率为0.2。您可能已经了解到,这实际上使模型中的输出层成为一个稀疏连接的层。
现在我们已经了解了模型的所有组件,让我们利用model.summary()函数对网络结构进行全面检查。
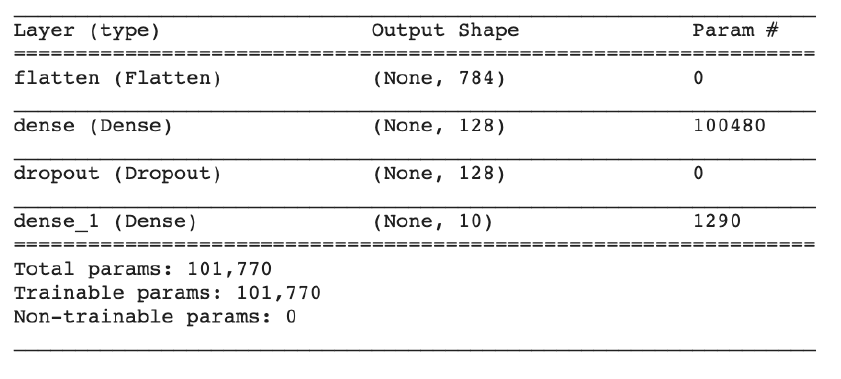
在仔细检查了输出形状之后,一切看起来都很好,所以现在让我们继续编译、培训和运行模型!
既然我们已经指定了神经网络的样子,下一步就是告诉Tensorflow如何训练它。
我们在本节中研究的代码片段如下:
在预构建的模型上调用model.compile()函数,它指定了损失函数、优化器和度量,每一个都将被解释。这些是神经网络如何产生最终预测的重要特征。
在本指南的开头提到,在高层次上,初学者笔记本中构建的模型将学习如何将某些图像分类为数字,它通过做出预测来做到这一点,观察预测与正确答案之间的距离,然后更新自身以更好地预测这些数字。损失函数是模型的一部分,用于量化预测与正确答案之间的距离。不同的模型需要不同的损失函数。例如,对于这样一个问题的损失函数,我们的模型的输出是概率,它必须与试图预测美元价格的模型的损失函数非常不同。这个特定模型的损失函数是' sparse_categorical_crossentropy ',这对于这类多类分类问题非常有用。。在我们的例子中,如果模型预测一个图像只有很小的概率成为它的实际标签,这将导致很高的损失。
另一种表达训练模型实际意义的方法是,它寻求最小化损失。如果损失是对预测与正确答案之间的距离的测量,而损失越大意味着预测越不正确,则寻求最小化损失是确定模型性能的一种可量化方法。如前所述,训练神经网络的一个关键部分是根据这些参数对图像分类的有效性来修改网络节点的数学参数。在一个称为反向传播的过程中,神经网络使用一个称为梯度下降的数学工具来更新参数来改进模型。这些术语的详细信息有些超出了本指南的范围,但是为了理解初学者的记事本在做什么,model.compile()函数的优化器参数指定了一种使反向传播过程更快、更有效的方法。“adam”优化器是一种常用的优化器,可以很好地解决这个问题。
最后的部分是在model.compile()函数指定它在评估模型时应该使用的度量标准。。精度是一个有用的,但不完美的度量模型,为gauging模型性能和它的使用,它应该由一个小的量的警告。
最后是对模型的实际训练,使用TensorFlow2.0,这很容易做到。
这一行代码非常直观,可以传递训练数据和数据的正确标签。fit()函数中的epoch参数是模型查看所有训练数据的次数。我们希望模型多次看到所有训练数据的原因是,在计算加权和以显著提高预测能力时,一次经历可能不足以使模型充分更新其权重。

运行这段代码,您可以看到在每个时段,模型都会浏览训练集中的所有60K图像。您还可以看到损失随着每个时段的增加而减少,精度也随之提高,这意味着模型在对每个时段的数字进行分类方面越来越出色。
最后,使用model.evaluate(x_测试,y_测试),我们可以预测测试集的类,并查看模型的运行情况。
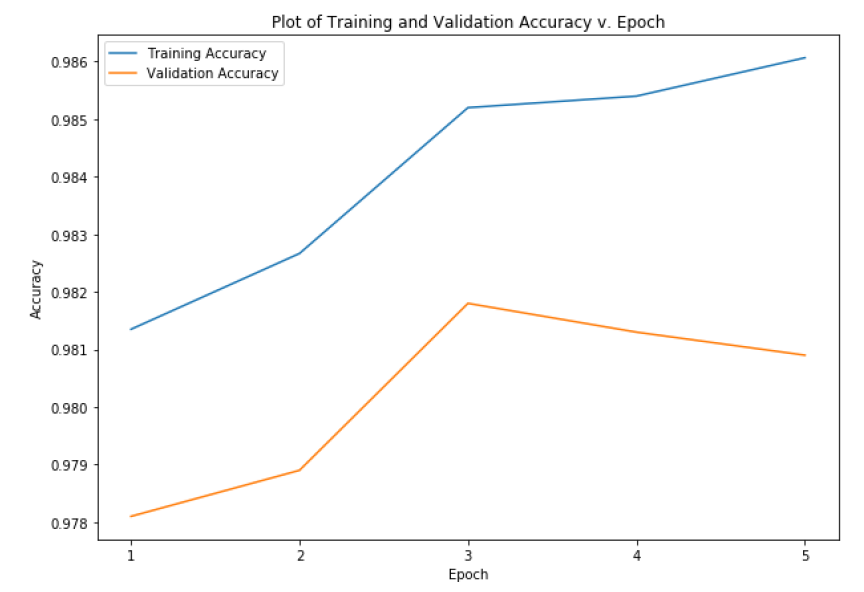
这张图显示,尽管我们训练的时间越长,训练的准确性就越高,但验证的准确性开始趋于平稳或下降,这表明我们可能不需要训练超过5个阶段。
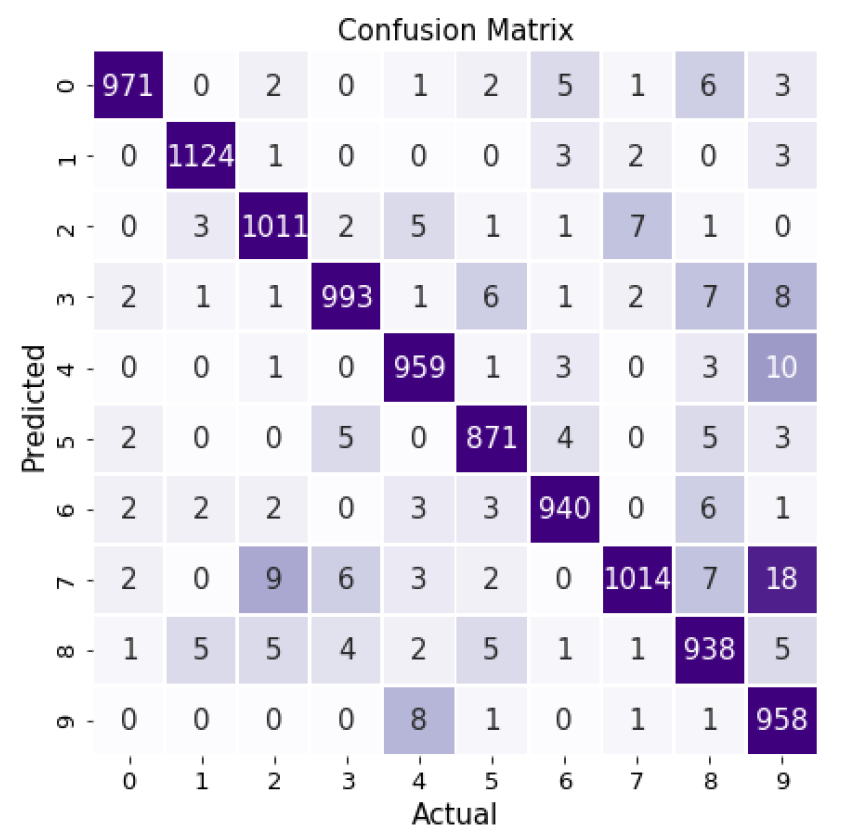
为了更详细地评估模型的执行情况,我们可以构建一个混淆矩阵。从这个混淆矩阵中我们可以看出,我们的模型中9的问题最多,而且往往与7、4或3混淆。
恭喜你!您已经通过了TensorFlow2.0初学者笔记本的指南,现在对神经网络层的形状、激活函数、logits、dropout、优化器、丢失函数和丢失以及epochs有了更好的理解。您还熟悉了如何使用TensorFlow/Keras实现这些概念!对于更多的实践,我建议使用本指南中讨论的不同参数进行试验,看看它们对模型性能有什么影响。快去感受创造的快乐吧!
传送门:TensorFlow 2.0实战入门(下)
激活功能
与神经网络的布局和结构一样重要的是,最好记住,在一天结束时,神经网络所做的是大量的数学运算。每个节点接受上一层中节点的值,并计算它们的加权和,生成一个标量值,称为logit。就像人脑中的神经元在特定输入的提示下如何“触发”一样,我们必须指定网络中的每个节点(有时也称为神经元)在给定特定输入时如何“触发”。这就是激活函数的作用。它们取上述加权和的结果logits,并根据所使用的函数将其转换为“激活”。
一个常见的激活函数,在我们的网络中的第一个Dense()层中使用的,叫做“ReLU”,它是校正线性单元的缩写。
[caption id="attachment_41253" align="aligncenter" width="908"]
ReLU激活函数[/caption]ReLU所做的是激活任何负logits 0(节点不触发),而保持任何正logits不变(节点以与输入强度成线性比例的强度触发)。有关ReLU的功能以及为什么它有用的更多信息,请参阅本文。
另一个常用的激活函数Dense()的第二个实例中使用称为“softmax”。
[caption id="attachment_41254" align="aligncenter" width="825"]
在SoftMax上的Udacity深度学习[/caption]如上图所示,softmax采用由上一层激活的加权和计算的logits,并将其转换为总和为1.0的概率。这使得在输出层中使用它成为一个非常有用的激活函数,因为它为图像成为特定数字的可能性提供了易于解释的结果。
还有许多其他的激活函数,决定使用哪一个通常是一个实验或启发式判断(或两者兼而有之)的问题。
Dropout
到目前为止,我们研究的最后一个未解释的代码片段是tf.keras.layers.Dropout()的调用。dropout的概念可以追溯到早期关于层之间连接性的讨论,并且必须特别处理与密集连接层相关的一些缺点。密集连接层的一个缺点是,它可能导致非常昂贵的计算神经网络。随着每一个节点向下一层的每一个节点传输信息,计算每一个节点加权和的复杂度随着每一层节点数量的增加呈指数增长。另一个缺点是,随着如此多的信息从一层传递到另一层,模型可能有过度适应训练数据的倾向,最终损害性能。
这就是Dropout存在的原因。Dropout使得给定层中的一些节点不会将它们的信息传递到下一层。这有助于计算时间和过拟合。因此,在初学者的记事本中,在两个colse()层之间调用Dropout(0.2)使得第一个colse ()层中的每个节点从计算下一层的激活中被删除的概率为0.2。您可能已经了解到,这实际上使模型中的输出层成为一个稀疏连接的层。
现在我们已经了解了模型的所有组件,让我们利用model.summary()函数对网络结构进行全面检查。
在仔细检查了输出形状之后,一切看起来都很好,所以现在让我们继续编译、培训和运行模型!
编译、训练和运行神经网络
既然我们已经指定了神经网络的样子,下一步就是告诉Tensorflow如何训练它。
编译模型
我们在本节中研究的代码片段如下:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
在预构建的模型上调用model.compile()函数,它指定了损失函数、优化器和度量,每一个都将被解释。这些是神经网络如何产生最终预测的重要特征。
损失函数
在本指南的开头提到,在高层次上,初学者笔记本中构建的模型将学习如何将某些图像分类为数字,它通过做出预测来做到这一点,观察预测与正确答案之间的距离,然后更新自身以更好地预测这些数字。损失函数是模型的一部分,用于量化预测与正确答案之间的距离。不同的模型需要不同的损失函数。例如,对于这样一个问题的损失函数,我们的模型的输出是概率,它必须与试图预测美元价格的模型的损失函数非常不同。这个特定模型的损失函数是' sparse_categorical_crossentropy ',这对于这类多类分类问题非常有用。。在我们的例子中,如果模型预测一个图像只有很小的概率成为它的实际标签,这将导致很高的损失。
优化器
另一种表达训练模型实际意义的方法是,它寻求最小化损失。如果损失是对预测与正确答案之间的距离的测量,而损失越大意味着预测越不正确,则寻求最小化损失是确定模型性能的一种可量化方法。如前所述,训练神经网络的一个关键部分是根据这些参数对图像分类的有效性来修改网络节点的数学参数。在一个称为反向传播的过程中,神经网络使用一个称为梯度下降的数学工具来更新参数来改进模型。这些术语的详细信息有些超出了本指南的范围,但是为了理解初学者的记事本在做什么,model.compile()函数的优化器参数指定了一种使反向传播过程更快、更有效的方法。“adam”优化器是一种常用的优化器,可以很好地解决这个问题。
度量标准
最后的部分是在model.compile()函数指定它在评估模型时应该使用的度量标准。。精度是一个有用的,但不完美的度量模型,为gauging模型性能和它的使用,它应该由一个小的量的警告。
Training the model
最后是对模型的实际训练,使用TensorFlow2.0,这很容易做到。
model.fit(x_train, y_train, epochs=5)
这一行代码非常直观,可以传递训练数据和数据的正确标签。fit()函数中的epoch参数是模型查看所有训练数据的次数。我们希望模型多次看到所有训练数据的原因是,在计算加权和以显著提高预测能力时,一次经历可能不足以使模型充分更新其权重。
运行这段代码,您可以看到在每个时段,模型都会浏览训练集中的所有60K图像。您还可以看到损失随着每个时段的增加而减少,精度也随之提高,这意味着模型在对每个时段的数字进行分类方面越来越出色。
评估模型
最后,使用model.evaluate(x_测试,y_测试),我们可以预测测试集的类,并查看模型的运行情况。
这张图显示,尽管我们训练的时间越长,训练的准确性就越高,但验证的准确性开始趋于平稳或下降,这表明我们可能不需要训练超过5个阶段。
为了更详细地评估模型的执行情况,我们可以构建一个混淆矩阵。从这个混淆矩阵中我们可以看出,我们的模型中9的问题最多,而且往往与7、4或3混淆。
结论
恭喜你!您已经通过了TensorFlow2.0初学者笔记本的指南,现在对神经网络层的形状、激活函数、logits、dropout、优化器、丢失函数和丢失以及epochs有了更好的理解。您还熟悉了如何使用TensorFlow/Keras实现这些概念!对于更多的实践,我建议使用本指南中讨论的不同参数进行试验,看看它们对模型性能有什么影响。快去感受创造的快乐吧!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消