











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






扩展高质量AI数据标记的基本技巧与提示
2019年06月20日 由 董灵灵 发表
408452
0
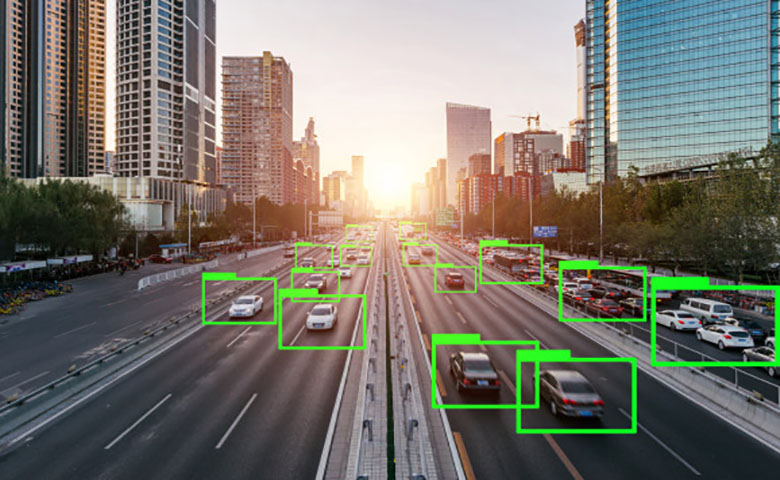 在每个行业中,工程师和科学家都在竞相为AI清理并构造大量数据。比如,计算机视觉工程师团队使用有标记的数据来设计深度学习算法,并训练自动驾驶汽车识别行人、树木、路牌和其他车辆。
在每个行业中,工程师和科学家都在竞相为AI清理并构造大量数据。比如,计算机视觉工程师团队使用有标记的数据来设计深度学习算法,并训练自动驾驶汽车识别行人、树木、路牌和其他车辆。这些系统的成功取决于循环中熟练的人,他们为机器学习标记和构建数据。高质量的数据可以提高模型性能。当数据标记质量低时,模型将难以学习。
根据分析公司Cognilytica的报告,在AI项目中大约80%的时间用于聚合,清理,标记和增加模型使用的数据。只有20%用于算法开发,模型训练和调优以及操作。
这些任务是人工智能发展的核心,需要战略思维,以及一套更先进的工程或计算机科学技能。最好在需要专业知识、协作和分析技能的任务上部署更昂贵的人力资源,如数据科学家和ML工程师。
比较用于机器学习的数据标记
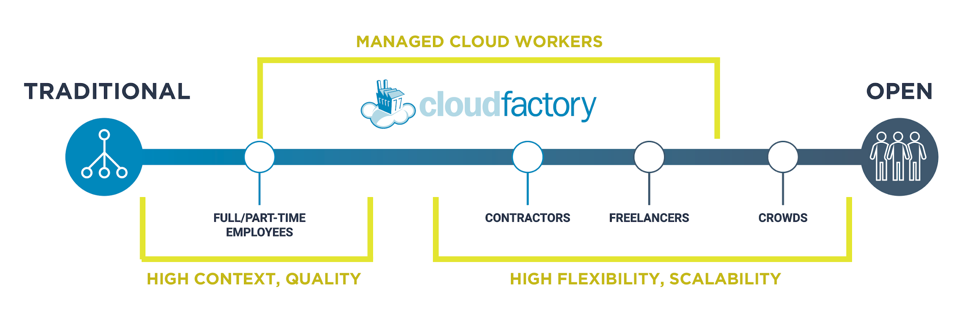
越来越多的组织正在使用以下四个选项中的一个或多个为AI项目提供数据标记。每种选择都会带来好处和挑战,具体取决于项目需求。
1.全职和兼职员工可以管理高质量的数据标签,这种方法可以正常工作,直到规模扩大。将会有一些员工流失,现有团队必须加快每个新员工的工作速度,增加成本和管理负担。
2. 承包商和自由职业者是另一种选择。采购和管理合同团队需要时间。如果人力资源不涉及雇用承包商,员工可能不会受到与全职雇员相同的文化和技能评估。在质量方面,这可能是一个问题,因此需要额外的时间进行培训和管理。
3. 众包使用云将数据任务一次性发送给大量人员。质量是通过共识确定的:几个人完成相同的任务,大多数工人提供的答案被选为正确的。我们过去曾使用此模型进行CloudFactory的数据工作,我们的客户成功团队发现,每个任务的共识模型成本比首次通过时可以满足质量标准的流程高出约200%。众包是短期项目的理想选择。
4. 在过去十年中,托管云计算工作者已经成为一种选择。这种方法结合了训练有素的内部团队的质量和人群的可扩展性。它是高质量数据标记的理想选择,而高质量数据标记通常需要工作人员理解上下文。随着时间的推移,管理团队中的标签人员会增加他们对业务规则、边缘案例和上下文的理解,因此他们可以做出更准确的主观决策,从而获得更高质量的数据。
 在AI项目团队和数据贴标人之间建立一个封闭的反馈循环至关重要。随着开发团队对模型进行训练和调整,任务可能会发生变化,因此标签团队必须能够快速适应并更改工作流程。
在AI项目团队和数据贴标人之间建立一个封闭的反馈循环至关重要。随着开发团队对模型进行训练和调整,任务可能会发生变化,因此标签团队必须能够快速适应并更改工作流程。按小时而非按任务收费的劳动力解决方案旨在支持这些迭代。一个2019 HiveMind的研究表明,通过任务可以支付工作者激励以牺牲质量为代价快速完成任务。
寻找数据标记团队时要问的关键问题
组织在比较数据标记人员选项时应向员工供应商询问这些问题:
规模:您的标记团队能否根据需求增加或减少他们为我们完成的任务数量?
质量:您能否让我们了解工作质量和员工生产力?
速度:您按时交付数据标记工作的记录?
工具:我们必须使用您的工具还是我们可以自己构建?
敏捷:如果我们的工具或流程发生变化,会发生什么?
合同条款:如果我们需要取消与您的团队合作,会发生什么?

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消