











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






深度学习的未来:神经网络架构搜索(NAS)
2019年06月30日 由 sunlei 发表
849774
0
我们大多数人可能都知道ResNet的成功,它是2015年ILSVRC图像分类、检测和定位的大赢家,也是2015年MS COCO检测和分割的大赢家。它是一个巨大的体系结构,到处都有跳跃连接。当我使用这个ResNet作为我的机器学习项目的预培训网络时,我就在想“怎么会有人提出这样的体系结构呢?”
[caption id="attachment_41615" align="aligncenter" width="871"]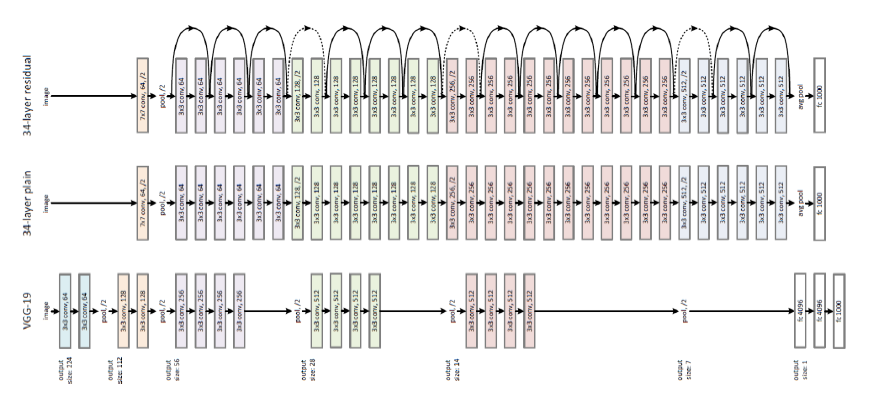 大型人类工程图像分类体系结构[/caption]
大型人类工程图像分类体系结构[/caption]
不久之后,我了解到许多工程师和科学家用他们多年的经验建造了这个建筑。还有更多的预感,而不是完整的数学,会告诉你“我们现在需要一个5x5的过滤器,以达到最佳精度”。对于图像分类任务,我们有很好的体系结构,但是很多像我这样的年轻学习者在处理非图像数据集时,通常会花费数小时来修复架构。我们当然希望有人能为我们做这件事。
在神经架构搜索(NAS),自动化架构工程的过程就出现了。我们只需要为NAS系统提供一个数据集,它将为我们提供该数据集的最佳架构。NAS可以看作AutoML的子域,与超参数优化有明显的重叠。为了理解NAS,我们需要深入研究它在做什么。它是从所有可能的体系结构中找到一个体系结构,通过遵循将性能最大化的搜索策略。下图总结了NAS算法。
[caption id="attachment_41616" align="aligncenter" width="854"]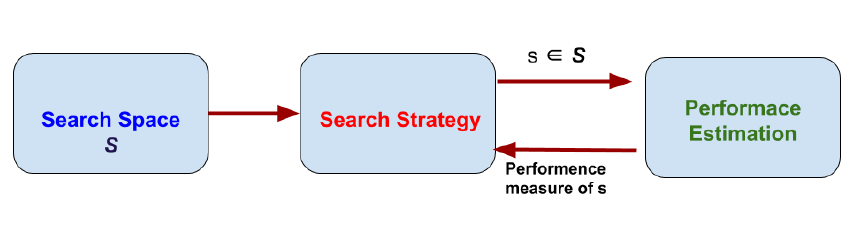 NAS方法的维度[/caption]
NAS方法的维度[/caption]
它有三个独立的维度搜索空间,搜索策略和性能估计。
搜索空间定义了NAS方法原则上可以发现哪些神经结构。它可以是链式结构,其中层(n-1)的输出作为层(n)的输入,也可以是具有跳跃连接(多分支网络)的现代复杂结构。
[caption id="attachment_41618" align="aligncenter" width="616"]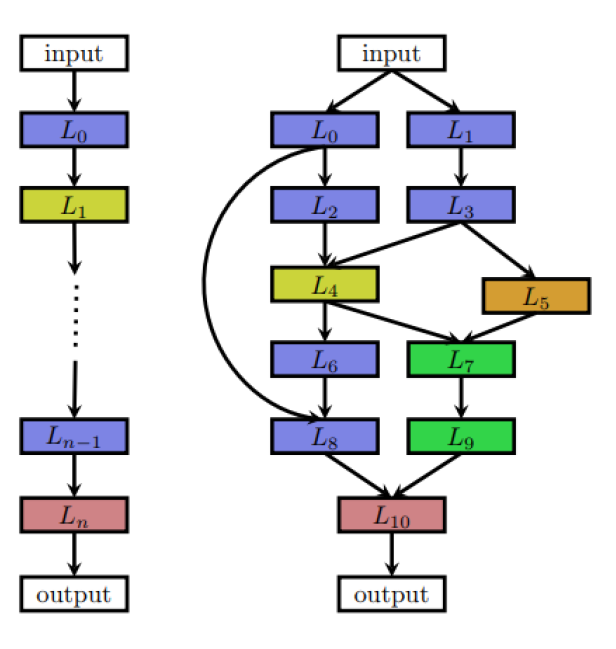 链状多分支网络[/caption]
链状多分支网络[/caption]
有些时候,人们确实希望使用手工制作的外部架构(宏架构)和重复的主题或单元。在这种情况下,外部结构是固定的,而NAS只搜索单元结构。这种类型的搜索称为微搜索或单元搜索。
[caption id="attachment_41620" align="aligncenter" width="677"]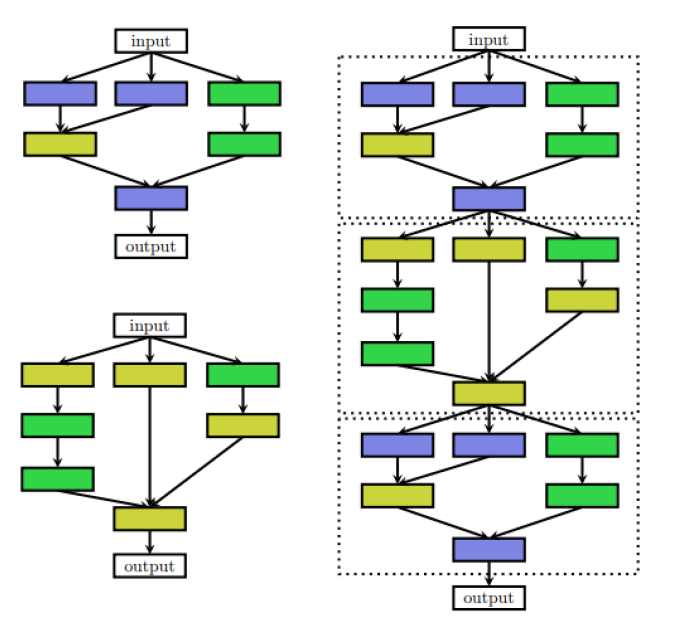 左:单元结构右:单元被放置在手工制作的外部结构中。[/caption]
左:单元结构右:单元被放置在手工制作的外部结构中。[/caption]
在许多NAS方法中,微观结构和宏观结构都采用层次结构搜索;它由几个层次的图案组成。第一级由一组基本操作组成,第二级是通过有向无环图连接基本操作的不同基序,第三级是编码如何连接第二级基序的基序,依此类推。
为了解释搜索策略和性能评估,下面将讨论三种不同的NAS方法。
我们知道强化学习;在哪里根据θ参数化的策略执行一些操作。然后,代理根据所采取操作的奖励更新策略θ。对于NAS,代理生成模型体系结构、子网络(操作)。然后对模型进行数据集培训,并将模型对验证数据的性能作为奖励。
[caption id="attachment_41623" align="aligncenter" width="824"]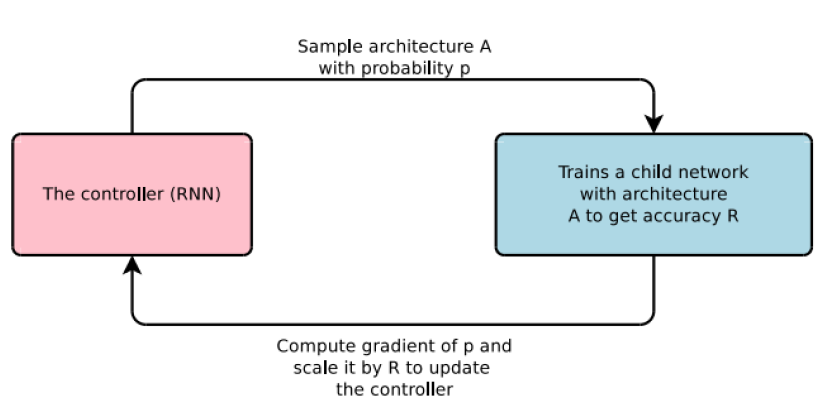 控制器扮演代理人的角色,准确度作为奖励。[/caption]
控制器扮演代理人的角色,准确度作为奖励。[/caption]
一般来说,递归神经网络(RNN)被视为控制器或代理。它生成字符串,模型是以随机字符串的形式构建的。
[caption id="attachment_41624" align="aligncenter" width="667"]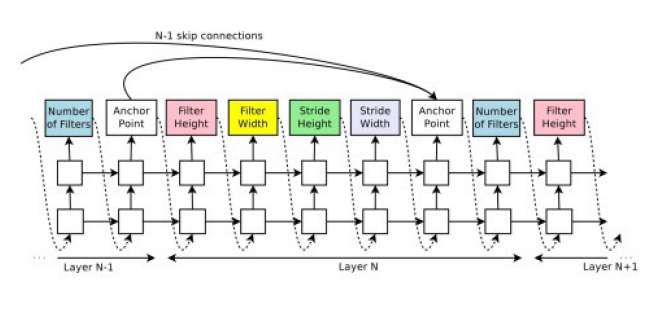 RNN生成的用于创建模型的字符串示例[/caption]
RNN生成的用于创建模型的字符串示例[/caption]
例如,在图5中使用连续的RNN输出来构建滤波器; 从过滤器高度开始到跨距宽度。输出定位点用于指示跳过连接。在第N层,锚点将包含N - 1个基于内容的sigmoid,表示需要连接的前一层。
RNN的训练策略梯度法迭代更新政策θ。这里跳过了详细的计算。
PNAS执行单元格搜索,如本教程的搜索空间部分所述。它们从块构造单元格,并通过以预定义的方式添加单元格来构造完整的网络。

单元以预先定义的数字串联起来形成网络。每个细胞由若干块组成(原文中使用了5块)。
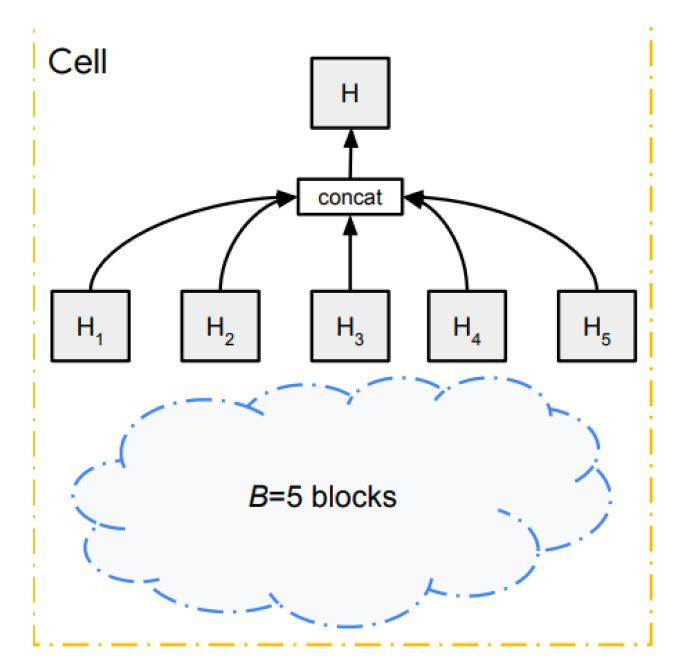
这些块由预先定义的操作组成。
[caption id="attachment_41630" align="aligncenter" width="796"]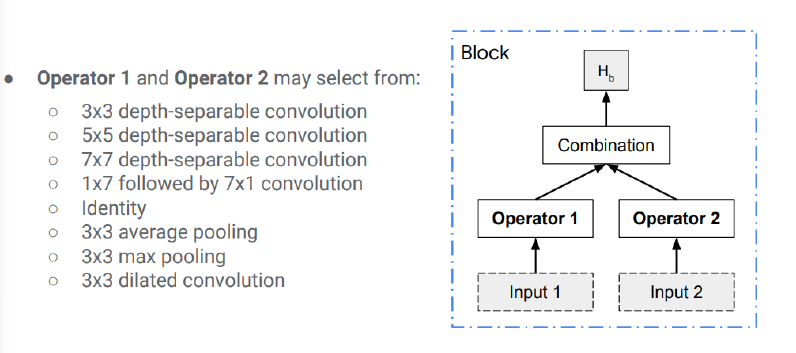 块的结构。组合函数只是元素相加。[/caption]
块的结构。组合函数只是元素相加。[/caption]
操作结果表明,图中所示为原论文所使用的图形,可以进行扩展。
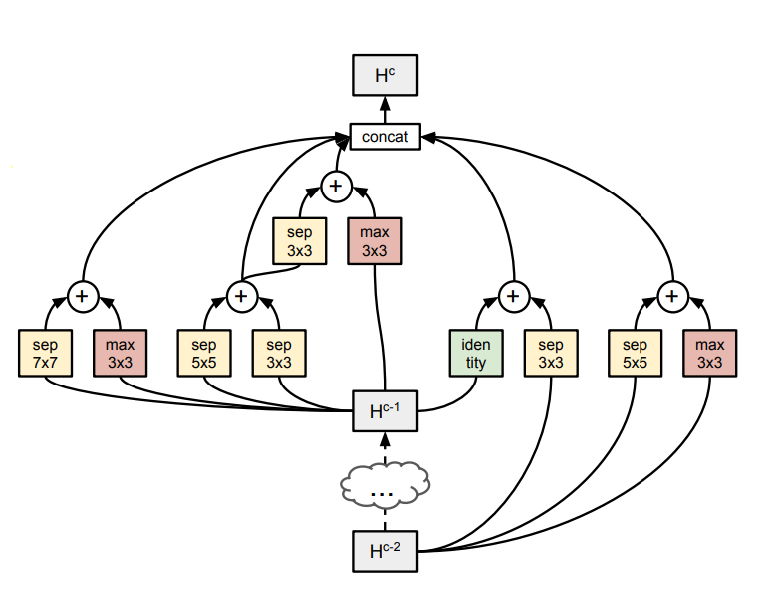
在左侧,显示了一个完整的示例。即使在这个单元或微搜索中,也有10种有效的组合来检查以找到最佳的单元结构。
因此,为了降低复杂性,首先只构建只有1个块的单元。这很容易,因为在上述操作中,只有256个不同的单元是可能的。然后选择性能最好的前k个单元格展开为2个块单元格,最多重复5个块。
但是,对于一个合理的K,太多的2个街区的候选人培训。为了解决这个问题,我们训练了一个“廉价”的代理模型,它通过读取字符串(单元格被编码成字符串)来预测最终的性能。在构建、培训和验证单元时,将收集此培训的数据。
例如,我们可以构建所有256个单块单元,并测量它们的性能。并用这些数据训练代理模型。然后用这个模型来预测2个block cell的性能而不需要实际的训练和测试。当然,代理模型应该能够处理可变大小的输入。然后选择模型预测的表现最好的2个block cell top K。然后这两个块单元格被实际训练,“代理”模型被微调,这些单元格被扩展到3个块,并被迭代。
[caption id="attachment_41632" align="aligncenter" width="792"]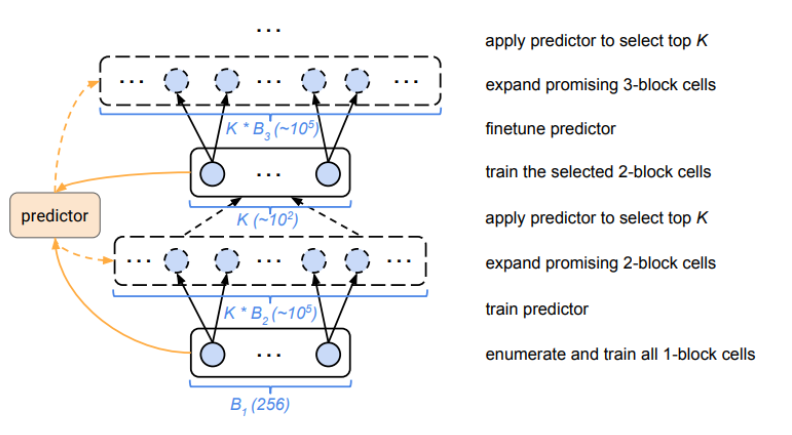 PNAS的步骤[/caption]
PNAS的步骤[/caption]
神经架构的搜索空间是离散的,即一个架构与另一个架构至少有一个层或层中的一些参数不同,例如5x5过滤器与7x7过滤器。该方法将连续松弛法应用于离散搜索,实现了基于梯度的直接优化。
我们搜索的单元可以是一个有向无环图,其中每个节点x是一个潜在的表示(例如卷积网络中的特征图),每个有向边缘(i,j)与一些操作o(i,j)(卷积、最大池等)相关联,这些操作转换x(i),并在节点x(j)存储一个潜在的表示。
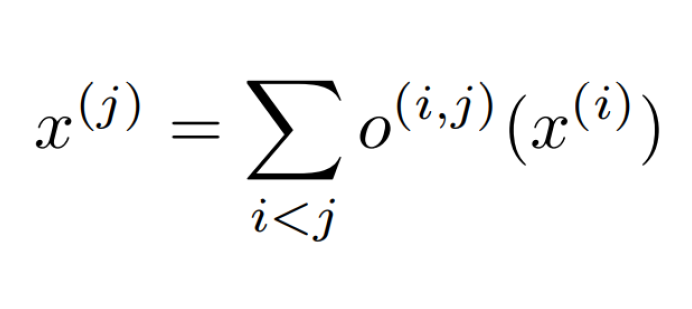
每个节点的输出可以用左边的公式计算。以这样的方式枚举节点,即从节点x(i)到x(j)有一条边(i,j),然后i
在连续松弛中,而不是在两个节点之间进行单一操作。使用每个可能操作的凸组合。为了在图中对此进行建模,将保留两个节点之间的多个边,每个边对应一个特定的操作。每个边也有一个重量α。
[caption id="attachment_41634" align="aligncenter" width="540"]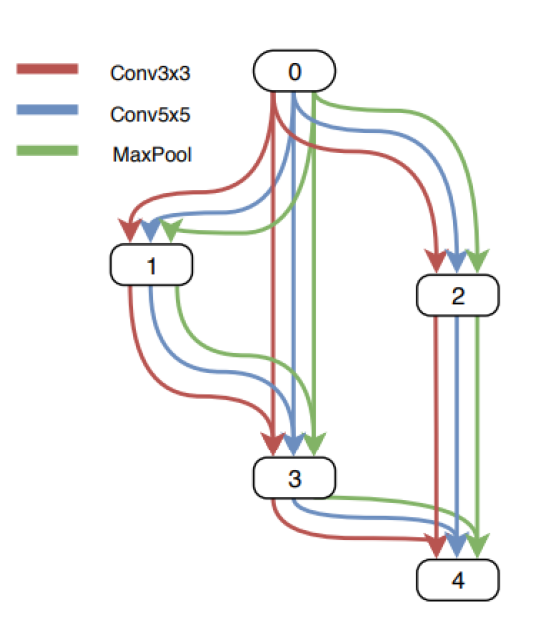 离散问题的连续松弛[/caption]
离散问题的连续松弛[/caption]
现在o(i,j)节点x(i)和x(j)之间的操作是一组操作o(i,j)的凸组合,其中o(.)_s,其中s是所有可能操作的集合。
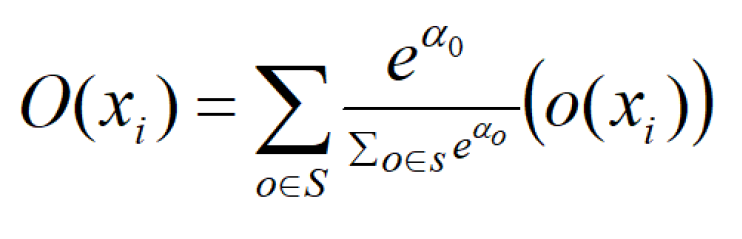
O(i,j)的输出由上面方程计算。
分别用l_train和l_val表示培训和验证损失。这两种损耗不仅取决于结构参数α,还取决于网络中的权重“w”。架构(architecture)搜索的目标是找到将验证损失L_val(w*,α*)最小化的α*,其中与架构相关的权重“w*”通过最小化培训损失获得。
w∗ = argmin L_train(w, α∗ ).
这意味着一个以α为上层变量,w为下层变量的双层优化问题:
α * = argmin L_val(w ∗ (α), α)
s.t. w ∗ (α) = argmin L_train(w, α)
训练后,某些边的α变得比其他边大得多。为了推导这个连续模型的离散结构,在两个节点之间,只保留具有最大权重的边。
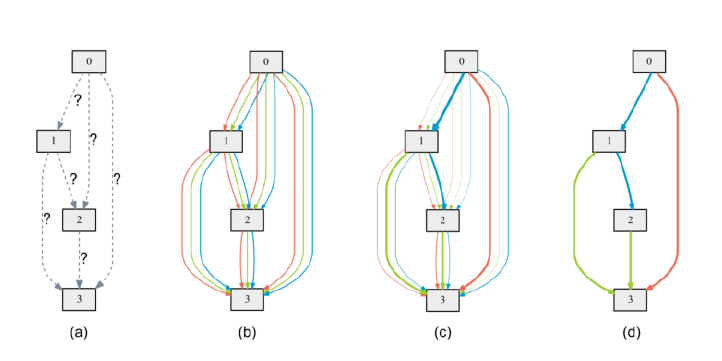
a)边缘操作最初未知。b)通过在每个边上放置一个候选操作的混合物来对搜索空间进行连续松弛c)在双层优化过程中,一些权重增加,一些权重下降d)仅通过在两个节点之间取最大权重的边来构建最终架构。
当找到这些单元后,这些单元就被用来构建更大的网络。
本教程到此结束。这里有很多细节和方法我没有介绍,但是NAS已经成为一个非常活跃的领域,为了跟踪正在进行的工作,大家也可以访问 AutoML这个网站继续学习。
[caption id="attachment_41615" align="aligncenter" width="871"]
大型人类工程图像分类体系结构[/caption]不久之后,我了解到许多工程师和科学家用他们多年的经验建造了这个建筑。还有更多的预感,而不是完整的数学,会告诉你“我们现在需要一个5x5的过滤器,以达到最佳精度”。对于图像分类任务,我们有很好的体系结构,但是很多像我这样的年轻学习者在处理非图像数据集时,通常会花费数小时来修复架构。我们当然希望有人能为我们做这件事。
在神经架构搜索(NAS),自动化架构工程的过程就出现了。我们只需要为NAS系统提供一个数据集,它将为我们提供该数据集的最佳架构。NAS可以看作AutoML的子域,与超参数优化有明显的重叠。为了理解NAS,我们需要深入研究它在做什么。它是从所有可能的体系结构中找到一个体系结构,通过遵循将性能最大化的搜索策略。下图总结了NAS算法。
[caption id="attachment_41616" align="aligncenter" width="854"]
NAS方法的维度[/caption]它有三个独立的维度搜索空间,搜索策略和性能估计。
搜索空间定义了NAS方法原则上可以发现哪些神经结构。它可以是链式结构,其中层(n-1)的输出作为层(n)的输入,也可以是具有跳跃连接(多分支网络)的现代复杂结构。
[caption id="attachment_41618" align="aligncenter" width="616"]
链状多分支网络[/caption]有些时候,人们确实希望使用手工制作的外部架构(宏架构)和重复的主题或单元。在这种情况下,外部结构是固定的,而NAS只搜索单元结构。这种类型的搜索称为微搜索或单元搜索。
[caption id="attachment_41620" align="aligncenter" width="677"]
左:单元结构右:单元被放置在手工制作的外部结构中。[/caption]在许多NAS方法中,微观结构和宏观结构都采用层次结构搜索;它由几个层次的图案组成。第一级由一组基本操作组成,第二级是通过有向无环图连接基本操作的不同基序,第三级是编码如何连接第二级基序的基序,依此类推。
为了解释搜索策略和性能评估,下面将讨论三种不同的NAS方法。
强化学习
我们知道强化学习;在哪里根据θ参数化的策略执行一些操作。然后,代理根据所采取操作的奖励更新策略θ。对于NAS,代理生成模型体系结构、子网络(操作)。然后对模型进行数据集培训,并将模型对验证数据的性能作为奖励。
[caption id="attachment_41623" align="aligncenter" width="824"]
控制器扮演代理人的角色,准确度作为奖励。[/caption]一般来说,递归神经网络(RNN)被视为控制器或代理。它生成字符串,模型是以随机字符串的形式构建的。
[caption id="attachment_41624" align="aligncenter" width="667"]
RNN生成的用于创建模型的字符串示例[/caption]例如,在图5中使用连续的RNN输出来构建滤波器; 从过滤器高度开始到跨距宽度。输出定位点用于指示跳过连接。在第N层,锚点将包含N - 1个基于内容的sigmoid,表示需要连接的前一层。
RNN的训练策略梯度法迭代更新政策θ。这里跳过了详细的计算。
渐进式神经结构搜索(PNAS)
PNAS执行单元格搜索,如本教程的搜索空间部分所述。它们从块构造单元格,并通过以预定义的方式添加单元格来构造完整的网络。
单元以预先定义的数字串联起来形成网络。每个细胞由若干块组成(原文中使用了5块)。
这些块由预先定义的操作组成。
[caption id="attachment_41630" align="aligncenter" width="796"]
块的结构。组合函数只是元素相加。[/caption]操作结果表明,图中所示为原论文所使用的图形,可以进行扩展。
在左侧,显示了一个完整的示例。即使在这个单元或微搜索中,也有10种有效的组合来检查以找到最佳的单元结构。
因此,为了降低复杂性,首先只构建只有1个块的单元。这很容易,因为在上述操作中,只有256个不同的单元是可能的。然后选择性能最好的前k个单元格展开为2个块单元格,最多重复5个块。
但是,对于一个合理的K,太多的2个街区的候选人培训。为了解决这个问题,我们训练了一个“廉价”的代理模型,它通过读取字符串(单元格被编码成字符串)来预测最终的性能。在构建、培训和验证单元时,将收集此培训的数据。
例如,我们可以构建所有256个单块单元,并测量它们的性能。并用这些数据训练代理模型。然后用这个模型来预测2个block cell的性能而不需要实际的训练和测试。当然,代理模型应该能够处理可变大小的输入。然后选择模型预测的表现最好的2个block cell top K。然后这两个块单元格被实际训练,“代理”模型被微调,这些单元格被扩展到3个块,并被迭代。
[caption id="attachment_41632" align="aligncenter" width="792"]
PNAS的步骤[/caption]微结构的搜索(DARTS)
神经架构的搜索空间是离散的,即一个架构与另一个架构至少有一个层或层中的一些参数不同,例如5x5过滤器与7x7过滤器。该方法将连续松弛法应用于离散搜索,实现了基于梯度的直接优化。
我们搜索的单元可以是一个有向无环图,其中每个节点x是一个潜在的表示(例如卷积网络中的特征图),每个有向边缘(i,j)与一些操作o(i,j)(卷积、最大池等)相关联,这些操作转换x(i),并在节点x(j)存储一个潜在的表示。
每个节点的输出可以用左边的公式计算。以这样的方式枚举节点,即从节点x(i)到x(j)有一条边(i,j),然后i
在连续松弛中,而不是在两个节点之间进行单一操作。使用每个可能操作的凸组合。为了在图中对此进行建模,将保留两个节点之间的多个边,每个边对应一个特定的操作。每个边也有一个重量α。
[caption id="attachment_41634" align="aligncenter" width="540"]
离散问题的连续松弛[/caption]现在o(i,j)节点x(i)和x(j)之间的操作是一组操作o(i,j)的凸组合,其中o(.)_s,其中s是所有可能操作的集合。
O(i,j)的输出由上面方程计算。
分别用l_train和l_val表示培训和验证损失。这两种损耗不仅取决于结构参数α,还取决于网络中的权重“w”。架构(architecture)搜索的目标是找到将验证损失L_val(w*,α*)最小化的α*,其中与架构相关的权重“w*”通过最小化培训损失获得。
w∗ = argmin L_train(w, α∗ ).
这意味着一个以α为上层变量,w为下层变量的双层优化问题:
α * = argmin L_val(w ∗ (α), α)
s.t. w ∗ (α) = argmin L_train(w, α)
训练后,某些边的α变得比其他边大得多。为了推导这个连续模型的离散结构,在两个节点之间,只保留具有最大权重的边。
a)边缘操作最初未知。b)通过在每个边上放置一个候选操作的混合物来对搜索空间进行连续松弛c)在双层优化过程中,一些权重增加,一些权重下降d)仅通过在两个节点之间取最大权重的边来构建最终架构。
当找到这些单元后,这些单元就被用来构建更大的网络。
本教程到此结束。这里有很多细节和方法我没有介绍,但是NAS已经成为一个非常活跃的领域,为了跟踪正在进行的工作,大家也可以访问 AutoML这个网站继续学习。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
数据科学特征选择方法入门








广告


写评论取消
回复取消