











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






对抗鲁棒分类器神经网络画风迁移
2019年07月03日 由 sunlei 发表
88009
0
我最近读了一篇有趣的文章,文章的题目是“对抗性的例子不是bug,而是特性”,这篇文章内容是关于一种截然不同的方式来看待对抗性的例子(1)。
作者提出了训练图像分类器的图像中存在所谓的“鲁棒”和“非鲁棒”特征。鲁棒的特征可以被认为是人类自然用于分类的特征,例如,下垂的耳朵表示某些品种的狗,而黑白条纹则表示斑马。另一方面,非鲁棒特性是指人类对此不敏感的特性(2),但真正表示某个特定的类(即它们与整个(列车和测试)数据集的类相关)。作者认为,相反的例子是通过用另一类的非鲁棒特性替换图像中的非鲁棒特性而产生的。
我强烈推荐阅读这篇论文,或者至少是随附的博客文章。
这篇论文中有一个让我特别感兴趣的图表,它显示了对抗性例子的可转移性与学习类似非鲁棒特性的能力之间的相关性。
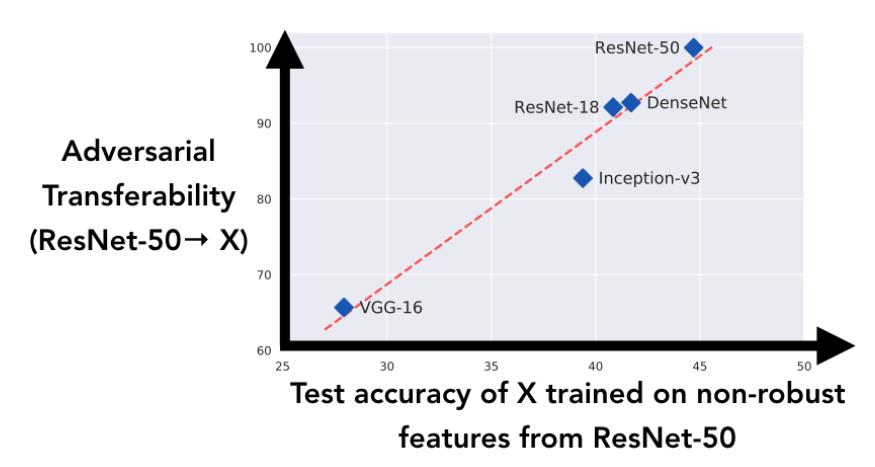
解释此图的一种方法是,它显示了特定架构如何能够很好地捕捉图像中的非鲁棒特性(3)。.
请注意VGG与其他模型相比有多早。
在不相关的神经风格传递领域,VGG也是非常特殊的,因为非VGG架构如果没有某种参数化技巧就不能很好地工作(4)。上图的解释为这一现象提供了另一种解释。由于VGG不能像其他架构一样捕获非健壮的特性,因此用于样式传输的输出对人类来说实际上看起来更正确(5)!
在继续之前,让我们快速讨论一下Mordvintsev等人在可微图像参数化中得到的结果,这些结果表明,非vgg架构可以用一种简单的技术进行风格转换。在他们的实验中,他们不是在RGB空间中对输出图像进行优化,而是在傅里叶空间中对其进行优化,并通过神经网络之前一系列的变换(例如抖动,旋转,缩放)来运行图像。
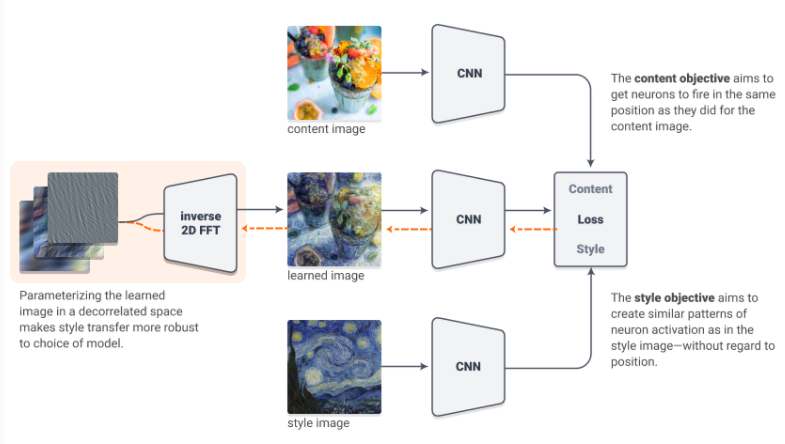
我们能将这一结果与我们的假设相协调吗?我们假设神经系统传递和非鲁棒性特征相关联。
一种可能的理论是,所有这些图像转换都会削弱甚至破坏非鲁棒特性。由于优化不再能够可靠地操纵非鲁棒特性来降低损失,因此它被强制使用鲁棒特性,这可能对应用的图像转换更具抵抗力(一只旋转的、抖动的、松弛的耳朵看起来仍然像一只松弛的耳朵)。
测试这个假设是相当简单的:使用一个对抗的鲁棒分类器进行(常规)神经风格的转移,看看会发生什么。
幸运的是,Engstrom等人为一个鲁棒resnet-50提供了他们的代码和模型权重,这省去了我自己训练的麻烦。我比较了正规训练(非鲁棒)的resnet-50和经过严格训练的resnet-50在gatys等原始神经风格转移算法上的性能。为了进行比较,我还使用常规的VGG-19执行了样式转换。
我的实验可以完全复制到这个colab笔记本里。为了确保公平比较,尽管不同的网络具有不同的最优超参数,我对每个图像执行了一个小的网格搜索,并手动选择每个网络的最佳输出。更多细节可在脚注6中阅读。
实验结果如下图所示。

成功!鲁棒的ResNet比常规的ResNet有较大的改进。记住,我们所做的只是切换ResNet的权重,其余用于执行样式转换的代码完全相同!
更有趣的比较可以在VGG-19和鲁棒ResNet之间进行。乍一看,鲁棒ResNet的输出似乎与VGG-19相当。然而,仔细观察,ResNet的输出似乎有噪音,并显示了一些工件(7)。

VGG和ResNet合成纹理的伪影比较。通过在图像周围悬停来进行交互。这个图是由Odena等人从反褶积和棋盘图中重新使用的。
目前还不清楚是什么导致了这些伪影。一种理论是,它们是由卷积层中不可分割的内核大小和步长造成的棋盘图伪影(Odena)。它们也可能是由于存在max池层(Henaff等)而造成的工件。无论在何种情况下,这些伪影虽然有问题,但似乎在很大程度上不同于对抗性鲁棒性在神经风格转换中解决的问题。
虽然本实验的开始是对VGG网的一个特殊特性的观察,但并没有对这一现象做出解释。事实上,如果我们接受这样的理论,即对抗性鲁棒性是VGG采用神经风格传输的开箱即用的原因,那么我们肯定会在现有的文献中发现一些迹象,表明VGG天生比其他架构更长大。
不幸的是,我找不到任何支持这一点的东西。
也许对抗性健壮性只是偶然地修复或掩盖了非VGG体系结构在样式转换(或其他类似算法8)时失败的真正原因,即对抗性健壮性是良好样式转换的充分但不必要的条件。不管是什么,我认为对VGG的进一步研究是未来工作的一个非常有趣的方向。
不可否认,我的小实验提出的问题可能比它回答的问题要多得多。除了弄清VGG的神秘之处,这里还有一些未来工作的想法:
如果你想建立在这个实验的基础上,所有的代码都可以在这个colab笔记本中找到。
如你认为这项工作有用,请将其引述如下:
作者提出了训练图像分类器的图像中存在所谓的“鲁棒”和“非鲁棒”特征。鲁棒的特征可以被认为是人类自然用于分类的特征,例如,下垂的耳朵表示某些品种的狗,而黑白条纹则表示斑马。另一方面,非鲁棒特性是指人类对此不敏感的特性(2),但真正表示某个特定的类(即它们与整个(列车和测试)数据集的类相关)。作者认为,相反的例子是通过用另一类的非鲁棒特性替换图像中的非鲁棒特性而产生的。
我强烈推荐阅读这篇论文,或者至少是随附的博客文章。
这篇论文中有一个让我特别感兴趣的图表,它显示了对抗性例子的可转移性与学习类似非鲁棒特性的能力之间的相关性。
解释此图的一种方法是,它显示了特定架构如何能够很好地捕捉图像中的非鲁棒特性(3)。.
请注意VGG与其他模型相比有多早。
在不相关的神经风格传递领域,VGG也是非常特殊的,因为非VGG架构如果没有某种参数化技巧就不能很好地工作(4)。上图的解释为这一现象提供了另一种解释。由于VGG不能像其他架构一样捕获非健壮的特性,因此用于样式传输的输出对人类来说实际上看起来更正确(5)!
在继续之前,让我们快速讨论一下Mordvintsev等人在可微图像参数化中得到的结果,这些结果表明,非vgg架构可以用一种简单的技术进行风格转换。在他们的实验中,他们不是在RGB空间中对输出图像进行优化,而是在傅里叶空间中对其进行优化,并通过神经网络之前一系列的变换(例如抖动,旋转,缩放)来运行图像。
我们能将这一结果与我们的假设相协调吗?我们假设神经系统传递和非鲁棒性特征相关联。
一种可能的理论是,所有这些图像转换都会削弱甚至破坏非鲁棒特性。由于优化不再能够可靠地操纵非鲁棒特性来降低损失,因此它被强制使用鲁棒特性,这可能对应用的图像转换更具抵抗力(一只旋转的、抖动的、松弛的耳朵看起来仍然像一只松弛的耳朵)。
测试这个假设是相当简单的:使用一个对抗的鲁棒分类器进行(常规)神经风格的转移,看看会发生什么。
一个快速的实验
幸运的是,Engstrom等人为一个鲁棒resnet-50提供了他们的代码和模型权重,这省去了我自己训练的麻烦。我比较了正规训练(非鲁棒)的resnet-50和经过严格训练的resnet-50在gatys等原始神经风格转移算法上的性能。为了进行比较,我还使用常规的VGG-19执行了样式转换。
我的实验可以完全复制到这个colab笔记本里。为了确保公平比较,尽管不同的网络具有不同的最优超参数,我对每个图像执行了一个小的网格搜索,并手动选择每个网络的最佳输出。更多细节可在脚注6中阅读。
实验结果如下图所示。
成功!鲁棒的ResNet比常规的ResNet有较大的改进。记住,我们所做的只是切换ResNet的权重,其余用于执行样式转换的代码完全相同!
更有趣的比较可以在VGG-19和鲁棒ResNet之间进行。乍一看,鲁棒ResNet的输出似乎与VGG-19相当。然而,仔细观察,ResNet的输出似乎有噪音,并显示了一些工件(7)。
VGG和ResNet合成纹理的伪影比较。通过在图像周围悬停来进行交互。这个图是由Odena等人从反褶积和棋盘图中重新使用的。
目前还不清楚是什么导致了这些伪影。一种理论是,它们是由卷积层中不可分割的内核大小和步长造成的棋盘图伪影(Odena)。它们也可能是由于存在max池层(Henaff等)而造成的工件。无论在何种情况下,这些伪影虽然有问题,但似乎在很大程度上不同于对抗性鲁棒性在神经风格转换中解决的问题。
VGG仍然是个谜
虽然本实验的开始是对VGG网的一个特殊特性的观察,但并没有对这一现象做出解释。事实上,如果我们接受这样的理论,即对抗性鲁棒性是VGG采用神经风格传输的开箱即用的原因,那么我们肯定会在现有的文献中发现一些迹象,表明VGG天生比其他架构更长大。
不幸的是,我找不到任何支持这一点的东西。
也许对抗性健壮性只是偶然地修复或掩盖了非VGG体系结构在样式转换(或其他类似算法8)时失败的真正原因,即对抗性健壮性是良好样式转换的充分但不必要的条件。不管是什么,我认为对VGG的进一步研究是未来工作的一个非常有趣的方向。
未来的工作
不可否认,我的小实验提出的问题可能比它回答的问题要多得多。除了弄清VGG的神秘之处,这里还有一些未来工作的想法:
- 找出鲁棒的ResNet构件的原因并尝试修复它们。这篇由Sahil Singla撰写的文章展示了一些很好的技巧。调整步长值,这样它就可以清楚地划分内核大小,这可能消除棋盘图伪影。用平均池层替换最大池层也可能有助于减少构件。您还可以尝试可微分图像参数化的技术,并结合鲁棒性应用图像转换和去相关参数化。
- 尝试使用超参数,特别是用于样式和内容的层。我在ResNet中坚持使用同一套图层,并没有在这方面做太多的探索。
- 据我所知,我从Engstrom等人只接受了9节课的限制性图片网训练。有趣的是,如果在完整的ImageNet数据集上训练一个鲁棒分类器,会产生更好的输出。
如果你想建立在这个实验的基础上,所有的代码都可以在这个colab笔记本中找到。
引用
如你认为这项工作有用,请将其引述如下:
@misc{nakano2019robuststyle,
title={Neural Style Transfer with Adversarially Robust Classifiers},
url={https://reiinakano.com/2019/06/21/robust-neural-style-transfer.html},
journal={https://reiinakano.com},
author={Reiichiro Nakano},
year={2019},
month={Jun}}文中注释:
- 对抗性示例是攻击者专门设计的输入,用来欺骗分类器为该输入生成不正确的标签。在深度学习文献中,有一个专门研究对抗攻击和防御的完整领域。
- 这通常被定义为在一些预定义的扰动集中,如L2球。人类不会注意到某些预定义的epsilon中单个像素的变化,所以这个集合中的任何扰动都可以用来创建一个对立的例子。
- 由于非鲁棒特性是由ResNet-50捕获的非鲁棒特性NRFresnetNRFresnet定义的,因此该图真正显示的是架构如何捕获NRFresnetNRFresnet。
- 这个现象将在Reddit的这个帖子中详细讨论。
- 为了遵循这一论点,请注意,神经风格转换中使用的知觉损失依赖于由单独训练的图像分类器学习的匹配特征。如果这些学习到的特性对人类没有意义(非鲁棒特性),那么用于神经类型转换的输出也没有意义。
- 采用L-BFGS算法进行优化,其收敛速度快于Adam算法。对于ResNet-50,使用的样式层是四个剩余块[relu2_x,relu3_x,relu4_x,relu5_x]后的ReLu输出,而使用的内容层是relu4_xrelu4_x。对于vgr -19,样式层[relu1_1,relu2_1,relu3_1,relu4_1,relu5_1]与内容层relu4_2relu4_2一起使用。在VGG-19, max pooling层替换为avg pooling层,正如Gatys等人在原始论文中所做的那样。
- 当输出图像不是用内容图像初始化,而是用高斯噪声初始化时,这一点更加明显。
- 事实上,神经风格转移并不是唯一一种预先训练的基于分类器的迭代图像优化技术。在Engstrom等人最近发表的一篇论文中,他们指出,通过激活最大化实现的特征可视化可以在健壮的分类器上工作,而不需要执行以前工作中使用的任何先验或正则化(例如图像转换和去相关参数化)。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消