











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






自然语言处理:从基础到RNN和LSTM(上)
2019年07月10日 由 sunlei 发表
872330
0
机器学习领域最引人入胜的进步之一,是培养机器理解人类交流的能力。机器学习的这一部分被称为自然语言处理。
这篇文章试图解释自然语言处理的基本原理,以及随着深度学习和神经网络的发展,自然语言处理取得了怎样的快速进展。
在我们深入研究这个问题之前,有必要了解一些基础知识。
一种语言,基本上是一个固定的词汇表,是由人类社会共享的,用来表达和交流他们的思想。
这个词汇作为人类成长过程的一部分被教授给人类,并且大部分保持不变,每年只增加很少的新词汇。
词典等复杂的资源得到了维护,因此,如果一个人遇到一个新词,他或她可以参考词典了解其含义。一旦人们接触到这个词,它就会被添加到他或她的词汇表中,可以用于进一步的交流。
计算机是在数学规则下工作的机器。它缺乏人类可以轻松做到的复杂解释和理解,但可以在几秒钟内完成复杂的计算。
计算机要处理任何概念,都必须有一种方法以数学模型的形式表达这些概念。
这种限制极大地限制了计算机可以使用的自然语言的范围和领域。到目前为止,机器在执行分类和翻译任务方面非常成功。
分类基本上是将一段文本分类为一个类别,而翻译则是将这段文本转换成任何其他语言。
自然语言处理,简称NLP,被广泛地定义为通过软件对自然语言(如语音和文本)的自动操作。
自然语言处理的研究已经有50多年的历史了,它是随着计算机的兴起而从语言学领域发展起来的。
如前所述,机器要理解自然语言(人类使用的语言),需要将其转换成某种可以建模的数学框架。下面提到的是帮助我们实现这一目标的一些最常用的技术。
标记化技术是将文本分解为单词的过程。标记化技术可以发生在任何字符上,但是最常见的标记化技术方法是在空间字符上进行标记化。
词干截断是一种截断词尾以获得基本单词的粗糙方法,通常包括去掉派生词缀。派生词缀是指一个词由另一个词形成(派生)的词缀。派生词通常与原始词属于不同的词类。最常用的算法是波特算法。
词元化是对一个词进行词汇和形态学分析,通常只是为了去除词尾的屈折变化。屈折结尾是一组字母加在单词的末尾以改变其含义。一些屈折词尾是 -s. bat. bats.。
由于词干分析是基于一组规则发生的,词干分析返回的根词可能并不总是英语中的一个单词。另一方面,词素化适当减少词形变化,确保词根属于英语。
N-grams是指为了表示目的而将相邻的单词组合在一起的过程,其中N表示要组合在一起的单词数量。
例如,考虑一句话,“自然语言处理对计算机科学至关重要。”
一个1-gram或unigram模型将句子标记为一个单词组合,因此输出将是“自然的、语言的、处理的、对计算机、科学来说是必不可少的”。
另一方面,一个bigram模型将把它标记为两个单词的组合,输出将是“自然语言,语言处理,处理对于对计算机,对计算机科学是必不可少的。”
同样,三元模型将其分解为“自然语言处理,语言处理是,处理是必不可少的,对计算机是必不可少的,对计算机科学是必不可少的”,而n-gram模型将一个句子标记为n个单词的组合。
将一种自然语言分解成n-grams对于保持句子中出现的单词数量至关重要,而句子是自然语言处理中传统数学过程的支柱。
最常用的一种方法是tf-idf,它可以用大量的单词来表示
TF-IDF是一种对词汇进行评分的方法,目的是根据单词对句子含义的影响程度,为单词提供足够的权重。这个分数是两个独立的分数的乘积,term frequency(tf)和reverse document frequency(idf)

Term Frequency词频(TF):词频定义为当前文档中单词的频率。
逆文本频率(IDF):衡量一个单词提供了多少信息,即,如果它在所有文档中都是常见的或罕见的。计算方法为log (N/d),其中N为文档总数,d为出现该单词的文档数量。
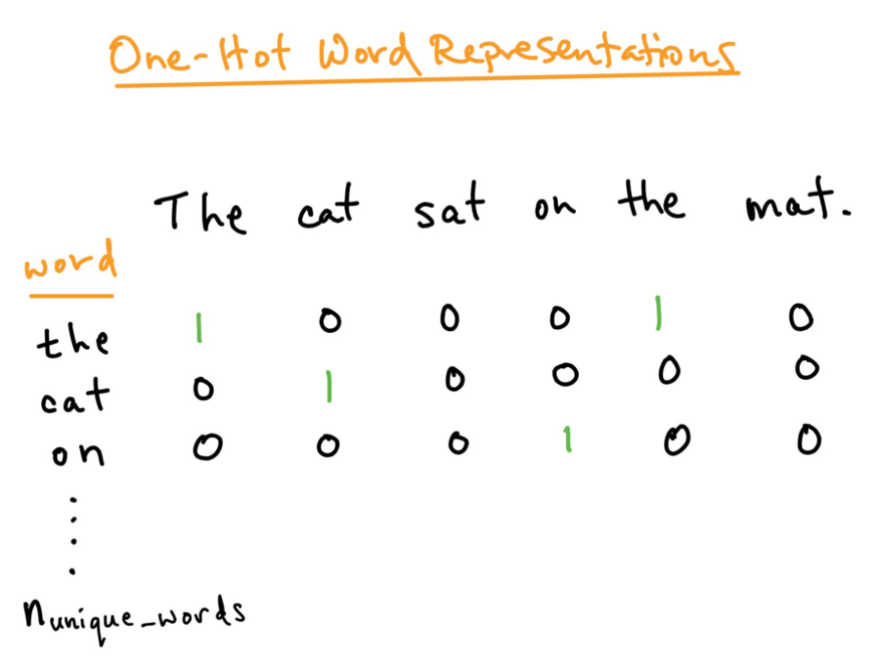
独热编码是以数字形式表示单词的另一种方式。词向量的长度等于词汇的长度,每个观察值由一个矩阵表示,其中行等于词汇的长度,列等于观察值的长度,值为1,当词汇表中的单词出现在观察中,当它不出现时,值为零。
单词嵌入是一组语言建模和特征学习技术的总称,其中词汇表中的单词或短语映射到实数向量。该技术主要用于神经网络模型。
从概念上讲,它涉及到将一个单词从一个与词汇表长度相等的维度投射到一个较低的维度空间,其思想是相似的单词将彼此投射得更近。
为了便于理解,我们可以将嵌入看作是将每个单词投射到一个具有特征的空间,如下图所示。
[caption id="attachment_41926" align="aligncenter" width="880"] 每一个词都代表一个特征空间(性别、皇室、年龄、食物)等。[/caption]
每一个词都代表一个特征空间(性别、皇室、年龄、食物)等。[/caption]
然而,事实上,这些维度并不是那么清晰或容易理解。这与算法训练维度之间的数学关系时的问题不一致。从训练和预测的角度看,用维数表示的神经网络是没有意义的。
如果你有兴趣直观地了解线性代数、投影和变换,这是许多机器学习算法背后的核心数学原理,请看下面的视频由3blue1brown制作的“线性代数本质”。
[playlist type="video" ids="41929"]
好了,视频虽然只有10分钟的时间,但是需要你用更多的时间去消化理解,所以我们今天先说到这里,期待明天和你再次相遇。
这篇文章试图解释自然语言处理的基本原理,以及随着深度学习和神经网络的发展,自然语言处理取得了怎样的快速进展。
在我们深入研究这个问题之前,有必要了解一些基础知识。
语言是什么?
一种语言,基本上是一个固定的词汇表,是由人类社会共享的,用来表达和交流他们的思想。
这个词汇作为人类成长过程的一部分被教授给人类,并且大部分保持不变,每年只增加很少的新词汇。
词典等复杂的资源得到了维护,因此,如果一个人遇到一个新词,他或她可以参考词典了解其含义。一旦人们接触到这个词,它就会被添加到他或她的词汇表中,可以用于进一步的交流。
计算机如何理解语言?
计算机是在数学规则下工作的机器。它缺乏人类可以轻松做到的复杂解释和理解,但可以在几秒钟内完成复杂的计算。
计算机要处理任何概念,都必须有一种方法以数学模型的形式表达这些概念。
这种限制极大地限制了计算机可以使用的自然语言的范围和领域。到目前为止,机器在执行分类和翻译任务方面非常成功。
分类基本上是将一段文本分类为一个类别,而翻译则是将这段文本转换成任何其他语言。
什么是自然语言处理?
自然语言处理,简称NLP,被广泛地定义为通过软件对自然语言(如语音和文本)的自动操作。
自然语言处理的研究已经有50多年的历史了,它是随着计算机的兴起而从语言学领域发展起来的。
基本的转换
如前所述,机器要理解自然语言(人类使用的语言),需要将其转换成某种可以建模的数学框架。下面提到的是帮助我们实现这一目标的一些最常用的技术。
标记化技术、词干化和词首分离技术
标记化技术是将文本分解为单词的过程。标记化技术可以发生在任何字符上,但是最常见的标记化技术方法是在空间字符上进行标记化。
词干截断是一种截断词尾以获得基本单词的粗糙方法,通常包括去掉派生词缀。派生词缀是指一个词由另一个词形成(派生)的词缀。派生词通常与原始词属于不同的词类。最常用的算法是波特算法。
词元化是对一个词进行词汇和形态学分析,通常只是为了去除词尾的屈折变化。屈折结尾是一组字母加在单词的末尾以改变其含义。一些屈折词尾是 -s. bat. bats.。
由于词干分析是基于一组规则发生的,词干分析返回的根词可能并不总是英语中的一个单词。另一方面,词素化适当减少词形变化,确保词根属于英语。
N-Grams
N-grams是指为了表示目的而将相邻的单词组合在一起的过程,其中N表示要组合在一起的单词数量。
例如,考虑一句话,“自然语言处理对计算机科学至关重要。”
一个1-gram或unigram模型将句子标记为一个单词组合,因此输出将是“自然的、语言的、处理的、对计算机、科学来说是必不可少的”。
另一方面,一个bigram模型将把它标记为两个单词的组合,输出将是“自然语言,语言处理,处理对于对计算机,对计算机科学是必不可少的。”
同样,三元模型将其分解为“自然语言处理,语言处理是,处理是必不可少的,对计算机是必不可少的,对计算机科学是必不可少的”,而n-gram模型将一个句子标记为n个单词的组合。
将一种自然语言分解成n-grams对于保持句子中出现的单词数量至关重要,而句子是自然语言处理中传统数学过程的支柱。
转换方法
最常用的一种方法是tf-idf,它可以用大量的单词来表示
TF-IDF
TF-IDF是一种对词汇进行评分的方法,目的是根据单词对句子含义的影响程度,为单词提供足够的权重。这个分数是两个独立的分数的乘积,term frequency(tf)和reverse document frequency(idf)
Term Frequency词频(TF):词频定义为当前文档中单词的频率。
逆文本频率(IDF):衡量一个单词提供了多少信息,即,如果它在所有文档中都是常见的或罕见的。计算方法为log (N/d),其中N为文档总数,d为出现该单词的文档数量。
独热编码
独热编码是以数字形式表示单词的另一种方式。词向量的长度等于词汇的长度,每个观察值由一个矩阵表示,其中行等于词汇的长度,列等于观察值的长度,值为1,当词汇表中的单词出现在观察中,当它不出现时,值为零。
单词嵌入
单词嵌入是一组语言建模和特征学习技术的总称,其中词汇表中的单词或短语映射到实数向量。该技术主要用于神经网络模型。
从概念上讲,它涉及到将一个单词从一个与词汇表长度相等的维度投射到一个较低的维度空间,其思想是相似的单词将彼此投射得更近。
为了便于理解,我们可以将嵌入看作是将每个单词投射到一个具有特征的空间,如下图所示。
[caption id="attachment_41926" align="aligncenter" width="880"]
每一个词都代表一个特征空间(性别、皇室、年龄、食物)等。[/caption]然而,事实上,这些维度并不是那么清晰或容易理解。这与算法训练维度之间的数学关系时的问题不一致。从训练和预测的角度看,用维数表示的神经网络是没有意义的。
如果你有兴趣直观地了解线性代数、投影和变换,这是许多机器学习算法背后的核心数学原理,请看下面的视频由3blue1brown制作的“线性代数本质”。
[playlist type="video" ids="41929"]
好了,视频虽然只有10分钟的时间,但是需要你用更多的时间去消化理解,所以我们今天先说到这里,期待明天和你再次相遇。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消