











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Lyft如何打造营销自动化平台
2019年07月13日 由 sunlei 发表
271094
0
我们这样一群人——用世界上最好的交通工具改善人们的生活,我们为我们的使命感到自豪。在美国和加拿大,每月都会有超过5000万辆碳中和的Lyft游乐设施出现,而我们还几乎没有触及到潜在的共享空间。
我们增长的一部分是在我们的收购过程中进行改进,比如开展特定地区的广告活动,提高知名度,并考虑我们的多模式产品。协调这些活动以大规模获取新用户已经变得非常耗时,这导致我们面临自动化的挑战。
增长收购
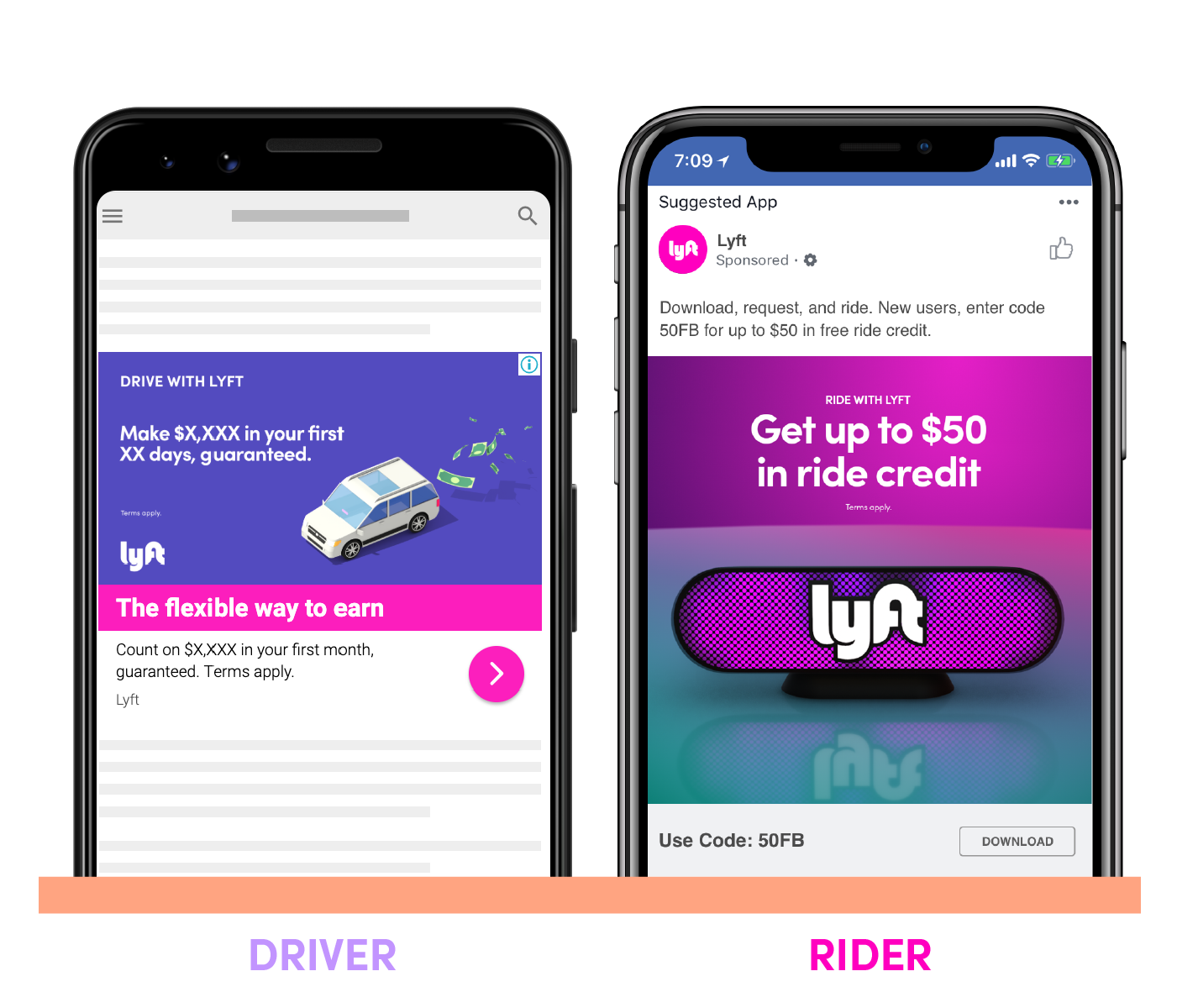
收购通常由一个数据驱动的跨职能团队领导,该团队专注于规模、可测量性和可预测性。你可能看到过这样的Lyft广告:
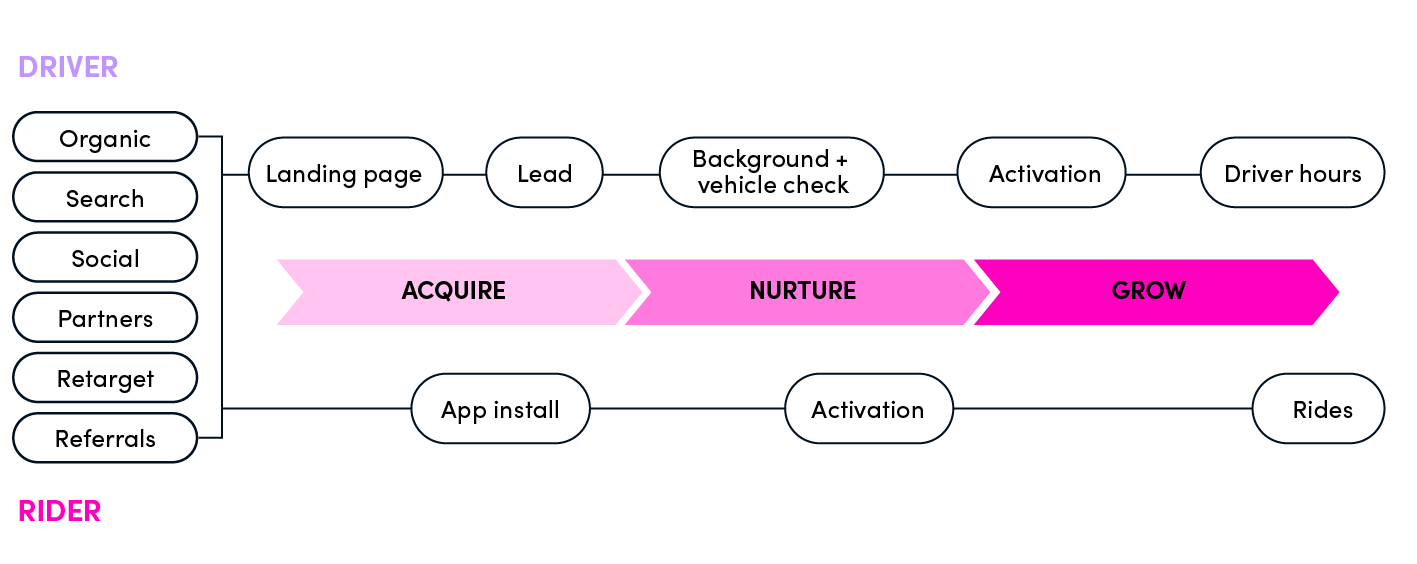
通过左侧列出的各种渠道,收购在入职漏斗的顶部和最大部分进行。没有两个渠道是平等的:我们与不同的合作伙伴、技术和战略合作,以确保Lyft是消费者的首选。Lyft的其他团队专注于用户旅程的不同部分,以提供世界级的体验。下面显示了一个高级视图。
动机
在Lyft运营的每个地区,大规模获取用户意味着每天要做出数千个决定:选择投标、预算、创意、激励和受众;运行测试;和更多。仅仅是跟上这些重复的任务就占据了营销人员大量的注意力,并可能导致次优决策。这对企业来说是昂贵的,而且不具规模。
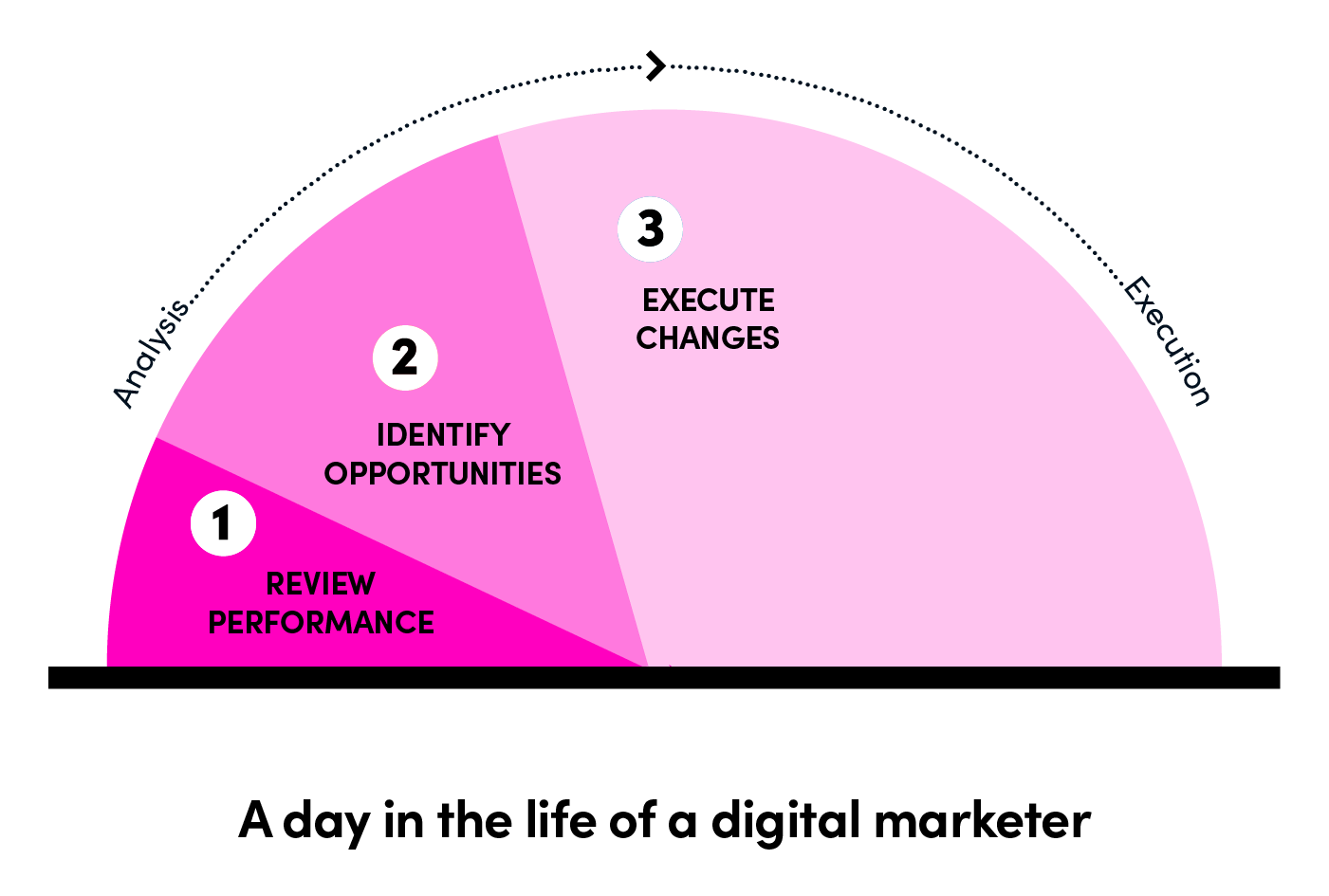
通过自动化日常决策,我们可以有效地扩展并创建一个数据驱动的学习系统。这也让营销人员专注于创新和实验,而不是经营活动。
自动化之路
我们的目标:建立一个营销自动化平台,以提高成本和数量效率,同时使我们的营销团队能够进行更复杂、更具影响力的实验。
要求:
- 能够预测新用户参与我们产品的可能性。
- 衡量机制,以分配我们的营销预算在不同的内部和外部渠道。
- 在数千个广告活动中部署这些预算的杠杆。
营销业绩数据有助于形成一个反馈回路,不断滋养强化学习系统。
下面是我们需要自动化的问题的例子:
- 在数千个搜索关键字中更新出价。
- 关闭表现不佳的显示器。
- 按市场改变转介价值。
- 识别高价值用户段。
- 跨活动分享不同策略的学习成果。
因此,我们创建了Symphony——一个业务目标、预测未来用户价值、分配预算并发布预算以吸引新用户使用Lyft的编制系统。
体系结构
Symphony体系结构由三个主要组件组成:生命周期价值(LTV)预测器、预算分配器和投标人。
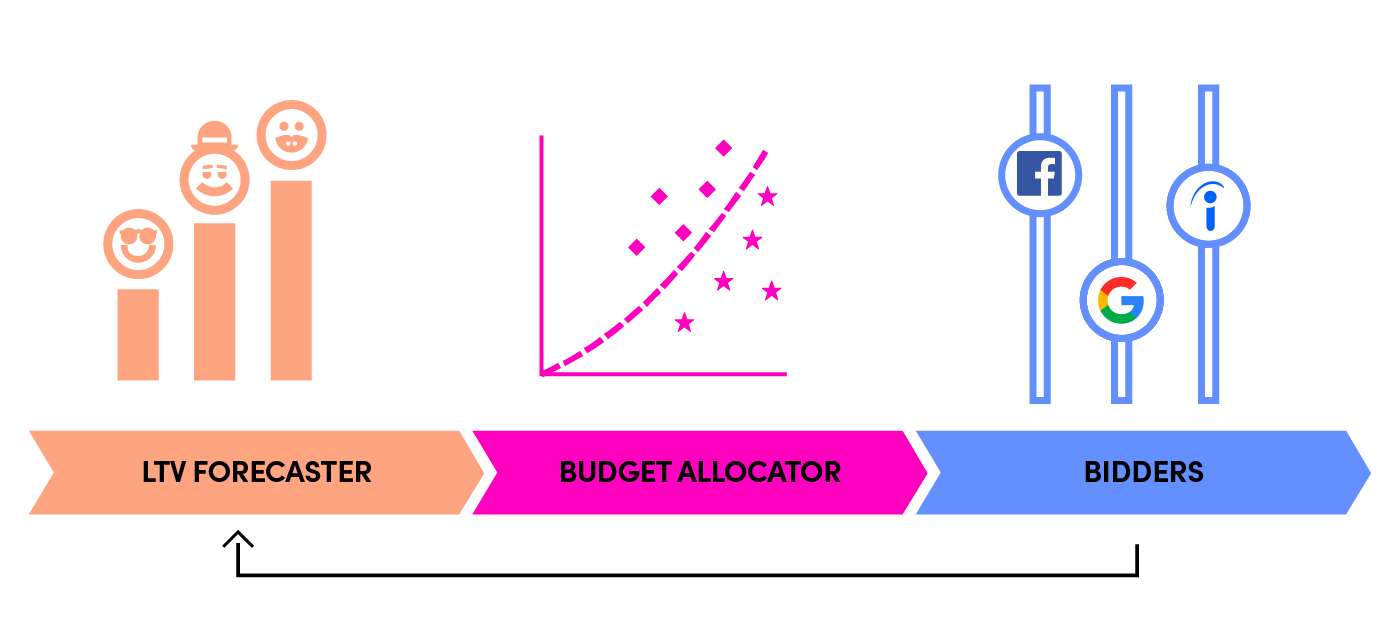

我们的技术栈包括Apache Hive、Presto、一个内部机器学习(ML)平台、streams和第三方api。一个轻前端feed在业务目标和启动创意。体系结构有很多可移动的部分和依赖项,需要严格的日志记录和监视。我们深入研究下面的每个组件。
生命周期价值(LTV)预测器
了解用户的潜在价值对每个企业都至关重要。该组件的目标是基于来自这些渠道的用户的价值来衡量各种获取渠道的效率。然后,预算可以根据来自给定渠道的用户的预期价值和我们愿意在特定地区为这些类型的用户支付的价格来分配预算。
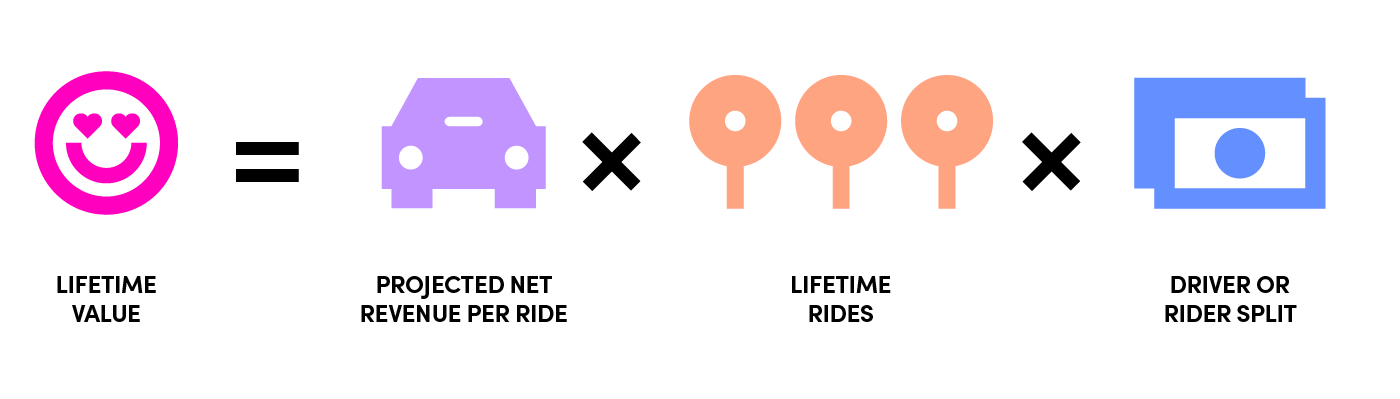
上面的图表在高层次上描述了我们如何计算用户的预期LTV,同时考虑到双向市场中的供求关系。我们尽力准确地预测LTV,因为它帮助我们设定中长期战略目标。
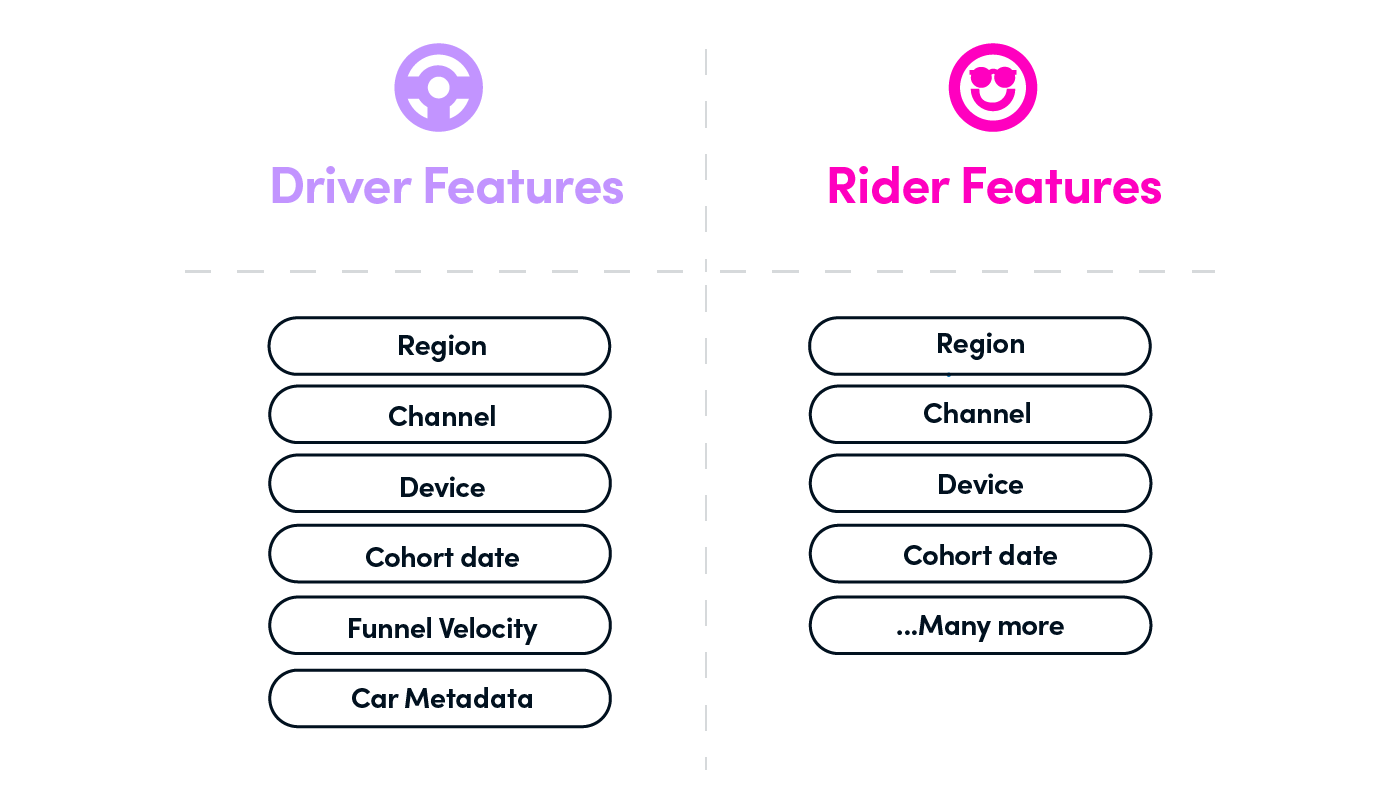
在用户生命周期的早期,很难了解它们的保留、运行或事务值,因此,我们不是直接测量LTV,而是根据历史数据进行预测。随着用户与我们的服务交互,预测会有所改善。
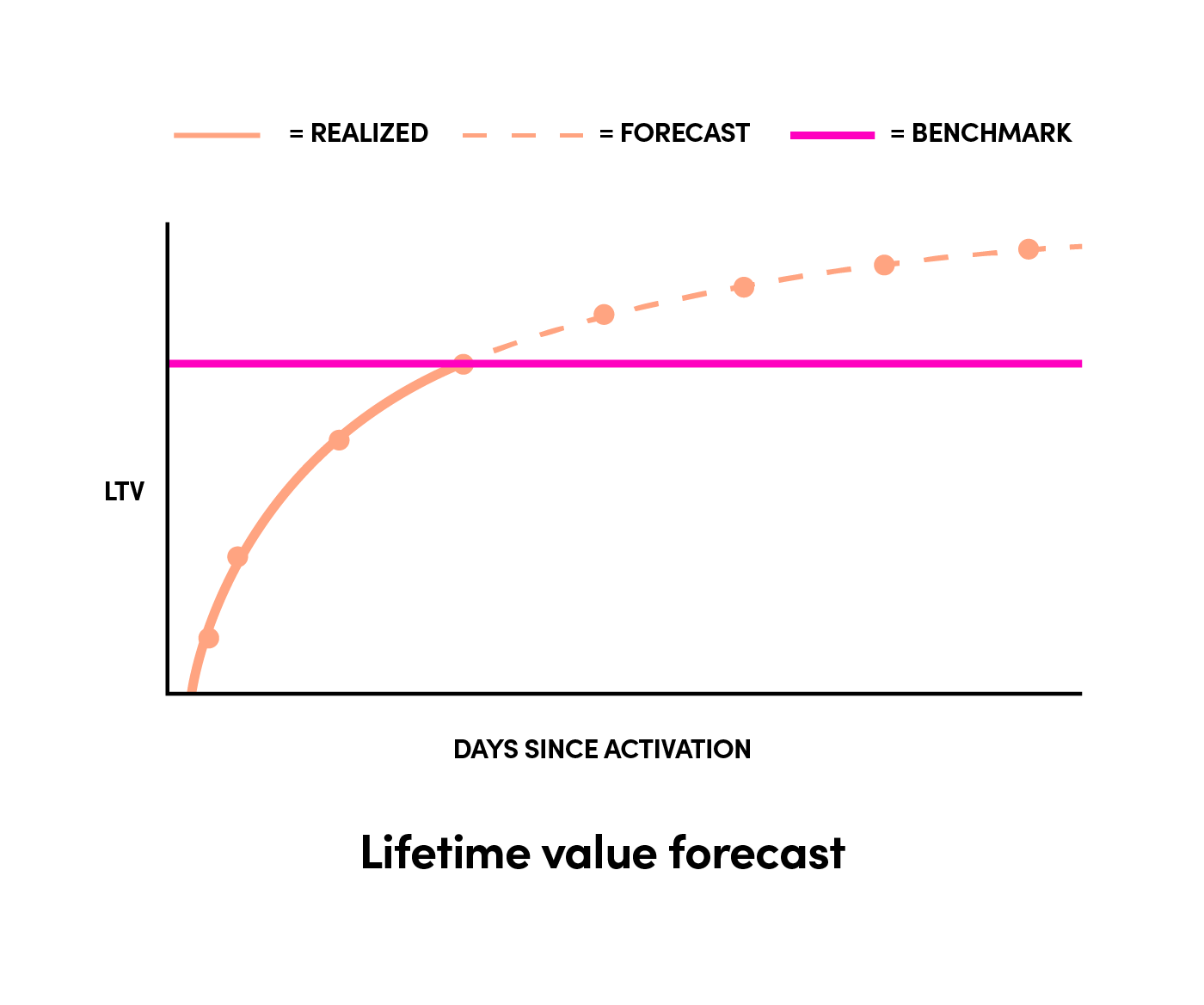
这里的基准表示一组用户的平均预期LTV。这些预测提供给预算分配程序,并帮助它决定来自一组特定活动的用户的价值。
预算分配器
预算分配器结合LTV预测收集营销业绩数据。预算分配是使用马尔可夫链蒙特卡罗(汤普森抽样)完成的。假设a&b来自具有自身参数的分布(例如a来自具有平均μa和标准偏差a的分布),则LTV=a*(spend)^b形式的曲线适合数据。这里有一个技巧——我们不会像在标准回归中那样直接估计a&b。相反,我们估计的参数分布:(μaa) &(μbb)。因此,我们不是画一条固定的a & b曲线,而是每天从这些分布中抽取不同的a & b估计值作为样本——自然地在成本曲线创建过程中注入一定程度的随机性。
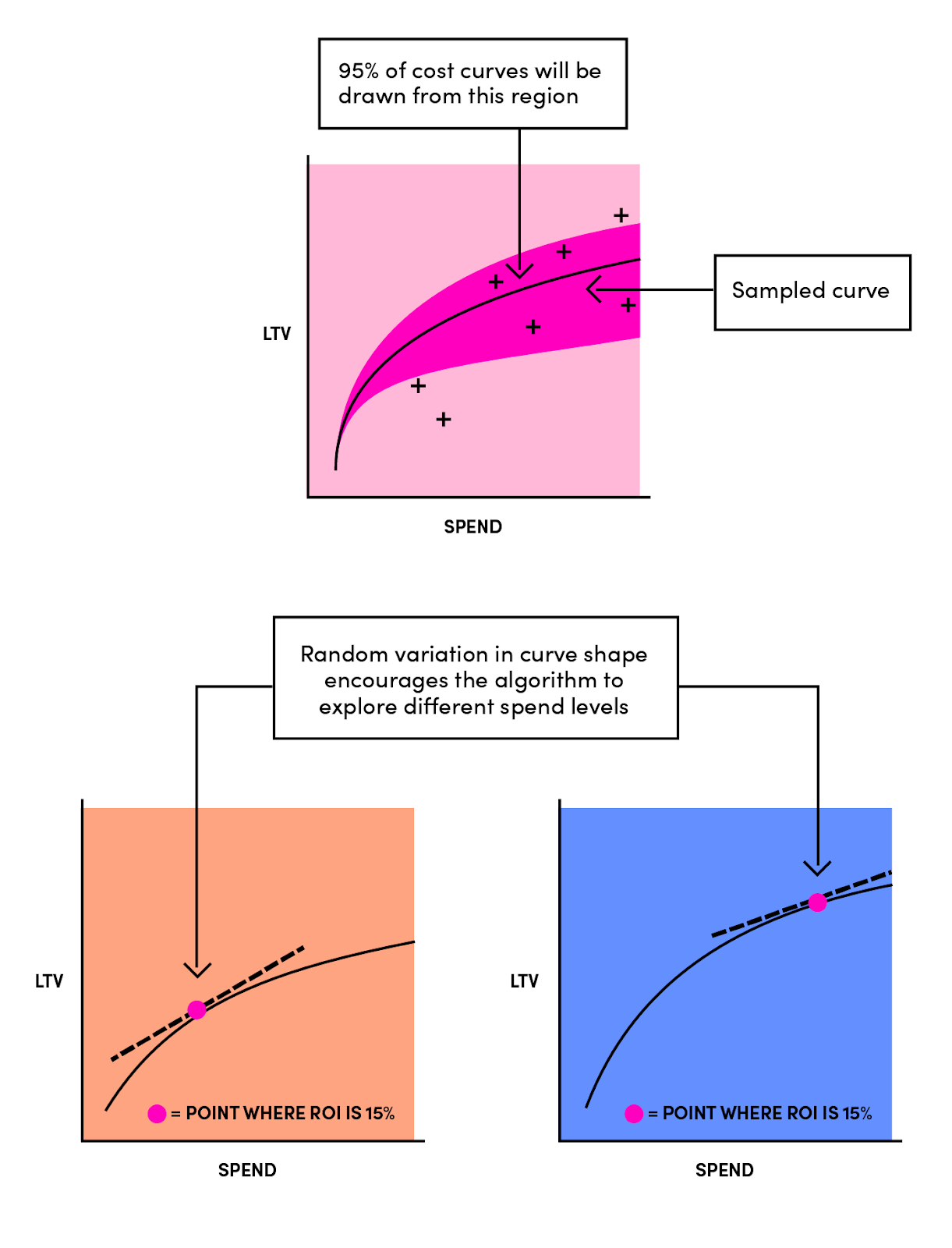
这种类型的随机搜索可能看起来很浪费,但从长远来看,适度的探索实际上是最优的。它帮助我们探索曲线中我们通常不会考虑收敛到全局最优的点。
预算分配器将每个活动的分配发送给各自的渠道投标人进行部署。
投标人
投标人公布在目标价格点为广告服务所需的最终变更。投标人由两部分组成-调谐器和演员。调谐器决定如何根据可用的杠杆(如关键字、标题、价值、谷歌搜索的出价类型)来部署资金,同时考虑特定于频道的上下文。参与者通过API集成将实际投标信息传达给内部和外部渠道,如工作板、搜索、显示、社交和推荐。
多年来,我们与合作伙伴建立了关系,他们帮助我们的产品在正确的受众面前销售。每个渠道根据其成熟程度支持不同的投标策略。下面列出了一些流行的策略。

我们不断尝试用正确的策略来确定每一个竞选活动的出价,并在不断变化的数字媒体环境中更新节奏。
投标人包含许多特定于渠道的细微差别,有助于他们做出最佳决策。投标人也有一定程度的近期加权和季节性因素,以反映市场的波动性。
结论
Lyft营销自动化的长期成功依赖于将人类反馈融入我们的机器学习平台。这通常被称为“人在循环”的机器学习,它使机器能够处理自动广度的问题,同时使人类操作员能够专注于与知识相关的问题。没有来自驱动自动化引擎的人员的良好输入,模型的质量将受到影响(“垃圾输入,垃圾输出”)。
没有人工更新投标或分配预算的认知开销,我们期望我们的营销团队更灵活地将受众和创造性的变化应用到活动中。他们有更多的时间和精力:
- 了解我们的用户和他们的兴趣
- 构思新的广告格式,信息和渠道
- 形成关于目标的重大假设
对于Symphony的持续迭代,我们有许多令人兴奋的想法:
不间断实验
- 结合季节影响,如天气和一天的时间
- 更好的市场环境,以通知我们的投标人
- 智能分割与个性化
凭借Symphony,我们在节省营销人员时间的同时,实现了更高的投资回报。该系统为超过3000万名乘客和近200万名驾驶员(基于2018年的数据)的不断增长的生态系统提供动力。市场营销自动化在Lyft仍处于萌芽阶段,尽管这些方法已经帮助我们扩展到目前为止,我们将继续学习和改进,随着我们的发展。我们对我们光明的机器学习和实验驱动的未来感到兴奋。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消