











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






是时候展现真正的技术了!——用深度学习实时克隆别人的声音
2019年07月14日 由 sunlei 发表
354321
0
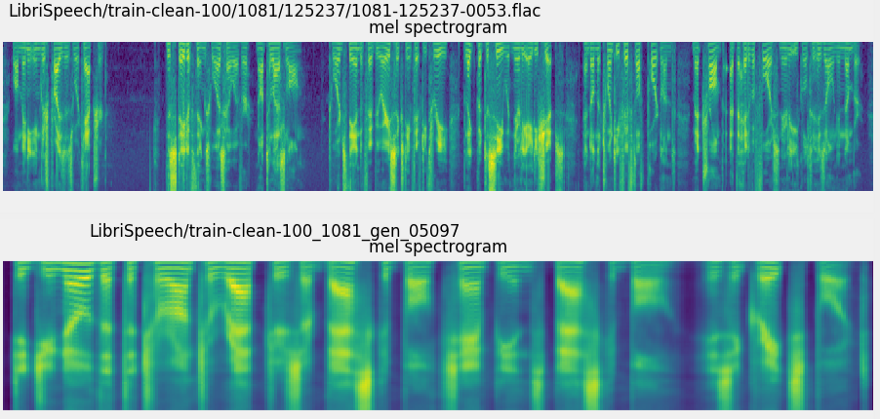
文本到语音(TTS)合成是指文本到音频的人工转换。人类通过阅读来完成这项任务。一个好的TTS系统的目标是让计算机自动完成。
在创建这样一个系统时,一个非常有趣的选择是为生成的音频选择哪个声音。应该是男人还是女人?声音是大还是小?
在进行深度学习的TTS时,这是一个限制。您必须收集文本-语音对的数据集。录制这个语音的演讲者是固定的——你不可能有无数的演讲者!
所以,如果你想为自己或他人的声音创建音频,唯一的方法就是收集一个全新的数据集。
这时我们熟悉的谷歌(Google)又出现了,来自谷歌的研究绰号“语音克隆”(Voice Cloning)人工智能,它使计算机可以用任何声音大声读出信息。
语音克隆的工作原理
很明显,为了让计算机能够大声读出任何声音,它需要以某种方式理解两件事:它读的是什么以及它是如何读的。
因此,谷歌研究人员设计的语音克隆系统有两个输入:我们想要读取的文本和我们想要读取文本的语音样本。
例如,如果我们想让蝙蝠侠读“我爱披萨”这句话,那么我们会给系统两件事:写着“我爱披萨”的文字和一小段蝙蝠侠的声音样本,这样它就知道蝙蝠侠的声音应该是什么样的。输出应该是蝙蝠侠说“我爱披萨”的声音!
从技术上看,系统可分为三个顺序组件:
(1) 给我们想要使用的声音的一个小的音频样本,将声音波形编码成一个固定的维矢量表示。
(2)给定一段文本,也把它编码成矢量表示。将语音和文本这两个载体结合起来,将它们解码成光谱图。
(3)使用声码器将声谱图转换成我们可以听到的音频波形。
[caption id="attachment_42010" align="aligncenter" width="791"]
 系统的简化版本[/caption]
系统的简化版本[/caption]本文对这三个部分分别进行了训练。
近年来,文本-语音转换系统在深度学习领域得到了广泛的研究关注。事实上,基于深度学习,有很多针对文本到语音的解决方案都非常有效。
这里的关键是,系统能够将说话者编码器从语音中学到的“知识”应用到文本中。
分别编码后,将语音和文本组合在一个公共的嵌入空间中,然后进行解码,生成最终的输出波形。
克隆语音代码
多亏了人工智能社区中开放源码思想的美妙之处,在这里有一个公开可用的语音克隆实现!你可以这样使用它。
首先克隆存储库。
git clone https://github.com/CorentinJ/Real-Time-Voice-Cloning.git
安装所需的库。一定要使用python 3:
pip3 install -r requirements.txt
在README文件中,您还可以找到下载预培训模型和数据集的链接,以试用一些示例。
最后,您可以运行以下命令打开GUI:
python demo_toolbox.py -d
下面是我的照片。
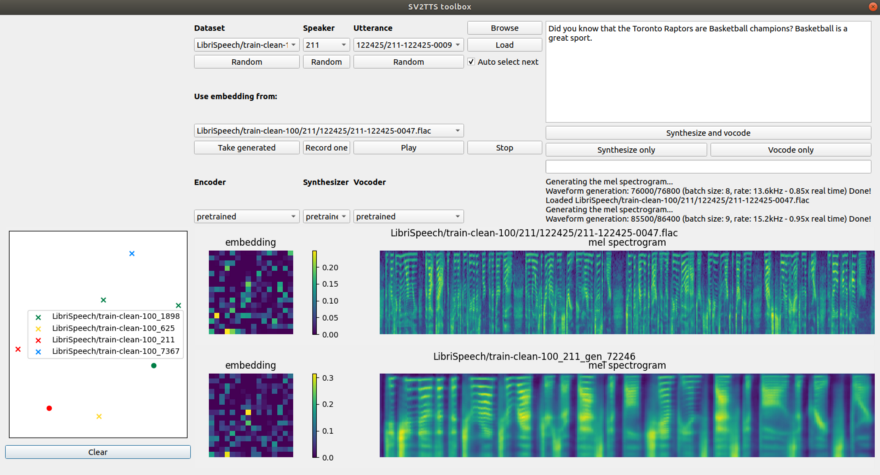
正如你所看到的,我把我希望电脑在右边阅读的文字设置为:“你知道多伦多猛龙队是篮球冠军吗?”篮球是一项伟大的运动。”
您可以点击每个部分下面的“Random”(随机)按钮来随机化语音输入,然后点击“Load”(加载)将语音输入加载到系统中。
Dataset选择要从中选择语音样本的数据集,Speaker选择说话的人,Utterance选择输入语音所说的短语。要听输入声音的声音,只需点击“播放”。
一旦你按下“合成和vocode”按钮,算法就会运行。一旦完成,你将在这里输入扬声器朗读你的文本。
你甚至可以录制你自己的声音作为输入,但点击“录制一”按钮,这是非常有趣的玩法!
如果你想了解更多关于这个算法的工作原理,你可以阅读谷歌的官方NIPS论文。这里还有一些音频样本结果。我将高度克隆存储库,并尝试一下这个很棒的系统!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
Lyft如何打造营销自动化平台








广告


写评论取消
回复取消