











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






机器学习算法只需很少的训练即可发现隐藏的科学知识
2019年07月15日 由 Aaron 发表
790976
0
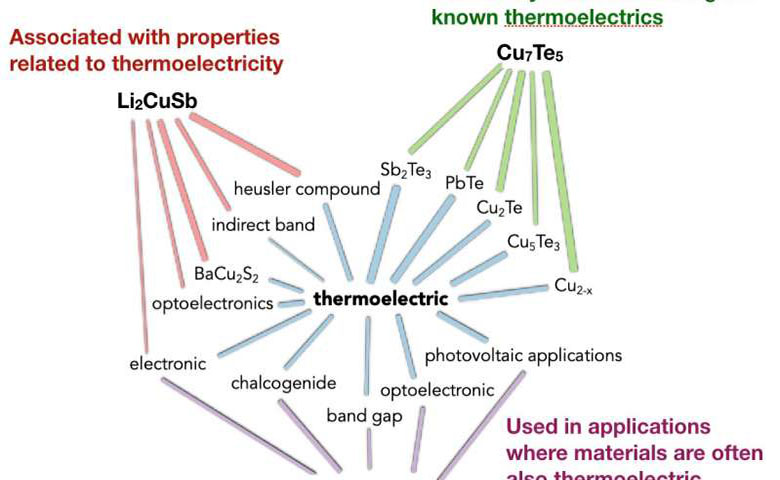 算法可以做出科学发现吗?美国能源部劳伦斯伯克利国家实验室(伯克利实验室)的研究人员表明,一种未经材料科学训练的算法可以扫描数百万篇论文的文本并发现新的科学知识。
算法可以做出科学发现吗?美国能源部劳伦斯伯克利国家实验室(伯克利实验室)的研究人员表明,一种未经材料科学训练的算法可以扫描数百万篇论文的文本并发现新的科学知识。由Anubhav Jain领导的团队收集了330万份已发表的材料科学论文摘要,并将其输入一个名为Word2vec的算法中。通过分析单词之间的关系,该算法能够提前几年预测新热电材料的发现,并提出目前未知的材料作为热电材料的候选材料。
“没有告诉任何有关材料科学的知识,它就学会了周期表和金属晶体结构等概念,”Jain说,“这暗示了该技术的潜力。但也许我们发现的最有趣的事情是,你可以用这个算法来解决材料研究的空白,人们应该研究但还没有研究到的东西。”
该研究结果发表在Nature上。该研究的主要作者,Vahe Tshitoyan,现在在谷歌工作,与Jain一起,伯克利实验室的科学家Kristin Persson和Gerbrand Ceder帮助领导了这项研究。
“该文件确定科学文献的文本挖掘可以发现隐藏的知识,纯文本提取可以建立基本的科学知识,”Ceder说,他还在加州大学伯克利分校的材料科学与工程系任命。
“这篇论文证明,科学文献的文本挖掘可以揭示隐藏的知识,而纯文本提取可以建立基本的科学知识,”Ceder表示。
Tshitoyan表示,该项目的动机是处理难以理解大量已发表的研究。“在每个研究领域都有至少100年的研究文献,每周都有数十项新研究出现,研究人员只能访问其中的一小部分。那么机器学习能够在不需要人类研究人员指导的情况下,以一种无监督的方式利用所有这些集体知识吗?”
国王-女王+男人=?
该团队从1922年至2018年间在1000多种期刊上发表的论文中收集了330万篇摘要,Word2vec在这些摘要中采用了大约50万个不同的单词,并将每个单词转换为200维向量,或200个数字的数组。
“重要的不是每个数字,而是用数字来看看单词是如何相互关联的,例如,你可以使用标准向量数学来减去向量。其他研究人员已经证明,如果在非科学文本源上训练算法并采用“国王-女王”的结果,那么你得到的结果与“男人-女人”相同。它不用你告诉它任何事情就能搞清楚其间的关系。”
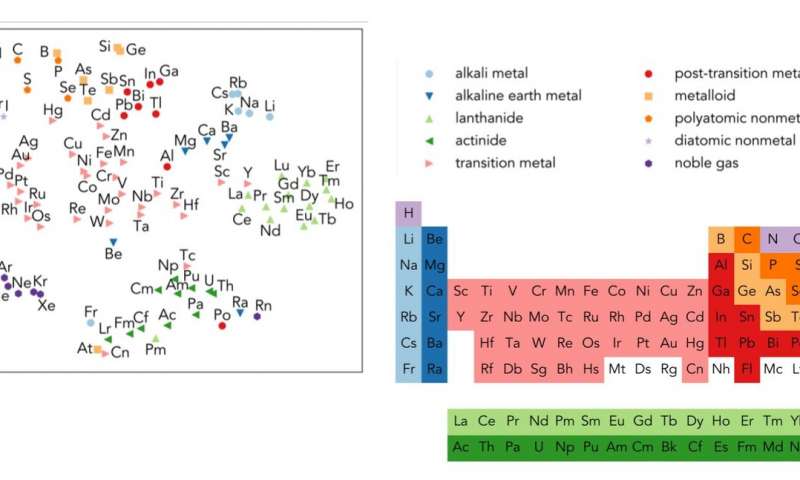 类似地,当在材料科学文本上进行训练时,该算法能够简单地基于摘要中的单词的位置以及它们与其他单词的共现来学习科学术语和概念的含义,例如金属的晶体结构。
类似地,当在材料科学文本上进行训练时,该算法能够简单地基于摘要中的单词的位置以及它们与其他单词的共现来学习科学术语和概念的含义,例如金属的晶体结构。当每个化学元素的向量投影到两个维度时,Word2vec甚至能够学习元素周期表中元素之间的关系。
提前预测发现
因此,如果Word2vec如此智能,它能预测新型热电材料吗?良好的热电材料可以有效地将热量转换为电能,并且由安全,丰富且易于生产的材料制成。
伯克利实验室团队采用了算法建议的顶级热电候选者,该算法根据单词向量与“热电”一词的相似性对每个化合物进行排序。然后他们运行计算来验证算法的预测。
在前10个预测中,发现所有计算的功率因数略高于已知热电的平均值,前三位的功率因数在已知热电学的95%以上。
接下来,他们测试了算法是否可以对过去进行实验,只给出2000年之前的摘要。同样,在最热门的预测中,有相当一部分出现在后来的研究中,是随机选择材料的四倍。例如,利用2008年以前的数据训练出的前五种预测中,有三种已经被发现,剩下的两种含有稀有或有毒元素。
结果令人惊讶。“老实说,我没想到算法能够如此预测未来的结果,”Jain说,“我曾经想过,也许这个算法可以描述人们之前做过的事情,但却没有提出这些不同的联系。当我不仅看到预测而且还看到预测背后的推理时,我感到非常惊讶,例如半赫斯勒结构,这是一种非常热的电热晶体结构。”
这项研究表明,如果这个算法早些时候到位,可以想象一些材料提前几年被发现。随着研究,研究人员正在发布该算法预测的前50种热电材料。如果他们想要搜索更好的拓扑绝缘体材料,他们还将发布人们制作自己应用所需的嵌入词。
接下来,团队要开发一个更智能,更强大的搜索引擎,允许研究人员以更有用的方式搜索摘要。
论文:
dx.doi.org/10.1038/s41586-019-1335-8

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消