











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌新技术“数据回声”加速AI训练,减少早期管道阶段的计算量
2019年07月16日 由 深深深海 发表
88030
0
 像谷歌的Tensor Processing Units和英特尔的Nervana神经网络处理器等人工智能加速器硬件有望加速人工智能模型训练,但由于芯片的架构方式,训练管道的早期阶段(如数据预处理)并没有从提升中受益。
像谷歌的Tensor Processing Units和英特尔的Nervana神经网络处理器等人工智能加速器硬件有望加速人工智能模型训练,但由于芯片的架构方式,训练管道的早期阶段(如数据预处理)并没有从提升中受益。谷歌AI研究部Google Brain的科学家在论文中提出一种称为“数据回声”的技术,通过重用这些阶段的中间输出,减少了早期管道阶段使用的计算量。
研究人员表示,性能最好的数据回声算法可以使用较少的上游处理来匹配基线的预测性能,在某些情况下,可以补偿4倍慢的输入管道。
“训练神经网络不仅需要在加速器上运行良好的操作,我们不能单独依靠加速器改进来在所有情况下保持加速,训练计划可能需要读取和解压缩训练数据,对其进行重组,批量处理,甚至转换或扩充。这些步骤可以运行多个系统组件,包括CPU,磁盘,网络带宽和内存带宽。”
在典型的训练管道中,AI系统首先读取和解码输入数据,然后对数据进行重组,应用一组变换来扩充数据,然后再将示例收集到批处理中并迭代更新参数以减少错误。研究人员的数据回应方法在管道中插入一个阶段,在参数更新之前重复前一阶段的输出数据,理论上可以回收空闲计算容量。
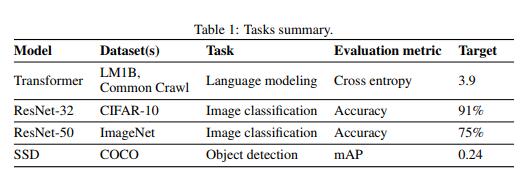 在实验中,团队使用在开源数据集上训练的AI模型评估了两个语言建模任务,两个图像分类任务和一个对象检测任务的数据回应。他们将训练时间测量为达到目标指标所需的新训练示例的数量,并研究数据回声是否可以减少所需示例的数量。
在实验中,团队使用在开源数据集上训练的AI模型评估了两个语言建模任务,两个图像分类任务和一个对象检测任务的数据回应。他们将训练时间测量为达到目标指标所需的新训练示例的数量,并研究数据回声是否可以减少所需示例的数量。共同作者报告说,除了一个案例外,与基线相比,数据回声所需的新例子都更少,而且训练也更少。此外,他们注意到早期的回声被插入到管道中,与批量处理后相比,在数据增强之前需要的新示例更少,而且在批量较大时,偶尔的回声性能更好。
团队表示,“所有数据回声变体至少实现了与两个任务基线相同的性能,这是当训练管道在其中一个上游阶段遇到瓶颈时提高硬件利用率的简单策略,数据回声是优化训练管道或添加额外工作人员以执行上游数据处理的有效替代方案,但这可能并不总是可行的。”
论文:
arxiv.org/pdf/1907.05550.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消