











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






自然梯度优化详解
2019年07月18日 由 sunlei 发表
172161
0
我要讲一个故事:一个你几乎肯定听过的故事,但但它的侧重点与你曾经听过的不同。
对于一阶近似,所有现代的深度学习模型都是使用梯度下降训练的。在梯度下降的每一步,您的参数值开始于某个起点,并将它们移动到最大的损失减少的方向。通过对损失对整个参数向量求导,也就是雅可比矩阵。然而,这只是损失的一阶导数,它没有告诉你曲率的任何信息,或者说,一阶导数变化的有多快。由于您所处的区域中,您对一阶导数的局部近似可能不会从该估计值点(例如,就在一座大山前面的一条向下的曲线)推广到很远的地方,所以您通常希望谨慎,不要迈出太大的一步。因此,为了谨慎起见,我们用步长控制前进的速度,即α(alpha),如下式所示。
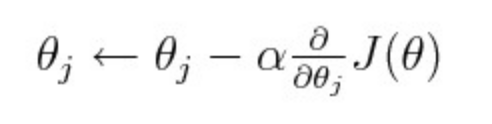
这个步长做了一些有趣的事情:它限制了你要在梯度方向上更新每个参数的距离,并以固定的数量进行更新。在这个算法的最简单版本中,我们取一个标量alpha,让我们假设它是0.1,然后乘以相对于损耗的梯度。我们的梯度,记住,实际上是一个向量-模型中每个参数的损失梯度-因此,当我们用一个标量乘以它时,我们用欧几里得参数距离乘以沿着每个参数轴的更新比例。在梯度下降的最基本版本中,我们在学习过程中使用相同的步长。
但是……这真的有道理吗?具有较小学习速率的前提是,我们知道单个局部梯度估计可能仅在该估计周围的小局部区域有效。但是,参数可以存在于不同的尺度上,并且可以对所学的条件分布产生不同程度的影响。而且,这种程度的影响在培训过程中会波动。从这个角度来看,在欧几里得参数空间中,用固定的全局半径定义安全气泡并不是一件特别明智或有意义的事情。
[caption id="attachment_42198" align="aligncenter" width="450"] 图片来源:科学杂志,因为没有制作这样酷图片的软件,而且该死的梯度计算技术的微妙之处不是一件容易想象的事情。[/caption]
图片来源:科学杂志,因为没有制作这样酷图片的软件,而且该死的梯度计算技术的微妙之处不是一件容易想象的事情。[/caption]
自然梯度的支持者们含蓄提出的一个相反建议是,我们不应该用参数空间中的距离来定义我们的安全窗,而应该用分布空间中的距离来定义它。所以,不是“我将遵循我的当前梯度,以保持参数向量在当前向量的epsilon距离内”,而是说“我将遵循我的当前梯度,以保持分布,我的模型预测在分布的epsilon距离内。”这是先前预测的。这里的概念是,分布之间的距离对于任何缩放、移动或一般的重新参数化都是不变的。例如,可以使用方差参数或比例参数(1/方差)对同一高斯进行参数化;如果在参数空间中查看,两个分布之间的距离将根据使用方差或比例参数化的分布而不同。但是如果你在原始概率空间中定义了一个距离,它将是一致的。
这篇文章的其余部分将试图对一种称为自然梯度学习的方法建立一个更强、更直观的理解,这是一种概念上优雅的想法,旨在纠正参数空间缩放的随意性。我将深入探讨它是如何工作的,如何在构成它的不同数学思想之间建立桥梁,并最终讨论它是否以及在什么地方真正有用。但是,首先:计算分布之间的距离意味着什么?
KL散度,或者更准确地说,Kullback-Leibler散度,在技术上不是分布之间的距离度量(数学学者对所谓的度量或适当距离很挑剔),但它非常接近这个概念。
从数学上讲,它是通过计算对数概率比的期望值(即概率值的原始差异)来获取从一个分布或另一个分布中取样的x值。期望值被一个分布或另一个分布所取代的事实使得它成为一个不对称的度量其中KL(P||Q) != KL(Q||P)。但是,在许多其他方面,KL散度映射到我们对概率距离应该是什么样子的概念:它直接根据概率密度函数是如何定义的来度量的,也就是说,在定义分布的一堆点上的密度值的差异。这有一个非常实际的方面,即当分布对一个广泛的x系列的“这个x的概率是多少”的问题有更进一步的答案时,它们被视为更不同的分布。
在自然梯度的背景下,我们利用KL发散来测量我们的模型预测的输出分布的变化。如果我们要解决一个多向分类问题,那么我们的模型的输出将是一个SoftMax,它可以被看作是一个多项式分布,每个类都有不同的概率。当我们讨论由当前参数值定义的条件概率函数时,这就是我们讨论的概率分布。如果我们使用kl散度作为缩放梯度步骤的方法,这意味着我们在这个空间中将两个参数配置视为“相距更远”,前提是它们对于给定的输入特征集,在kl散度方面会引起非常不同的预测类分布。
到目前为止,我们已经讨论了为什么在参数空间中缩放更新步骤的距离是不令人满意的任意性,并提出了一个不那么任意的选择:缩放我们的步骤,使其在最大程度上与类分布的kl发散保持一定的距离,我们的模型有以前一直在预测。对我来说,理解自然梯度最困难的部分是下一部分:KL发散和Fisher信息矩阵之间的联系。
从故事的结尾开始,自然渐变的实现方式如下:
[caption id="attachment_42200" align="aligncenter" width="646"]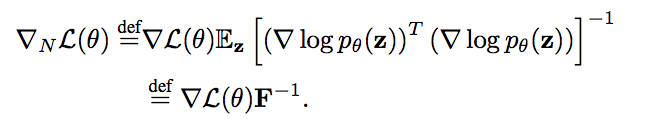 “自然梯度定义为……”[/caption]
“自然梯度定义为……”[/caption]
等号上的def意味着右边后面的符号就是左边符号的定义。右手术语由两部分组成。首先,有关于参数的损失函数的梯度(这是在更正常的梯度下降步骤中使用的相同梯度)。“自然”位来自第二个分量:对数概率函数平方梯度的预期值,超过z。我们取整个物体,也就是费希尔信息矩阵,用它的逆矩阵乘以我们的损失梯度。
p-theta(z)项是由我们的模型定义的条件概率分布,也就是说:神经网络末端的Softmax。我们研究的是所有p-theta项的梯度,因为我们关心的是我们预测的类概率会随着参数的变化而变化的量。预测概率的变化越大,我们的更新前和更新后预测分布之间的KL差异就越大。
自然梯度优化让人困惑的部分原因是,当你阅读或思考它时,有两个截然不同的梯度对象你必须理解和争辩,这意味着不同的事情。顺便提一句,这不可避免地深入到杂草中,特别是在讨论可能性时,而且没有必要掌握整体直觉;如果你不喜欢看那些血淋淋的细节,可以直接跳到下一节。
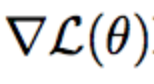
通常,分类损失是一个交叉熵函数,但更广泛地说,它是一个函数,将模型的预测概率分布和真实目标值作为输入,当分布距离目标较远时,它的值更高。该对象的梯度是梯度下降学习的核心内容;它表示如果您将每个参数移动一个单位,您的损失将更改的数量。
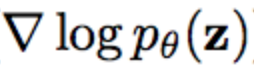
对我来说,这无疑是学习自然梯度最令人困惑的部分。因为,如果你读过费希尔信息矩阵,你会得到很多解释它与模型的对数可能性梯度有关的链接。我之前对似然函数的理解是它表示模型认为某组数据的可能性;特别是,您需要目标值来计算它,因为您的目标是计算当您根据输入特性对模型进行条件设置时,模型分配给真实目标的概率。在讨论似然的大多数情况下,比如非常常见的最大似然技术,您关心的是对数似然的梯度,因为您的似然越大,您的模型分配从真实分布中采样的值的概率就越大,我们越高兴。在实践中,这看起来像计算p(类|x)梯度的期望值,用数据中实际类分布得出的期望值内的概率。
但是,您也可以用另一种方式评估可能性,而不是计算与真实目标值相关的可能性(您希望有一个非零梯度,因为它可能推动您的参数以增加真实目标的概率),您可以计算使用从条件分布本身中提取的概率计算您的期望。也就是说,如果您的网络生成了一个SoftMax,而不是基于给定观测数据中的真实类,以0/1概率的logp(z)的期望值,则使用该类的模型估计概率作为其在期望值中的权重。这将导致整体预期梯度为0,因为我们将模型的当前信念作为基本事实,但我们仍然可以得到梯度方差的估计值(即梯度平方),这是我们的Fisher矩阵(隐式)计算所需的。预测类空间中的kl散度。
这篇文章花了很多时间讨论力学:这个东西到底是什么叫做自然梯度估计,以及它如何工作和为什么工作的更好的直觉。但如果我不回答这样一个问题,我觉得我会有点疏忽:这东西真的有价值吗?
简短的回答是:实际上,对于大多数深度学习应用程序来说,它并没有提供足够的令人信服的价值。有证据表明自然梯度导致收敛发生在更少的步骤中,但是,正如我稍后将讨论的,这是一个有点复杂的比较。自然梯度的思想是优雅的,满足了人们对参数空间中任意缩放更新步骤的沮丧。但是,除了优雅之外,我不清楚它是否提供了通过启发式方法无法提供的价值。
据我所知,自然梯度提供了两个重要的价值来源:
现代梯度下降的一大奇迹是它是用一阶方法完成的。一阶方法只计算要更新的参数的导数,而不是二阶导数。对于一阶导数,你所知道的就是(多维形式)一条在特定点与曲线相切的直线。你不知道切线的变化有多快:二阶导数,或者更具描述性的是,函数在任何给定方向上的曲率水平。曲率是一个很有用的东西,因为在一个高曲率的地区,梯度从一个点到另一个点都在急剧变化,你可能需要谨慎地迈出一大步,以免你当地的登山信号误导了你,让你从远处的悬崖上跳下来。我认为这是一种(公认的比严格的更启发式的)方式,如果你处在一个点到点的梯度变化非常大的区域(也就是说:高方差),那么你对梯度的小批量估计在某种意义上更不确定。相比之下,如果在给定的点上梯度几乎没有变化,那么在进行下一步时就不需要太小心了。二阶导数信息很有用,因为它可以让你根据曲率的大小来缩放你的步长。
自然梯度实际上是,机械地,将参数更新除以梯度的二阶导数。相对于给定的参数方向,梯度变化越多,fisher信息矩阵中的值越高,该方向的更新步骤就越低。这里讨论的梯度是批次中点的经验似然梯度。这和损失梯度不同。但是,直观地说,可能性的显著变化与损失函数的显著变化不符,这将是罕见的。因此,通过捕捉给定点处对数似然导数空间曲率的信息,自然梯度也为我们提供了真实潜在损失空间曲率的良好信号。有一个非常有力的论据,当自然梯度被证明可以加速收敛(至少在需要的梯度步数方面),这就是好处所在。
注意,我说过,自然梯度可以加速梯度步骤的收敛。这种精度来自这样一个事实:自然梯度的每一步需要更长的时间,因为它需要计算费希尔信息矩阵,记住,这是存在于n_参数平方空间中的一个量。事实上,这种急剧的减速类似于计算真实损失函数的二阶导数所引起的减速。虽然可能是这样,但我没有看到它指出,计算自然梯度费希尔矩阵比计算与潜在损失相关的二阶导数更快。以这一假设为前提,与直接对损失进行二阶优化的方法(可能同样昂贵)相比,很难看出自然梯度提供了什么边际值。
现代神经网络之所以能够在理论预测一阶唯一方法会失败的情况下取得成功,有很多原因是,深度学习的实践者们发现了一系列巧妙的技巧,从本质上说,是通过经验来近似将包含在解析二阶导数矩阵。
um作为一种优化策略,它的工作原理是保持过去梯度值的指数加权平均值,并将任何给定的梯度更新偏向过去的移动平均值。这有助于解决在一个梯度值变化剧烈的空间中的问题:如果你不断地得到矛盾的梯度更新,他们会以某种方式表现出没有强烈的意见,类似于减慢你的学习速度。相反,如果你反复得到同一方向的梯度估计值,那就是低曲率区域的一个标志,并建议采用更大的步骤,动量跟随而来。
有趣的是,RMSProp是由Geoff Hinton在半程课程中发明的,它是对之前存在的算法Adagrad的一个温和的修改。RMSProp的工作原理是对过去的梯度值的平方进行指数加权移动平均,或者换句话说,梯度的过去方差,然后将更新步骤除以该值。这可以粗略地看作梯度二阶导数的经验估计。
Adam(自适应矩估计)从本质上结合了这两种方法,估计梯度的运行均值和运行方差。它是当今最常见、也是最默认的优化策略之一,主要是因为它可以消除这种噪声级的一阶梯度信号。
有趣的是,所有这些方法都值得一提的是,除了通常根据函数曲率缩放更新步骤外,它们还根据这些特定方向上的曲率量不同缩放不同的更新方向。这涉及到我们前面讨论过的一些事情,关于如何以相同的数量缩放所有参数可能不是一件明智的事情。你甚至可以从距离的角度来考虑这一点:如果一个方向上的曲率很高,那么在相同数量的欧几里德参数空间中的一个步骤会使我们在梯度值的预期变化方面走得更远。
因此,虽然在为参数更新定义一致的方向方面,这并没有自然梯度的优雅,但它确实检查了大多数相同的框:在方向和时间点上调整更新步骤的能力,在曲率不同的地方,以及在概念上,在曲率不同,理论上,given-sized参数的步骤有不同程度的实际影响。
好吧,那么,最后一节提出:如果我们的目标是使用对数可能性的分析曲率估计作为损失曲率估计的代替品,那么为什么我们不直接使用对数可能性的分析曲率估计,或者近似使用对数可能性的分析曲率估计,因为这两种分析n²计算看起来都非常耗时。但是,如果您处于这样一种情况下,为了预测类分布本身的利益,而不仅仅是作为损失变化的代理,您实际上关心预测类分布的变化,那么会怎样呢?这样的情况会是什么样子?
这种情况的一个例子可能并非巧合,它是当前自然梯度方法的主要使用领域之一:加强学习领域的信任区域政策优化。TRPO的基本直觉被灾难性故障或灾难性崩溃的概念所包裹。在策略渐变设置中,您在模型末尾预测的分布是对动作的分布,以某些输入状态为条件。而且,如果你正在学习政策,你的下一轮培训的数据是从你的模型当前预测的政策中收集的,那么你可以不再收集有趣的数据学习的(例如,徘徊在一个圆的政策,不太可能让你有用奖励信号学习)。这就是政策遭遇灾难性崩溃的含义。为了避免这种情况,我们希望保持谨慎,而不是进行梯度更新,因为这会极大地改变我们的策略(根据给定场景中不同操作的概率)。如果我们在预测概率的变化上谨慎而渐进,就会限制我们突然跳到一个不可行的状态的能力。
这是自然梯度的一个更强有力的例子:这里,我们关心的实际控制是在一个新的参数配置下,不同动作的预测概率会改变多少。我们关心它本身,而不仅仅是作为损失函数的代理。
我喜欢通过让你知道关于一个主题我还有哪些困惑的地方来结束这些文章,因为,虽然解释者的文章框架意味着完全理解的崇高地位,但这并不完全是事实。和往常一样,如果你发现一些你认为我弄错了的事情,请留言给我,我会努力改正的!
我从来没有决定性地发现计算对数似然费希尔矩阵是否比计算损失函数的黑森系数更有效(如果是的话,那就是自然梯度是获取损失表面曲率信息的更便宜的方法的论据)。
我相对但不完全相信,当我们取对数概率z上的期望值时,该期望值正被我们的模型预测的概率所取代(一个期望值必须相对于一组概率来定义)。
对于一阶近似,所有现代的深度学习模型都是使用梯度下降训练的。在梯度下降的每一步,您的参数值开始于某个起点,并将它们移动到最大的损失减少的方向。通过对损失对整个参数向量求导,也就是雅可比矩阵。然而,这只是损失的一阶导数,它没有告诉你曲率的任何信息,或者说,一阶导数变化的有多快。由于您所处的区域中,您对一阶导数的局部近似可能不会从该估计值点(例如,就在一座大山前面的一条向下的曲线)推广到很远的地方,所以您通常希望谨慎,不要迈出太大的一步。因此,为了谨慎起见,我们用步长控制前进的速度,即α(alpha),如下式所示。
这个步长做了一些有趣的事情:它限制了你要在梯度方向上更新每个参数的距离,并以固定的数量进行更新。在这个算法的最简单版本中,我们取一个标量alpha,让我们假设它是0.1,然后乘以相对于损耗的梯度。我们的梯度,记住,实际上是一个向量-模型中每个参数的损失梯度-因此,当我们用一个标量乘以它时,我们用欧几里得参数距离乘以沿着每个参数轴的更新比例。在梯度下降的最基本版本中,我们在学习过程中使用相同的步长。
但是……这真的有道理吗?具有较小学习速率的前提是,我们知道单个局部梯度估计可能仅在该估计周围的小局部区域有效。但是,参数可以存在于不同的尺度上,并且可以对所学的条件分布产生不同程度的影响。而且,这种程度的影响在培训过程中会波动。从这个角度来看,在欧几里得参数空间中,用固定的全局半径定义安全气泡并不是一件特别明智或有意义的事情。
[caption id="attachment_42198" align="aligncenter" width="450"]
图片来源:科学杂志,因为没有制作这样酷图片的软件,而且该死的梯度计算技术的微妙之处不是一件容易想象的事情。[/caption]自然梯度的支持者们含蓄提出的一个相反建议是,我们不应该用参数空间中的距离来定义我们的安全窗,而应该用分布空间中的距离来定义它。所以,不是“我将遵循我的当前梯度,以保持参数向量在当前向量的epsilon距离内”,而是说“我将遵循我的当前梯度,以保持分布,我的模型预测在分布的epsilon距离内。”这是先前预测的。这里的概念是,分布之间的距离对于任何缩放、移动或一般的重新参数化都是不变的。例如,可以使用方差参数或比例参数(1/方差)对同一高斯进行参数化;如果在参数空间中查看,两个分布之间的距离将根据使用方差或比例参数化的分布而不同。但是如果你在原始概率空间中定义了一个距离,它将是一致的。
这篇文章的其余部分将试图对一种称为自然梯度学习的方法建立一个更强、更直观的理解,这是一种概念上优雅的想法,旨在纠正参数空间缩放的随意性。我将深入探讨它是如何工作的,如何在构成它的不同数学思想之间建立桥梁,并最终讨论它是否以及在什么地方真正有用。但是,首先:计算分布之间的距离意味着什么?
授权给KL
KL散度,或者更准确地说,Kullback-Leibler散度,在技术上不是分布之间的距离度量(数学学者对所谓的度量或适当距离很挑剔),但它非常接近这个概念。
从数学上讲,它是通过计算对数概率比的期望值(即概率值的原始差异)来获取从一个分布或另一个分布中取样的x值。期望值被一个分布或另一个分布所取代的事实使得它成为一个不对称的度量其中KL(P||Q) != KL(Q||P)。但是,在许多其他方面,KL散度映射到我们对概率距离应该是什么样子的概念:它直接根据概率密度函数是如何定义的来度量的,也就是说,在定义分布的一堆点上的密度值的差异。这有一个非常实际的方面,即当分布对一个广泛的x系列的“这个x的概率是多少”的问题有更进一步的答案时,它们被视为更不同的分布。
在自然梯度的背景下,我们利用KL发散来测量我们的模型预测的输出分布的变化。如果我们要解决一个多向分类问题,那么我们的模型的输出将是一个SoftMax,它可以被看作是一个多项式分布,每个类都有不同的概率。当我们讨论由当前参数值定义的条件概率函数时,这就是我们讨论的概率分布。如果我们使用kl散度作为缩放梯度步骤的方法,这意味着我们在这个空间中将两个参数配置视为“相距更远”,前提是它们对于给定的输入特征集,在kl散度方面会引起非常不同的预测类分布。
费希尔事件
到目前为止,我们已经讨论了为什么在参数空间中缩放更新步骤的距离是不令人满意的任意性,并提出了一个不那么任意的选择:缩放我们的步骤,使其在最大程度上与类分布的kl发散保持一定的距离,我们的模型有以前一直在预测。对我来说,理解自然梯度最困难的部分是下一部分:KL发散和Fisher信息矩阵之间的联系。
从故事的结尾开始,自然渐变的实现方式如下:
[caption id="attachment_42200" align="aligncenter" width="646"]
“自然梯度定义为……”[/caption]等号上的def意味着右边后面的符号就是左边符号的定义。右手术语由两部分组成。首先,有关于参数的损失函数的梯度(这是在更正常的梯度下降步骤中使用的相同梯度)。“自然”位来自第二个分量:对数概率函数平方梯度的预期值,超过z。我们取整个物体,也就是费希尔信息矩阵,用它的逆矩阵乘以我们的损失梯度。
p-theta(z)项是由我们的模型定义的条件概率分布,也就是说:神经网络末端的Softmax。我们研究的是所有p-theta项的梯度,因为我们关心的是我们预测的类概率会随着参数的变化而变化的量。预测概率的变化越大,我们的更新前和更新后预测分布之间的KL差异就越大。
自然梯度优化让人困惑的部分原因是,当你阅读或思考它时,有两个截然不同的梯度对象你必须理解和争辩,这意味着不同的事情。顺便提一句,这不可避免地深入到杂草中,特别是在讨论可能性时,而且没有必要掌握整体直觉;如果你不喜欢看那些血淋淋的细节,可以直接跳到下一节。
损失梯度
通常,分类损失是一个交叉熵函数,但更广泛地说,它是一个函数,将模型的预测概率分布和真实目标值作为输入,当分布距离目标较远时,它的值更高。该对象的梯度是梯度下降学习的核心内容;它表示如果您将每个参数移动一个单位,您的损失将更改的数量。
对数似然的梯度
对我来说,这无疑是学习自然梯度最令人困惑的部分。因为,如果你读过费希尔信息矩阵,你会得到很多解释它与模型的对数可能性梯度有关的链接。我之前对似然函数的理解是它表示模型认为某组数据的可能性;特别是,您需要目标值来计算它,因为您的目标是计算当您根据输入特性对模型进行条件设置时,模型分配给真实目标的概率。在讨论似然的大多数情况下,比如非常常见的最大似然技术,您关心的是对数似然的梯度,因为您的似然越大,您的模型分配从真实分布中采样的值的概率就越大,我们越高兴。在实践中,这看起来像计算p(类|x)梯度的期望值,用数据中实际类分布得出的期望值内的概率。
但是,您也可以用另一种方式评估可能性,而不是计算与真实目标值相关的可能性(您希望有一个非零梯度,因为它可能推动您的参数以增加真实目标的概率),您可以计算使用从条件分布本身中提取的概率计算您的期望。也就是说,如果您的网络生成了一个SoftMax,而不是基于给定观测数据中的真实类,以0/1概率的logp(z)的期望值,则使用该类的模型估计概率作为其在期望值中的权重。这将导致整体预期梯度为0,因为我们将模型的当前信念作为基本事实,但我们仍然可以得到梯度方差的估计值(即梯度平方),这是我们的Fisher矩阵(隐式)计算所需的。预测类空间中的kl散度。
那么……这有帮助吗?
这篇文章花了很多时间讨论力学:这个东西到底是什么叫做自然梯度估计,以及它如何工作和为什么工作的更好的直觉。但如果我不回答这样一个问题,我觉得我会有点疏忽:这东西真的有价值吗?
简短的回答是:实际上,对于大多数深度学习应用程序来说,它并没有提供足够的令人信服的价值。有证据表明自然梯度导致收敛发生在更少的步骤中,但是,正如我稍后将讨论的,这是一个有点复杂的比较。自然梯度的思想是优雅的,满足了人们对参数空间中任意缩放更新步骤的沮丧。但是,除了优雅之外,我不清楚它是否提供了通过启发式方法无法提供的价值。
据我所知,自然梯度提供了两个重要的价值来源:
- 它提供了关于曲率的信息
- 它提供了一种直接控制模型在预测分布空间中的运动的方法,与模型在损失空间中的运动分开。
曲率
现代梯度下降的一大奇迹是它是用一阶方法完成的。一阶方法只计算要更新的参数的导数,而不是二阶导数。对于一阶导数,你所知道的就是(多维形式)一条在特定点与曲线相切的直线。你不知道切线的变化有多快:二阶导数,或者更具描述性的是,函数在任何给定方向上的曲率水平。曲率是一个很有用的东西,因为在一个高曲率的地区,梯度从一个点到另一个点都在急剧变化,你可能需要谨慎地迈出一大步,以免你当地的登山信号误导了你,让你从远处的悬崖上跳下来。我认为这是一种(公认的比严格的更启发式的)方式,如果你处在一个点到点的梯度变化非常大的区域(也就是说:高方差),那么你对梯度的小批量估计在某种意义上更不确定。相比之下,如果在给定的点上梯度几乎没有变化,那么在进行下一步时就不需要太小心了。二阶导数信息很有用,因为它可以让你根据曲率的大小来缩放你的步长。
自然梯度实际上是,机械地,将参数更新除以梯度的二阶导数。相对于给定的参数方向,梯度变化越多,fisher信息矩阵中的值越高,该方向的更新步骤就越低。这里讨论的梯度是批次中点的经验似然梯度。这和损失梯度不同。但是,直观地说,可能性的显著变化与损失函数的显著变化不符,这将是罕见的。因此,通过捕捉给定点处对数似然导数空间曲率的信息,自然梯度也为我们提供了真实潜在损失空间曲率的良好信号。有一个非常有力的论据,当自然梯度被证明可以加速收敛(至少在需要的梯度步数方面),这就是好处所在。
注意,我说过,自然梯度可以加速梯度步骤的收敛。这种精度来自这样一个事实:自然梯度的每一步需要更长的时间,因为它需要计算费希尔信息矩阵,记住,这是存在于n_参数平方空间中的一个量。事实上,这种急剧的减速类似于计算真实损失函数的二阶导数所引起的减速。虽然可能是这样,但我没有看到它指出,计算自然梯度费希尔矩阵比计算与潜在损失相关的二阶导数更快。以这一假设为前提,与直接对损失进行二阶优化的方法(可能同样昂贵)相比,很难看出自然梯度提供了什么边际值。
现代神经网络之所以能够在理论预测一阶唯一方法会失败的情况下取得成功,有很多原因是,深度学习的实践者们发现了一系列巧妙的技巧,从本质上说,是通过经验来近似将包含在解析二阶导数矩阵。
um作为一种优化策略,它的工作原理是保持过去梯度值的指数加权平均值,并将任何给定的梯度更新偏向过去的移动平均值。这有助于解决在一个梯度值变化剧烈的空间中的问题:如果你不断地得到矛盾的梯度更新,他们会以某种方式表现出没有强烈的意见,类似于减慢你的学习速度。相反,如果你反复得到同一方向的梯度估计值,那就是低曲率区域的一个标志,并建议采用更大的步骤,动量跟随而来。
有趣的是,RMSProp是由Geoff Hinton在半程课程中发明的,它是对之前存在的算法Adagrad的一个温和的修改。RMSProp的工作原理是对过去的梯度值的平方进行指数加权移动平均,或者换句话说,梯度的过去方差,然后将更新步骤除以该值。这可以粗略地看作梯度二阶导数的经验估计。
Adam(自适应矩估计)从本质上结合了这两种方法,估计梯度的运行均值和运行方差。它是当今最常见、也是最默认的优化策略之一,主要是因为它可以消除这种噪声级的一阶梯度信号。
有趣的是,所有这些方法都值得一提的是,除了通常根据函数曲率缩放更新步骤外,它们还根据这些特定方向上的曲率量不同缩放不同的更新方向。这涉及到我们前面讨论过的一些事情,关于如何以相同的数量缩放所有参数可能不是一件明智的事情。你甚至可以从距离的角度来考虑这一点:如果一个方向上的曲率很高,那么在相同数量的欧几里德参数空间中的一个步骤会使我们在梯度值的预期变化方面走得更远。
因此,虽然在为参数更新定义一致的方向方面,这并没有自然梯度的优雅,但它确实检查了大多数相同的框:在方向和时间点上调整更新步骤的能力,在曲率不同的地方,以及在概念上,在曲率不同,理论上,given-sized参数的步骤有不同程度的实际影响。
直接分配控制
好吧,那么,最后一节提出:如果我们的目标是使用对数可能性的分析曲率估计作为损失曲率估计的代替品,那么为什么我们不直接使用对数可能性的分析曲率估计,或者近似使用对数可能性的分析曲率估计,因为这两种分析n²计算看起来都非常耗时。但是,如果您处于这样一种情况下,为了预测类分布本身的利益,而不仅仅是作为损失变化的代理,您实际上关心预测类分布的变化,那么会怎样呢?这样的情况会是什么样子?
这种情况的一个例子可能并非巧合,它是当前自然梯度方法的主要使用领域之一:加强学习领域的信任区域政策优化。TRPO的基本直觉被灾难性故障或灾难性崩溃的概念所包裹。在策略渐变设置中,您在模型末尾预测的分布是对动作的分布,以某些输入状态为条件。而且,如果你正在学习政策,你的下一轮培训的数据是从你的模型当前预测的政策中收集的,那么你可以不再收集有趣的数据学习的(例如,徘徊在一个圆的政策,不太可能让你有用奖励信号学习)。这就是政策遭遇灾难性崩溃的含义。为了避免这种情况,我们希望保持谨慎,而不是进行梯度更新,因为这会极大地改变我们的策略(根据给定场景中不同操作的概率)。如果我们在预测概率的变化上谨慎而渐进,就会限制我们突然跳到一个不可行的状态的能力。
这是自然梯度的一个更强有力的例子:这里,我们关心的实际控制是在一个新的参数配置下,不同动作的预测概率会改变多少。我们关心它本身,而不仅仅是作为损失函数的代理。
开放式问题
我喜欢通过让你知道关于一个主题我还有哪些困惑的地方来结束这些文章,因为,虽然解释者的文章框架意味着完全理解的崇高地位,但这并不完全是事实。和往常一样,如果你发现一些你认为我弄错了的事情,请留言给我,我会努力改正的!
我从来没有决定性地发现计算对数似然费希尔矩阵是否比计算损失函数的黑森系数更有效(如果是的话,那就是自然梯度是获取损失表面曲率信息的更便宜的方法的论据)。
我相对但不完全相信,当我们取对数概率z上的期望值时,该期望值正被我们的模型预测的概率所取代(一个期望值必须相对于一组概率来定义)。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消