











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Petuum:分布式深度学习、机器学习与GPU
2019年07月29日 由 bie管我叫啥 发表
873831
0
 大数据,大模型,大承诺
大数据,大模型,大承诺
在过去几年中,人工智能大多处于研究阶段,人工智能的应用正在从实验室和试点转向生产。企业通常通过试点开始采用人工智能,并寻找人工智能可以帮助它们增强企业智能的方法。
一旦试点成功,公司将在许多生产线和生产基地部署AI技术。AI现在能够通过使用机器学习(ML)和深度学习(DL)来摄取,筛选,分类和利用大量原始非结构化数据的功能,并将信息转化为优化且可操作的业务流程。
为了支持业务AI,ML模型现在需要在大数据(TB或数PB)上使用大模型(数十亿个参数)来解决工业规模问题。数据的爆炸式增长以及ML方法扩展到单个处理机器之外的需求推动了更大的AI软件和硬件协调的必要性。
现在,使用和利用复杂的ML模型进行图像识别需要具有数十亿参数的学习模型。在一台机器上用大型数据集上训练具有数十亿个参数的大型模型是不可行的。
AI的硬件与软件动力
为了解决大数据和大模型的问题,许多行业专家已经转向使用图形处理单元(GPU)来运行DL和复杂的ML模型。GPU是专门用于处理密集图形和图像处理的芯片。GPU由许多(比CPU多很多)较小尺寸的逻辑核心组成。
GPU最初被许多计算机游戏玩家用作视觉复杂游戏的图形处理引擎。GPU比传统CPU具有更多的计算单元和内存带宽,是运行和训练高度复杂的ML和DL模型的理想选择。许多大型深度学习项目现在都在GPU之上运行,这是人工智能处理硬件功能的巨大改进。
尽管硬件和GPU处理能力有了很大的进步,但人工智能软件才是解决大数据和大模型问题的关键。即使使用GPU,在一台配备GPU的机器上训练复杂的模型也可能需要数周时间。为了使DL和复杂的ML训练在时间和资源方面成为可能,DL和ML模型需要扩展,并使用支持多CPU和GPU的集群进行训练。
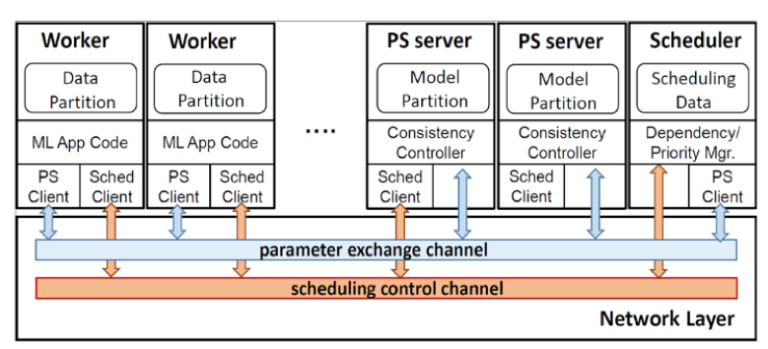 解决此问题的一种方法是通过分布式DL引擎,该引擎可以将多个CPU,GPU,笔记本电脑或任何其他可以将数据处理成“AI超级计算机”的计算机组合在一起。
解决此问题的一种方法是通过分布式DL引擎,该引擎可以将多个CPU,GPU,笔记本电脑或任何其他可以将数据处理成“AI超级计算机”的计算机组合在一起。分布式实现DL和ML处理的软件解决方案需要能够跨多台机器处理大量的参数同步。架构良好的软件可以有效地提高GPU和带宽利用率。重调度、多线程计算和通信使用是提高分布式DL和复杂ML在GPU上性能的关键。如果设计和实现不好,多台机器的使用速度实际上可能比训练DL和复杂ML模型的单台机器慢。
精心设计的AI软件解决方案可以处理多台机器上的分布式DL和ML处理,正确的处理DL和ML的功能强大的硬件是人工智能的关键。这种人工智能软件和硬件动力是消除企业间采用AI障碍的关键驱动因素,利用GPU和软件架构的计算硬件能力,可成功地在生产中部署AI。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消