











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






在Python中如何差分时间序列数据集
2017年08月08日 由 yuxiangyu 发表
154685
0
差分是一个广泛用于时间序列的数据变换。
在本教程中,你将发现如何使用Python将差分操作应用于时间序列数据。
完成本教程后,你将学到:
让我们开始吧。

差分是一种变换时间序列数据集的方法。
它可以用于消除序列对时间性的依赖性,即所谓的时间性依赖。这包含趋势和周期性的结构。
- Forecasting: principles and practice,215页
通过从当前观察中减去先前观察值来实现差分。
这样可以计算出序列差分。
将连续观察值之间的差值称为延迟-1差分。
可以调整延迟差分来适应特定的时间结构。
对于有周期性成分的时间序列,延迟可能是周期性的周期(宽度)。
执行差分操作后,如非线性趋势的情况下,时间结构可能仍然存在。
因此,差分过程可以一直重复,直到所有时间依赖性被消除。
执行差分的次数称为差分序列。
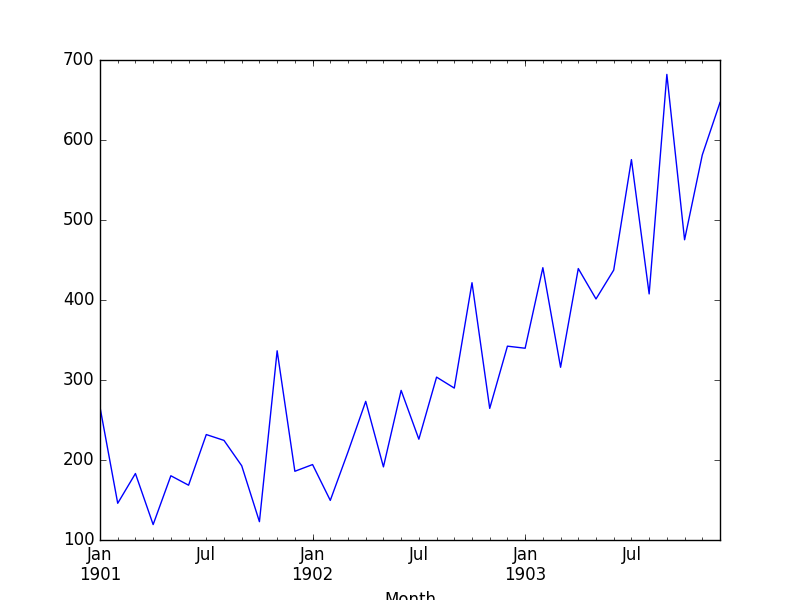
该数据集描述了3年内洗发水的月销量。
这些单位是销售数量,有36个观察值。原始数据集记为Makridakis,Wheelwright和Hyndman(1998)。
在这里下载并了解有关数据集的更多信息。
下面的例子加载并创建了加载数据集的图。
运行该示例将创建显示数据中清晰的线性趋势图。
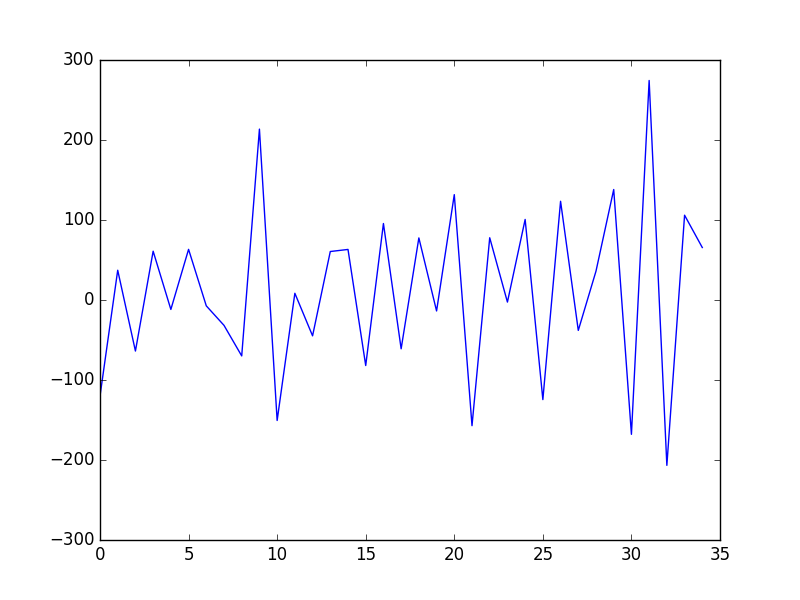
我们可以手动差分数据集。
这涉及开发一个创建差分数据集的新函数。该函数将通过你提供的序列循环,并以指定的间隔或延迟计算差分值。
我们用名为difference()的函数实现此过程。
我们可以看到,在指定的时间间隔后,函数开始差分数据集,以确保实际上可以计算差分值。定义默认间隔或延迟的值为1。这是一个合理的默认值。
另一个改进是能够指定执行差分操作的时间顺序或次数。
以下示例将手动difference()函数应用于洗发水销售数据集。
运行示例创建差分数据集并绘制结果。
Pandas库提供了一种自动计算差分数据集的功能。
这个diff()函数是由Series和DataFrame对象提供。
就像前一节中手动定义的差分函数一样,它需要一个参数来指定间隔或延迟,在本例中称为周期(periods)。
下面的例子演示了如何在Pandas Series对象上使用内置的差分函数。
如上一节所述,运行该示例绘制了差分数据集。
使用Pandas函数的好处需要的代码较少,并且它保留差分序列中时间和日期的信息。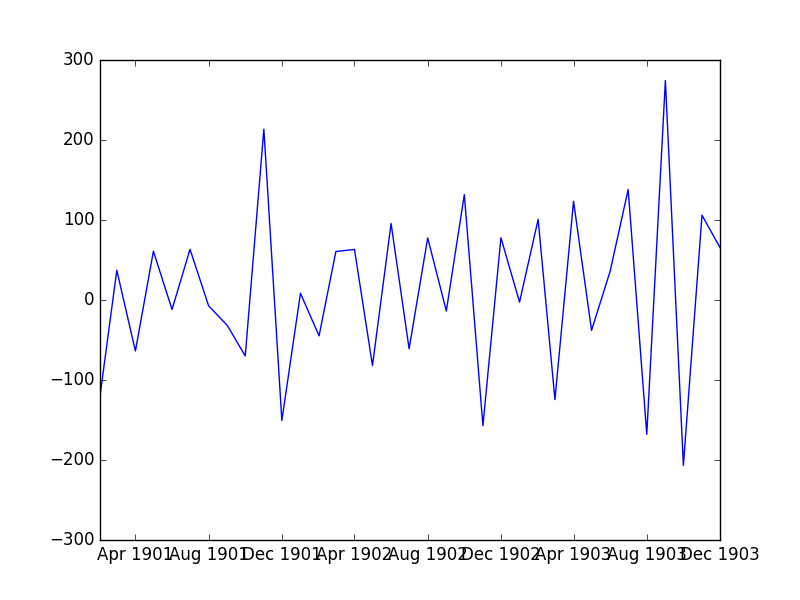
在本教程中,你已经学会了在python中如何将差分操作应用于时间序列数据。
具体来说,你学到了:
原文:http://machinelearningmastery.com/difference-time-series-dataset-python/
在本教程中,你将发现如何使用Python将差分操作应用于时间序列数据。
完成本教程后,你将学到:
- 关于差分运算,包括延迟差分的配置和差分序列。
- 如何开发手动实现的差分运算。
- 如何使用内置的Pandas差分函数。
让我们开始吧。
为什么差分时间序列数据?
差分是一种变换时间序列数据集的方法。
它可以用于消除序列对时间性的依赖性,即所谓的时间性依赖。这包含趋势和周期性的结构。
不同的方法可以帮助稳定时间序列的均值,消除时间序列的变化,从而消除(或减少)趋势和周期性。
- Forecasting: principles and practice,215页
通过从当前观察中减去先前观察值来实现差分。
difference(t) = observation(t) - observation(t-1)
这样可以计算出序列差分。
延迟差分
将连续观察值之间的差值称为延迟-1差分。
可以调整延迟差分来适应特定的时间结构。
对于有周期性成分的时间序列,延迟可能是周期性的周期(宽度)。
差分序列
执行差分操作后,如非线性趋势的情况下,时间结构可能仍然存在。
因此,差分过程可以一直重复,直到所有时间依赖性被消除。
执行差分的次数称为差分序列。
洗发水销售数据集
该数据集描述了3年内洗发水的月销量。
这些单位是销售数量,有36个观察值。原始数据集记为Makridakis,Wheelwright和Hyndman(1998)。
在这里下载并了解有关数据集的更多信息。
下面的例子加载并创建了加载数据集的图。
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
series.plot()
pyplot.show()
运行该示例将创建显示数据中清晰的线性趋势图。
手动差分
我们可以手动差分数据集。
这涉及开发一个创建差分数据集的新函数。该函数将通过你提供的序列循环,并以指定的间隔或延迟计算差分值。
我们用名为difference()的函数实现此过程。
# create a differenced series
def difference(dataset, interval=1):
diff = list()
for i in range(interval, len(dataset)):
value = dataset[i] - dataset[i - interval]
diff.append(value)
return Series(diff)
我们可以看到,在指定的时间间隔后,函数开始差分数据集,以确保实际上可以计算差分值。定义默认间隔或延迟的值为1。这是一个合理的默认值。
另一个改进是能够指定执行差分操作的时间顺序或次数。
以下示例将手动difference()函数应用于洗发水销售数据集。
from pandas import read_csv
from pandas import datetime
from pandas import Series
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
# create a differenced series
def difference(dataset, interval=1):
diff = list()
for i in range(interval, len(dataset)):
value = dataset[i] - dataset[i - interval]
diff.append(value)
return Series(diff)
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
X = series.values
diff = difference(X)
pyplot.plot(diff)
pyplot.show()
运行示例创建差分数据集并绘制结果。
自动差分
Pandas库提供了一种自动计算差分数据集的功能。
这个diff()函数是由Series和DataFrame对象提供。
就像前一节中手动定义的差分函数一样,它需要一个参数来指定间隔或延迟,在本例中称为周期(periods)。
下面的例子演示了如何在Pandas Series对象上使用内置的差分函数。
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)
diff = series.diff()
pyplot.plot(diff)
pyplot.show()
如上一节所述,运行该示例绘制了差分数据集。
使用Pandas函数的好处需要的代码较少,并且它保留差分序列中时间和日期的信息。
总结
在本教程中,你已经学会了在python中如何将差分操作应用于时间序列数据。
具体来说,你学到了:
- 关于差分运算,包括延迟差分的配置和差分序列。
- 如何开发手动实现的差分运算。
- 如何使用内置的Pandas差分函数。
原文:http://machinelearningmastery.com/difference-time-series-dataset-python/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消