











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






27个问题测试你对逻辑回归的理解
2017年08月04日 由 yining 发表
224702
0
逻辑回归可能是最常用的解决所有分类问题的算法。这里有27个问题专门测试你对逻辑回归的理解程度。

1)判断对错:逻辑回归是一种有监督的机器学习算法吗?
A)是
B)不是
答案: A
逻辑回归是一种有监督的学习算法,因为它使用真正的标签进行训练。当你训练模型时,监督学习算法应该有输入变量(X)和目标变量(Y)。
2)判断对错:逻辑回归主要用于回归吗?
A)是
B)不是
答案:B
逻辑回归是一种分类算法,不要与回归混淆。
3)判断对错:用神经网络算法设计逻辑回归算法是否可行?
A)是
B)不是
答案:A
神经网络是一种通用的算法,因此它可以实现线性回归算法。
4)判断对错:在3级分类问题上应用逻辑回归算法是可行的吗?
A)是
B)不是
答案:A
是的,可行。
5)下列哪种方法在逻辑回归上最适合数据?
A)最小二乘方误差
B)极大似然估计
C)杰卡德距离
D)A和B
答案:B
极大似然估计最适合逻辑回归的训练。
6)在逻辑回归输出与目标比较的情况下,下列哪一种评估指标不能被应用?
A)AUC-RUC
B)精确度
C)Logloss
D)均方误差
答案:D
因为逻辑回归是一种分类算法,所以它的输出不能是实时值。因此,均方误差不能用于评估它。
7)分析逻辑回归性能的一个很好的方法是AIC准则,它类似于线性回归中的R-Squared。
以下关于AIC的哪一种说法是对的?
A)我们更喜欢具有最小的价值的模型
B)我们更喜欢具有最大的价值的模型
C)以上两种情况都取决于情况
D)都不对
答案:A
我们在逻辑回归中选择了最好的模型,至少AIC是这样的。
更多信息请参考: http://www4.ncsu.edu/~shu3/Presentation/AIC.pdf
8)判断对错:在训练逻辑回归之前,需要对特征进行标准化。
A)是
B)不是
答案:B
逻辑回归不需要标准化。标准化特性的主要目的是帮助优化技术的融合。
9)我们用哪些算法来进行变量选择?
A)LASSO
B)Ridge
C)两种都是
D)两种都不是
答案:A
以LASSO的情况,我们应用了绝对的惩罚,在增加了LASSO的惩罚后,一些变量的系数可能变为零。
10-11)考虑下面的逻辑回归模型: P(y =1|x,w)=g(w0 +w1x),g(z)是逻辑函数。
在上面的方程中P(y =1|x;w)被看作是x的函数,我们可以通过改变参数w来得到。
10)在这种情况下,p的范围是多少?
A)(0,inf)
B)(-inf,0)
C)(0,1)
D)(-inf,inf)
答案: C
x的值在−∞到+∞的实数范围内,逻辑函数将会给出(0,1)之间的输出。
11)在上面的问题中,你认为哪个函数会使p在(0,1)之间?
A)逻辑函数
B)对数似然函数
C)两者混合
D)都不是
答案:A
解释同上
12-13)假设你训练了一个逻辑回归分类器,你的假设函数H是:
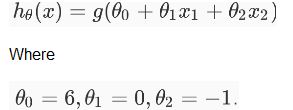
12)下列哪张图代表上述分类器所给出的决策边界?
A)
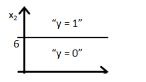
B)
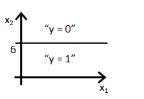
C)
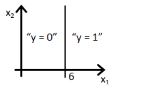
D)
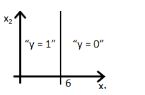
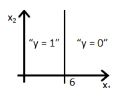
答案:B
因为直线由y=g(6+x2)来表示,选项A和B都对,但选项B是正确答案,因为当你把值x2=6放在方程中,y=g(0),这意味着y=0.5将会在直线上,如果你将x2的值增大,你会得到负值,所以输出范围y=0。
13)如果将x1和x2的系数替换,那么输出的结果是什么呢?
A)

B)
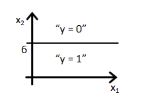
C)
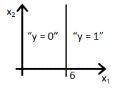
D)
答案:D
解释同上
14)假设你得到了一枚硬币,你想知道抛出正面的概率。在这种情况下,下列哪一种选项是正确的?
A)概率是0
B)概率是0.5
C)概率是1
D)都不是
答案:C
如果硬币的成功概率是1/2,而失败的概率是1/2,那么概率就是1。
15)下列哪个选项是正确的?
A)线性回归误差值必须是正常分布的但在逻辑回归的情况下并非如此。
B)逻辑回归误差值必须是正常分布的但是在线性回归的情况下并非如此。
C)线性回归和逻辑回归误差值必须是正常分布的。
D)线性回归和逻辑回归误差值都不是正常分布的。
答案:A
只有A是正确的,请参阅本教程 https://czep.net/stat/mlelr.pdf
16)在使用高(无限)正则化的情况下,偏差会如何变化?
假设你已经在两个散点图给出 “a”和“b”两个类(蓝色表示为正类,红色为负类)。在散点图a中,你使用逻辑回归(黑线是决策边界)正确地分类了所有的数据点。
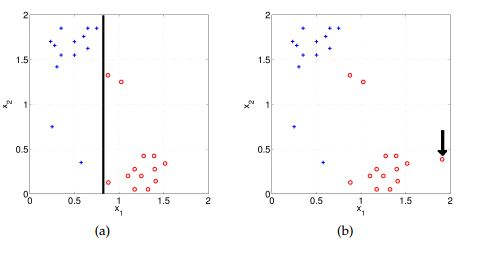
A)偏差将会很高
B)偏差会很低
C)不好说
D)都不是
答案:A
模型会变得非常简单,所以偏差非常高。
17)假设你在给定的数据上应用了逻辑回归模型,得到了训练精度X和测试精度y。现在,你想在同样的数据中添加一些新特性。哪个选项在这种情况下是正确的?(多选)
注意:考虑剩下的参数是相同的。
A)的训练精度增加
B)训练的准确性增加或保持不变
C)测试精度降低
D)测试的准确性增加或保持不变
答案:A和D
在模型中加入更多的特性会提高训练的准确性,因为模型必须考虑更多的数据来适应逻辑回归。但是如果发现特征显著的话,测试的准确性就会提高。
18)在逻辑回归中,下列哪个选项是正确的?
A)我们需要在n级分类问题中匹配n个模型
B)我们需要将n-1个模型归入n类
C)我们只需要将一个模型放入到n个类中
D)都不正确
答案:A
如果有n个类,那么n个独立的逻辑回归就必须匹配,每个类别的概率都被预测到其他类别的组合中。
19)下面是两个不同的逻辑模型,它们的值分别为β0和β1。
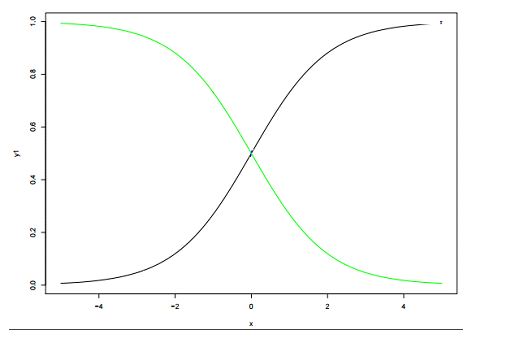
下面哪个陈述正确的描述了两个逻辑模型的值β0(绿色)和β1(黑色)?
注意:考虑Y=β0+β1*X。在这里,β0是截距,β1是系数。
1)绿色β1比黑色大
B)绿色β1比黑色小
C)β1对两个模型都是一样的
D)不好说
答案:D
β0和β1: β0 = 0, β1 = 1 是在X1里的颜色(黑色),β0 = 0,β1 = −1是在X4里的颜色(绿色)
20-22)下面是三个散点图(从左到右A,B,C)和手工绘制的逻辑回归的决策边界。
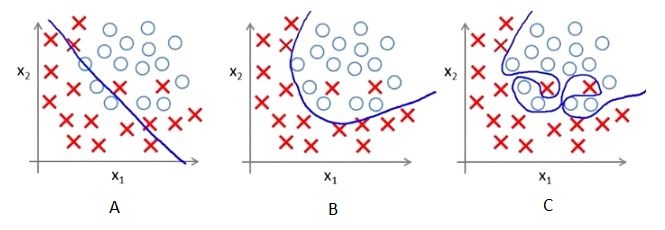
20)图中的哪一个显示决策边界过度拟合训练数据?
A)A
B)B
C)C
D)都不是
答案:C
因为在C中,决策边界是不平滑的,这意味着它将过度拟合数据。
21)看到这种可视化之后你会得出什么结论?
1.与B和C相比较,散点图A的训练误差最大。
2.这个回归问题的最佳模型是C,因为它有最小的训练误差(0)。
3.第二个模型比第一个和第三个模型更具有鲁棒性,因为它将在不可见的数据上表现最好。
4.第三种模式与第一种和第二种模式相比更能过度拟合。
5.它们都将执行相同的操作,因为我们还没有看到测试数据。
A)1和3
B)1和3
C)1,3,4
D)5
答案:C
图表中的趋势看起来像是独立变量X的一个二次趋势,一个高次(右图)多项式可能在训练群中有很高的准确性,但是在测试数据集上可能会失败。如果你在左边的图中看到我们会有最大的训练误差是因为它不符合训练数据。
22)假设在正则化的不同值上产生了以上的决策边界。上述哪一个决策边界显示了最大的正则化?
A)A
B)B
C)C
D)都有相同的正则化
答案:A
因为更多的正则化意味着更多的惩罚,还意味着更少的复杂的决策边界,图A显示了这些特征。
23)下图显示了三种逻辑回归模型的aucroc曲线。不同的颜色显示不同的超参数值的曲线。下列哪一项将会得到最好的结果?
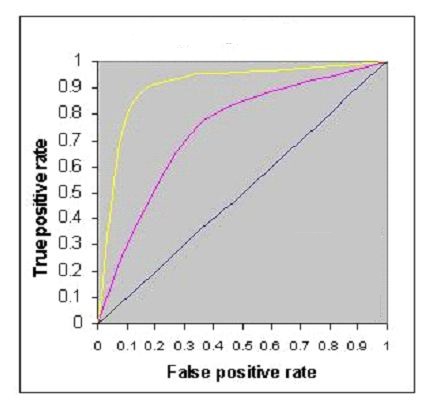 A)黄色
A)黄色
B)粉色
C)黑色
D)都能
答案:A
曲线下区域最大的,分类最好。
24)如果你想对同样的数据进行逻辑回归分析,这些数据会花费更少的时间,而且会给出比较相似的准确性(可能不一样),那么你会怎么做呢?
假设你正在使用一个大型数据集的逻辑回归模型。在如此庞大的数据中,你可能面临的一个问题是,逻辑回归需要很长时间才能进行训练。
A)降低学习率并减少迭代次数
B)降低学习率并增加迭代次数
C)提高学习率并增加迭代次数
D)提高学习速度并减少迭代次数
答案:D
如果你在训练的时候减少了迭代次数,那么时间就会减少,但不会给出同样的准确性,但也不会强求你提高学习率。
25)下面哪个图像显示了y=1的成本函数?
下面是两个类的分类问题在逻辑回归中(y轴损失函数和x轴对数概率)的损失函数。
注意:y是目标类
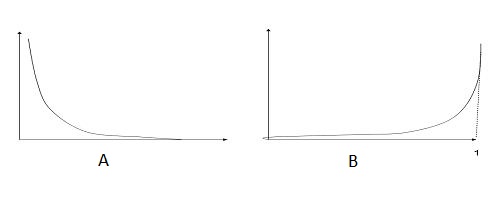
A)A
B)B
C)两个都是
D)两个都不是
答案:A
随着对数概率的增加,损失函数会减少。
26)假设下图是逻辑回归的成本函数。
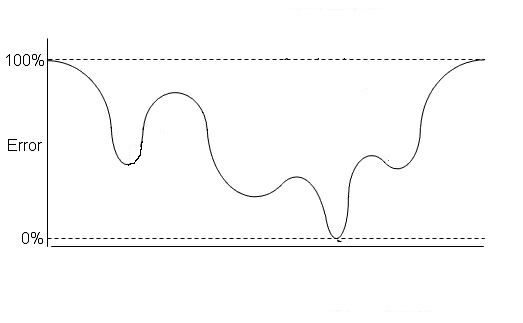 现在,图中有多少个局部最小值?
现在,图中有多少个局部最小值?
A)1个
B)2个
C)3个
D)4个
答案:C
图中有3个局部极小值。
27)逻辑回归分类器能对下面的数据做一个完美的分类吗?
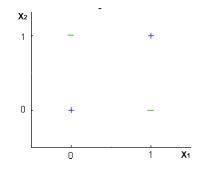
注意:你只能使用X1和X2变量,其中X1和X2只能取两个二进制值(0,1)。
A)正确
B)错误
C)不好说
D)都不对
答案:B
逻辑回归只构成线性决策表,但图中的例子并不是线性可分的。
此文为编译作品,作者
1)判断对错:逻辑回归是一种有监督的机器学习算法吗?
A)是
B)不是
答案: A
逻辑回归是一种有监督的学习算法,因为它使用真正的标签进行训练。当你训练模型时,监督学习算法应该有输入变量(X)和目标变量(Y)。
2)判断对错:逻辑回归主要用于回归吗?
A)是
B)不是
答案:B
逻辑回归是一种分类算法,不要与回归混淆。
3)判断对错:用神经网络算法设计逻辑回归算法是否可行?
A)是
B)不是
答案:A
神经网络是一种通用的算法,因此它可以实现线性回归算法。
4)判断对错:在3级分类问题上应用逻辑回归算法是可行的吗?
A)是
B)不是
答案:A
是的,可行。
5)下列哪种方法在逻辑回归上最适合数据?
A)最小二乘方误差
B)极大似然估计
C)杰卡德距离
D)A和B
答案:B
极大似然估计最适合逻辑回归的训练。
6)在逻辑回归输出与目标比较的情况下,下列哪一种评估指标不能被应用?
A)AUC-RUC
B)精确度
C)Logloss
D)均方误差
答案:D
因为逻辑回归是一种分类算法,所以它的输出不能是实时值。因此,均方误差不能用于评估它。
7)分析逻辑回归性能的一个很好的方法是AIC准则,它类似于线性回归中的R-Squared。
以下关于AIC的哪一种说法是对的?
A)我们更喜欢具有最小的价值的模型
B)我们更喜欢具有最大的价值的模型
C)以上两种情况都取决于情况
D)都不对
答案:A
我们在逻辑回归中选择了最好的模型,至少AIC是这样的。
更多信息请参考: http://www4.ncsu.edu/~shu3/Presentation/AIC.pdf
8)判断对错:在训练逻辑回归之前,需要对特征进行标准化。
A)是
B)不是
答案:B
逻辑回归不需要标准化。标准化特性的主要目的是帮助优化技术的融合。
9)我们用哪些算法来进行变量选择?
A)LASSO
B)Ridge
C)两种都是
D)两种都不是
答案:A
以LASSO的情况,我们应用了绝对的惩罚,在增加了LASSO的惩罚后,一些变量的系数可能变为零。
10-11)考虑下面的逻辑回归模型: P(y =1|x,w)=g(w0 +w1x),g(z)是逻辑函数。
在上面的方程中P(y =1|x;w)被看作是x的函数,我们可以通过改变参数w来得到。
10)在这种情况下,p的范围是多少?
A)(0,inf)
B)(-inf,0)
C)(0,1)
D)(-inf,inf)
答案: C
x的值在−∞到+∞的实数范围内,逻辑函数将会给出(0,1)之间的输出。
11)在上面的问题中,你认为哪个函数会使p在(0,1)之间?
A)逻辑函数
B)对数似然函数
C)两者混合
D)都不是
答案:A
解释同上
12-13)假设你训练了一个逻辑回归分类器,你的假设函数H是:
12)下列哪张图代表上述分类器所给出的决策边界?
A)
B)
C)
D)
答案:B
因为直线由y=g(6+x2)来表示,选项A和B都对,但选项B是正确答案,因为当你把值x2=6放在方程中,y=g(0),这意味着y=0.5将会在直线上,如果你将x2的值增大,你会得到负值,所以输出范围y=0。
13)如果将x1和x2的系数替换,那么输出的结果是什么呢?
A)
B)
C)
D)
答案:D
解释同上
14)假设你得到了一枚硬币,你想知道抛出正面的概率。在这种情况下,下列哪一种选项是正确的?
A)概率是0
B)概率是0.5
C)概率是1
D)都不是
答案:C
如果硬币的成功概率是1/2,而失败的概率是1/2,那么概率就是1。
15)下列哪个选项是正确的?
A)线性回归误差值必须是正常分布的但在逻辑回归的情况下并非如此。
B)逻辑回归误差值必须是正常分布的但是在线性回归的情况下并非如此。
C)线性回归和逻辑回归误差值必须是正常分布的。
D)线性回归和逻辑回归误差值都不是正常分布的。
答案:A
只有A是正确的,请参阅本教程 https://czep.net/stat/mlelr.pdf
16)在使用高(无限)正则化的情况下,偏差会如何变化?
假设你已经在两个散点图给出 “a”和“b”两个类(蓝色表示为正类,红色为负类)。在散点图a中,你使用逻辑回归(黑线是决策边界)正确地分类了所有的数据点。
A)偏差将会很高
B)偏差会很低
C)不好说
D)都不是
答案:A
模型会变得非常简单,所以偏差非常高。
17)假设你在给定的数据上应用了逻辑回归模型,得到了训练精度X和测试精度y。现在,你想在同样的数据中添加一些新特性。哪个选项在这种情况下是正确的?(多选)
注意:考虑剩下的参数是相同的。
A)的训练精度增加
B)训练的准确性增加或保持不变
C)测试精度降低
D)测试的准确性增加或保持不变
答案:A和D
在模型中加入更多的特性会提高训练的准确性,因为模型必须考虑更多的数据来适应逻辑回归。但是如果发现特征显著的话,测试的准确性就会提高。
18)在逻辑回归中,下列哪个选项是正确的?
A)我们需要在n级分类问题中匹配n个模型
B)我们需要将n-1个模型归入n类
C)我们只需要将一个模型放入到n个类中
D)都不正确
答案:A
如果有n个类,那么n个独立的逻辑回归就必须匹配,每个类别的概率都被预测到其他类别的组合中。
19)下面是两个不同的逻辑模型,它们的值分别为β0和β1。
下面哪个陈述正确的描述了两个逻辑模型的值β0(绿色)和β1(黑色)?
注意:考虑Y=β0+β1*X。在这里,β0是截距,β1是系数。
1)绿色β1比黑色大
B)绿色β1比黑色小
C)β1对两个模型都是一样的
D)不好说
答案:D
β0和β1: β0 = 0, β1 = 1 是在X1里的颜色(黑色),β0 = 0,β1 = −1是在X4里的颜色(绿色)
20-22)下面是三个散点图(从左到右A,B,C)和手工绘制的逻辑回归的决策边界。
20)图中的哪一个显示决策边界过度拟合训练数据?
A)A
B)B
C)C
D)都不是
答案:C
因为在C中,决策边界是不平滑的,这意味着它将过度拟合数据。
21)看到这种可视化之后你会得出什么结论?
1.与B和C相比较,散点图A的训练误差最大。
2.这个回归问题的最佳模型是C,因为它有最小的训练误差(0)。
3.第二个模型比第一个和第三个模型更具有鲁棒性,因为它将在不可见的数据上表现最好。
4.第三种模式与第一种和第二种模式相比更能过度拟合。
5.它们都将执行相同的操作,因为我们还没有看到测试数据。
A)1和3
B)1和3
C)1,3,4
D)5
答案:C
图表中的趋势看起来像是独立变量X的一个二次趋势,一个高次(右图)多项式可能在训练群中有很高的准确性,但是在测试数据集上可能会失败。如果你在左边的图中看到我们会有最大的训练误差是因为它不符合训练数据。
22)假设在正则化的不同值上产生了以上的决策边界。上述哪一个决策边界显示了最大的正则化?
A)A
B)B
C)C
D)都有相同的正则化
答案:A
因为更多的正则化意味着更多的惩罚,还意味着更少的复杂的决策边界,图A显示了这些特征。
23)下图显示了三种逻辑回归模型的aucroc曲线。不同的颜色显示不同的超参数值的曲线。下列哪一项将会得到最好的结果?
A)黄色B)粉色
C)黑色
D)都能
答案:A
曲线下区域最大的,分类最好。
24)如果你想对同样的数据进行逻辑回归分析,这些数据会花费更少的时间,而且会给出比较相似的准确性(可能不一样),那么你会怎么做呢?
假设你正在使用一个大型数据集的逻辑回归模型。在如此庞大的数据中,你可能面临的一个问题是,逻辑回归需要很长时间才能进行训练。
A)降低学习率并减少迭代次数
B)降低学习率并增加迭代次数
C)提高学习率并增加迭代次数
D)提高学习速度并减少迭代次数
答案:D
如果你在训练的时候减少了迭代次数,那么时间就会减少,但不会给出同样的准确性,但也不会强求你提高学习率。
25)下面哪个图像显示了y=1的成本函数?
下面是两个类的分类问题在逻辑回归中(y轴损失函数和x轴对数概率)的损失函数。
注意:y是目标类
A)A
B)B
C)两个都是
D)两个都不是
答案:A
随着对数概率的增加,损失函数会减少。
26)假设下图是逻辑回归的成本函数。
现在,图中有多少个局部最小值?A)1个
B)2个
C)3个
D)4个
答案:C
图中有3个局部极小值。
27)逻辑回归分类器能对下面的数据做一个完美的分类吗?
注意:你只能使用X1和X2变量,其中X1和X2只能取两个二进制值(0,1)。
A)正确
B)错误
C)不好说
D)都不对
答案:B
逻辑回归只构成线性决策表,但图中的例子并不是线性可分的。
此文为编译作品,作者

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消