











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






关于跨语种语言模型的讨论
2019年08月01日 由 sunlei 发表
861363
0

最近,一个预先训练的模型被证明可以改善下游问题。Lample和Conneau提出了两个新的培训目标来培训跨语言语言模型(XLM)。这种方法可以实现跨语言自然语言推理(XNLI)的最新成果。另一方面,wada和iwata提出了另一种无需并行数据学习跨语言文本表示的方法。他们将其命名为多语言神经语言模型。
本文将讨论多语言神经语言模型的跨语言模型预训练(Lample and Conneau, 2019)和无监督跨语言单词嵌入(Wada and Iwata, 2018)
文章将包括以下内容:
1.数据
2.跨语言语言模型体系结构
3.多语言神经语言模型体系结构
4.实验
数据
Lample和Conneau对单语数据使用Wikipedia dump,而跨语言数据来自:MultiUN (Ziemski 等人,2016):法语、西班牙语、俄语、阿拉伯语和汉语
印度理工学院孟买语料库(Anoop等人,2018):印地语
OPUS (Tiedemann, 2012):德语、希腊语、保加利亚语、土耳其语、越南语、泰语、乌尔都语、斯瓦希里语和斯瓦希里语
wada和iwata对除芬兰语外的所有语言都使用News抓取2012年单语语料库,而对芬兰语则使用News抓取2014年。
跨语言语言模型体系结构
输入表示法
为了处理词汇表外(OOV)和跨语言的问题,采用字节对编码(BPE)子单词算法将一个单词拆分为多个子单词。不同的语言使用不同的子单词集,而是共享相同的字母表、数字、特殊标记和专有名词,以改进跨语言嵌入空间的对齐。
除了子单词,XLM还将位置嵌入(表示句子的位置)和语言嵌入(表示不同的语言)输入到不同的语言模型(LM)中,以学习文本表示。这些LM:
1.因果语言建模(CLM)
2.蒙面语言建模(MLM)
3.翻译语言建模(TLM)
因果语言模型(CLM)
CLM由一个转换器组成,通过提供一组以前的特性来学习文本表示。给定当前批处理之前的隐藏状态,模型预测下一个单词。
蒙面语言建模(MLM)
Lample和Connea遵循Devlin等人(2018)的方法,随机抽取15%的子单词,80%的时间用保留词([MASK])替换,10%的时间用随机工作,10%的时间保持不变。
Devlin等人(2018)的区别在于:
使用任意数量的句子,但不使用成对的句子
子样本高频子字
[caption id="attachment_42510" align="aligncenter" width="770"]
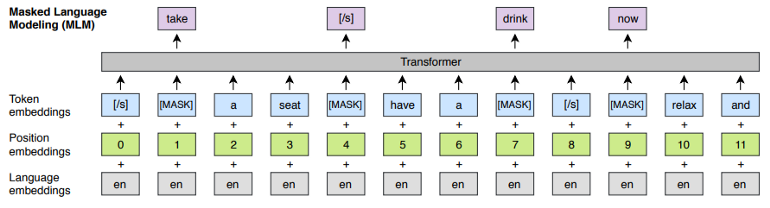 MLM体系结构(Lample and Conneau, 2019)[/caption]
MLM体系结构(Lample and Conneau, 2019)[/caption]翻译语言建模(TLM)
CLM和MLM针对单语数据而设计,TLM针对跨语言数据。BERT使用片段嵌入在一个输入序列中表示不同的句子,而用语言嵌入替换它来表示不同的语言。
在这两种语言的数据中,子单词都是随机抽取的。这两种语言的子词都可以用来预测任何掩码词。
[caption id="attachment_42511" align="aligncenter" width="770"]
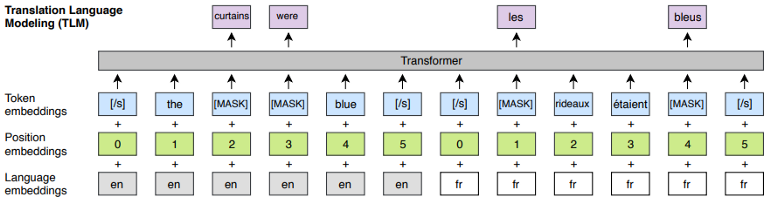 TLM架构(Lample and Conneau, 2019)[/caption]
TLM架构(Lample and Conneau, 2019)[/caption]多语言神经语言模型体系结构
Wada 和Iwata注意到并行数据不适合低资源语言。由于模型无法从并行数据中学习文本表示,因此不同语言中的子单词嵌入将不相同。然而,他们共享双向LSTM来学习多语言的单词嵌入。由于体系结构是跨语言共享的,Wada和Iwata认为,如果一个token是同一个语言,模型就能学习类似的嵌入式。
下图展示了该模型的架构,同时:
1.f:正向和反向LSTM网络
2.EBOS:嵌入式的初始输入
3.WEOS:表示下一个单词是句末的可能性
4.El:语言的单词嵌入
4.WI:语言El的线性投影,用来计算下一个单词的概率分布
[caption id="attachment_42512" align="aligncenter" width="441"]
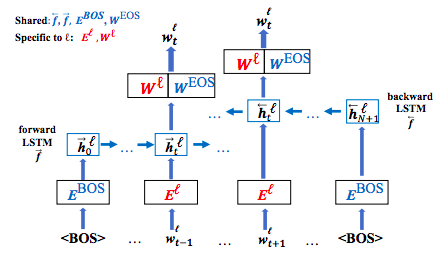 多语言神经语言模型的体系结构(Wada和Iwata 2018)[/caption]
多语言神经语言模型的体系结构(Wada和Iwata 2018)[/caption]实验
基本上,XLM(MLM+TLM)跨语言实现了良好的效果。由于作者注意到CLM在跨语言问题中不具有可伸缩性,所以在接下来的模型比较中没有包含CLM训练对象。
[caption id="attachment_42513" align="aligncenter" width="770"]
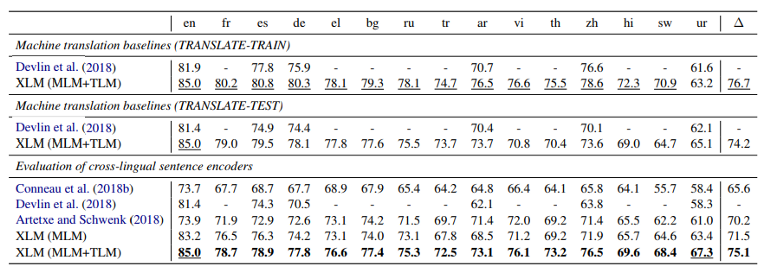 模型间XLM结果(Lample和Conneau, 2019)[/caption]
模型间XLM结果(Lample和Conneau, 2019)[/caption]由于Wada和Iwata只专注于解决少量的单语数据可用,或者单语语料库的领域在不同的语言场景中有所不同。他们打算使用不同的数据集来查看性能。下图显示了如果数据集大小很小,这个模型比其他模型更好。
[caption id="attachment_42514" align="aligncenter" width="385"]
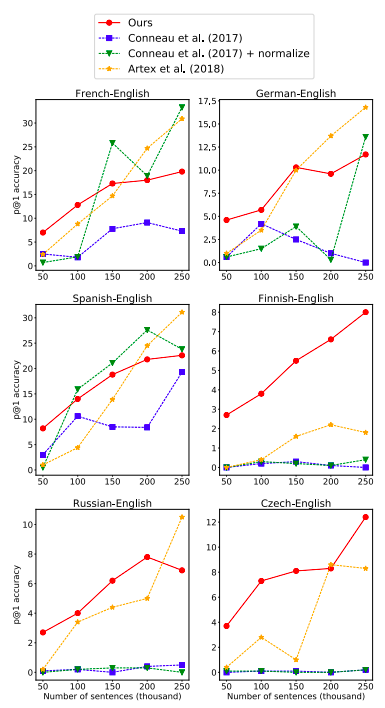 多语言神经语言模型的比较结果(Wada and Iwata 2018)[/caption]
多语言神经语言模型的比较结果(Wada and Iwata 2018)[/caption]总结一下
1.BERT使用段嵌入(表示不同的句子),而XLM使用语言嵌入(表示不同的语言)。
2.CLM不能扩展到跨语言场景。
3.如果需要并行数据(TML)来提高性能,XLM可能不适合低资源语言。同时,设计了多语言神经语言模型来克服这一限制。
参考文献
1.Lample和A. Conneau-跨语言模型培训.2019
2.Devlin, M. W. Chang, K. Lee, K. Toutanova-BERT:语言理解深层双向变压器预习.2018
3.Wada 和T. Iwata.-基于多语言神经语言模型的无监督跨语言词嵌入.2018
原文链接:https://medium.com/towards-artificial-intelligence/cross-lingual-language-model-56a65dba9358

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消