











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌发布分类模型EfficientNet-EdgeTPU,运行速度比ResNet-50快10倍
2019年08月08日 由 张江 发表
255270
0
 谷歌在3月份推出了Coral Dev Board,采用张量处理器(Edge TPU)AI加速器芯片,以及一个USB加密狗,旨在加速现有Raspberry Pi和Linux系统的机器学习推理。
谷歌在3月份推出了Coral Dev Board,采用张量处理器(Edge TPU)AI加速器芯片,以及一个USB加密狗,旨在加速现有Raspberry Pi和Linux系统的机器学习推理。今天,谷歌发布了一系列新的分类模型EfficientNet-EdgeTPU,经过优化,可以在Coral板的系统级模块上运行。
同时,GitHub上提供了EfficientNet-EdgeTPU的训练代码和预训练模型。
精度高,速度快
随着晶体管尺寸的减小变得越来越困难,业界正在重新关注开发特定领域的架构,例如硬件加速器,以继续提高计算能力。虽然这些架构在数据中心和边缘计算平台上不断涌现,但在其上运行的AI模型很少被自定义以利用底层硬件。
因此,EfficientNet-EdgeTPU项目的目标是将源自谷歌的EfficientNets的模型定制为功率高效,低开销的Edge TPU芯片。EfficientNets已经证明,相对于现有的人工智能系统的某些类别,它具有更高的精度和更好的效率,将参数大小和FLOPS降低了一个数量级。
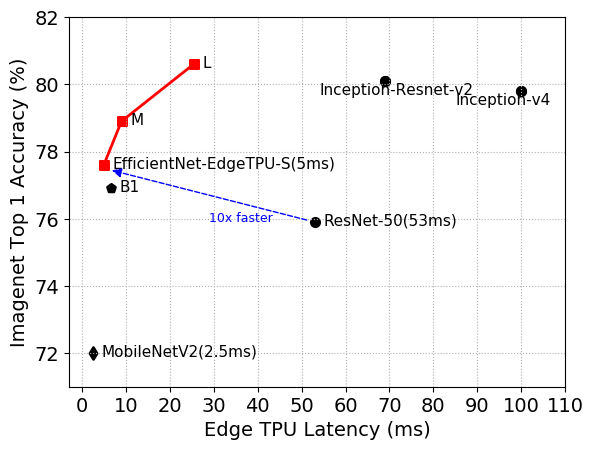
EfficientNet-EdgeTPU-S实现了更高的精度,但运行速度比ResNet-50快10倍
这是因为EfficientNets使用网格搜索来识别固定资源约束下的基线AI模型的缩放维度之间的关系。搜索确定每个维度的适当缩放系数,然后应用系数以将基线模型按比例放大到期望的模型大小或计算预算。
根据Gupta,Tan等人的说法,重新架构EfficientNets以利用Edge TPU,需要调用谷歌开发的AutoML MNAS框架。
MNAS从候选模型列表中识别理想的模型体系结构,方法是结合增强学习来考虑硬件约束,然后在选择最佳模型之前执行各种模型并测量它们的实际性能。
团队使用延迟预测模块对其进行了补充,该模块在Edge TPU上执行时提供了算法延迟的估计。
整体方法产生了一个基线模型,即EfficientNet-EdgeTPU-S,研究人员通过选择输入图像分辨率缩放,网络宽度和深度缩放的最佳组合来扩大规模。
在实验中,与流行的图像分类模型(如Inception-resnet-v2和Resnet50)相比,由此产生的更大的体系结构——EfficientNet-EdgeTPU-M和EfficientNet-EdgeTPU-L,以更高的延迟为代价实现了更高的准确性,并且在Edge TPU上运行得更快。
EfficientNet-EdgeTPU发布的前一天,针对TensorFlow的谷歌s模型优化工具包刚刚发布,这是一套工具,包括混合量化、全整数量化和修剪。值得注意的是训练后的float16量化,它可以将AI模型的大小减少50%,同时只损失了很少的精度。
Github:
github.com/tensorflow/tpu/tree/master/models/official/efficientnet/edgetpu

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消