











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






最大芯片出炉!1.2万亿个晶体管,专为处理AI应用程序而生
2019年08月20日 由 冯鸥 发表
560932
0
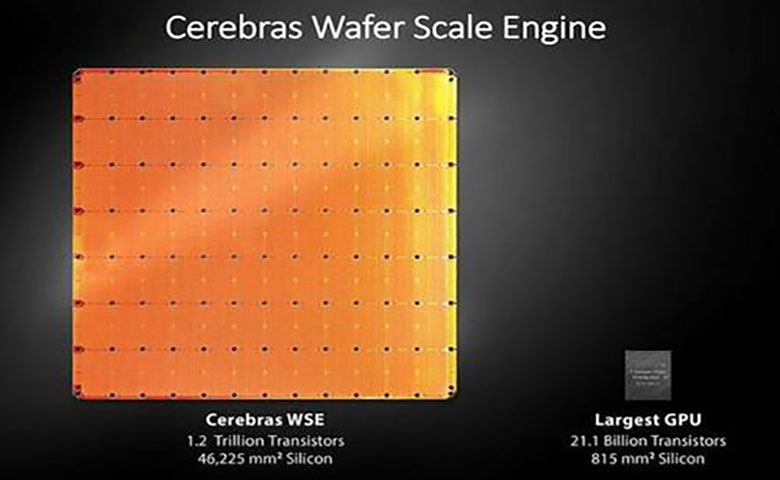 新的人工智能公司Cerebras Systems推出了有史以来最大的半导体芯片。
新的人工智能公司Cerebras Systems推出了有史以来最大的半导体芯片。Cerebras Wafer Scale Engine拥有1.2万亿个晶体管,这是基本的电子开关,也是硅芯片的构建模块。与此对比,1971年,英特尔首款4004处理器拥有2300个晶体管,最新的Advanced Micro Devices处理器拥有320亿个晶体管。
大多数芯片实际上是在12英寸硅晶片上创建的芯片集合,并在芯片工厂中批量处理。但Cerebras Systems是一个连接在一个晶片上的单芯片。这些互连设计使其全部保持高速运行,因此万亿个晶体管像一个整体一样一起工作。
通过这种方式,Cerebras Wafer Scale Engine是有史以来最大的处理器,它是专为处理人工智能应用程序而设计的。该公司本周在加州帕洛阿尔托斯坦福大学举行的热芯片大会上讨论了这一设计。
与三星比起来,三星实际上已经制造了一个闪存芯片,即eUFS,拥有2万亿个晶体管。但Cerebras芯片专为加工而设计,拥有400000个核心,达到42225平方毫米。它比最大的Nvidia图形处理单元大 56.7倍,该单元的尺寸为815平方毫米和211亿个晶体管。它的速度还高出3000倍,包含片上存储和10000倍的内存带宽。
 该芯片来自Andrew Feldman领导的团队,他此前创立了微服务器公司SeaMicro,并以3.34亿美元的价格将该公司出售给了Advanced Micro Devices。Cerebras Systems的联合创始人兼首席硬件架构师Sean Lie将提供一个关于热芯片公司Cerebras Wafer Scale Engine的概述。
该芯片来自Andrew Feldman领导的团队,他此前创立了微服务器公司SeaMicro,并以3.34亿美元的价格将该公司出售给了Advanced Micro Devices。Cerebras Systems的联合创始人兼首席硬件架构师Sean Lie将提供一个关于热芯片公司Cerebras Wafer Scale Engine的概述。最大的芯片
芯片尺寸在AI中非常重要,因为大芯片可以更快地处理信息,在更短的时间内产生答案。减少洞察时间或训练时间,使研究人员能够测试更多想法,使用更多数据并解决新问题。
谷歌,Facebook,OpenAI,腾讯,百度个等认为,今天人工智能的基本限制是训练模型需要很长时间。因此,缩短培训时间消除了整个行业进步的主要瓶颈。
当然,芯片制造商通常不会制造如此大的芯片。在单个晶片上,在制造过程中通常会发生一些杂质。如果一种杂质会导致芯片发生故障,那么晶圆上的一些杂质就会击出一些芯片。实际制造产量仅占实际工作芯片的百分比。
如果晶圆上只有一个芯片,它有杂质的几率是100%,杂质会使芯片失效。但Cerebras设计的芯片是冗余的,因此一种杂质不会禁用整个芯片。
Cerebras WSE专为人工智能设计而设计,包含了基础创新,通过解决限制芯片尺寸的数十年的技术挑战,例如交叉光罩连接,良率,功率输送,推动了最先进技术的发展。每个架构决策都是为了优化AI工作的性能。结果是,Cerebras WSE根据工作量提供了数百或数千倍的现有解决方案的性能,只需很小的功耗和空间。
 通过加速神经网络训练的所有元素来实现这些性能提升。神经网络是多级计算反馈回路。较快的输入在循环中移动,循环学习或训练的速度越快。通过循环更快地移动输入的方法是加速循环内的计算和通信。
通过加速神经网络训练的所有元素来实现这些性能提升。神经网络是多级计算反馈回路。较快的输入在循环中移动,循环学习或训练的速度越快。通过循环更快地移动输入的方法是加速循环内的计算和通信。Linley Group首席分析师Linley Gwennap在一份声明中说:“Cerebras凭借其晶圆级技术实现了巨大的飞跃,在单片硅上实现了比任何人想象的更多的处理性能。为了实现这一壮举,该公司已经解决了一系列恶性工程挑战,这些挑战几十年来阻碍了该行业,包括实施高速芯片到芯片通信,解决制造缺陷,封装如此大的芯片,以及提供高成本。”
通过将各种学科的顶级工程师聚集在一起,Cerebras在短短几年内创造了新技术并交付了一个产品,这是一项令人印象深刻的成就。
该芯片面积比最大的图形处理单元多56.7倍,Cerebras WSE提供更多内核进行计算,更多内存靠近内核,因此内核可以高效运行。由于这些大量的内核和内存位于单个芯片上,因此所有通信都保留在芯片上,这意味着它的低延迟通信带宽是巨大的,因此内核组可以以最高效率进行协作。
Cerebras WSE中的46225平方毫米的硅包含400000个AI优化的、无缓存、无开销的计算内核,以及18千兆字节的本地、分布式、超高速SRAM内存,作为内存层次结构的唯一级别。
内存带宽是每秒9 pb。这些核心通过一个细粒度的、全硬件的、片内网状连接的通信网络连接在一起,提供每秒100 pb的总带宽。更多的内核、更多的本地内存和低延迟的高带宽结构一起创建了加速人工智能工作的最佳架构。
虽然AI在一般意义上使用,但没有两个数据集或AI任务是相同的。新的人工智能工作负载不断涌现,数据集继续增长,随着人工智能的发展,硅和平台解决方案也在不断发展。Cerebras WSE是半导体和平台设计领域令人惊叹的工程成就,可在单晶圆级解决方案中提供超级计算机的计算,高性能存储器和带宽。
公司表示,如果没有多年与全球最大的半导体代工厂或合约制造商台积电及先进工艺技术的领导者密切合作,那么Cerebras WSE的创纪录成就是不可能实现的。WSE由台积电以其先进的16纳米工艺技术制造。
台积电运营高级副总裁JK Wang表示:“我们对Cerebras Systems与Cerebras Wafer Scale Engine的制造合作非常满意,这是晶圆级开发的行业里程碑。台积电的卓越制造和对质量的严格关注使我们能够满足严格的缺陷密度要求,以支持Cerebras创新设计前所未有的芯片尺寸。”
更多核心
WSE包含400000个AI优化的计算核心。被称为稀疏线性代数核心的SLAC,计算核心灵活,可编程,并针对支持所有神经网络计算的稀疏线性代数进行了优化。SLAC的可编程性确保内核可以在不断变化的机器学习领域中运行所有神经网络算法。
 由于稀疏线性代数核心针对神经网络计算基元进行了优化,因此它们可实现业界最佳利用率通常是图形处理单元的三倍或四倍。此外,WSE核心包括Cerebras发明的稀疏性收集技术,以加速稀疏工作负载(包含零的工作负载)的计算性能,如深度学习。
由于稀疏线性代数核心针对神经网络计算基元进行了优化,因此它们可实现业界最佳利用率通常是图形处理单元的三倍或四倍。此外,WSE核心包括Cerebras发明的稀疏性收集技术,以加速稀疏工作负载(包含零的工作负载)的计算性能,如深度学习。“零”在深度学习计算中很普遍。通常,要相乘的向量和矩阵中的大多数元素都是零。然而,乘以零是浪费硅,功率和时间,因为没有新的信息。
因为图形处理单元和张量处理单元是密集的执行引擎,即设计为永不遇到零的引擎,它们即使在零也会乘以每个元素。当50-98%的数据为零时,如深度学习中的情况一样,大多数乘法都被浪费了。
想象一下,当你的大部分步骤没有让你走向终点时,试图快速前进。由于Cerebras稀疏线性代数核不会乘以零,所有零数据都会被滤除,并且可以在硬件中跳过,从而可以在其位置上完成有用的工作。
内存
内存是每个计算机体系结构的关键组件。更接近计算的内存转换为更快的计算,更低的延迟和更好的数据移动功效。高性能深度学习需要大量计算,并且频繁访问数据。这需要计算核心和存储器之间的紧密接近,这在图形处理单元中并非如此,其中绝大多数存储器是缓慢且距离远的(片外)。
Cerebras Wafer Scale Engine包含更多内核,具有比迄今为止任何芯片更多的本地内存,并且在一个时钟周期内可以通过其核心访问18 GB的片上内存。WSE上的核心本地内存集合可提供每秒9 PB的内存带宽,比领先的图形处理单元多3000倍的片上内存和10000倍的内存带宽。
通讯结构
Swarm通信结构是WSE上使用的处理器间通信结构,它以传统通信技术的功耗的一小部分实现突破性带宽和低延迟。Swarm提供低延迟,高带宽的2D网格,可连接WSE上的所有400000个核心,每秒带宽为100 pb。Swarm支持单字活动消息,可以通过接收内核来处理,而无需任何软件开销。
路由,可靠的消息传递和同步都在硬件中处理。消息会自动激活每个到达消息的应用程序处理程序。Swarm为每个神经网络提供独特的优化通信路径。软件根据正在运行的特定用户定义的神经网络的结构,配置通过400000个核连接处理器的最优通信路径。
典型消息遍历一个具有纳秒延迟的硬件链路。Cerebras WSE的总带宽为每秒100 petabits。不需要诸如TCP / IP和MPI之类的通信软件,因此避免了它们的性能损失。
该架构中的通信能量成本远低于每比特1焦耳,这比图形处理单元低近两个数量级。通过结合大量带宽和极低的延迟,Swarm通信结构使Cerebras WSE能够比任何当前可用的解决方案更快地学习。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
微笑不可怕,谁假谁尴尬








广告


写评论取消
回复取消