











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






解近似策略优化(PPO)及其马里奥游戏环境实战
2019年08月22日 由 sunlei 发表
375287
0
强化学习基本上分为两类,即策略梯度和价值函数,它们各有优缺点。在本文中,我们将讨论最先进的策略优化技术,即PPO或近似策略优化。
[caption id="attachment_43197" align="aligncenter" width="1600"] 让AI准备好玩马里奥[/caption]
让AI准备好玩马里奥[/caption]
OpenAI对PPO的引用:
近似策略优化(PPO),其性能与最先进的方法相当或更好,而且实现和调优要简单得多。
在深入研究PPO的细节之前,我们需要了解一些事情,其中包括代理函数的概念,这将帮助我们理解使用PPO的动机。
代理函数:
代理函数可以称为梯度的一种近似形式,它更像一个新物体的梯度。
[caption id="attachment_43198" align="aligncenter" width="389"]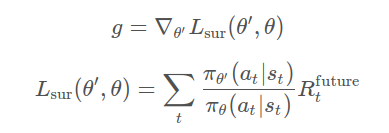 梯度和代理函数[/caption]
梯度和代理函数[/caption]
我们使用这个创新的梯度,这样我们就可以执行梯度上升来更新我们的策略,这可以被认为是直接最大化代理函数。
[caption id="attachment_43199" align="aligncenter" width="700"]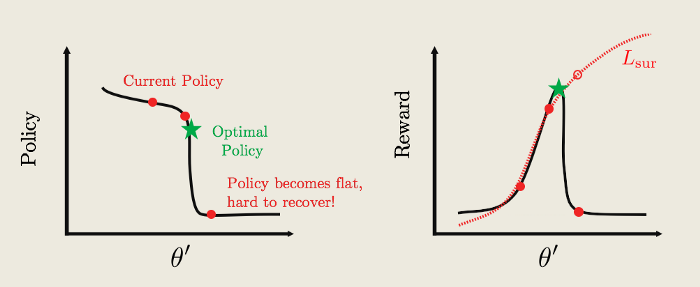 代理函数帮助实现最优策略(来自Udacity深度强化学习nanodegree的图像)[/caption]
代理函数帮助实现最优策略(来自Udacity深度强化学习nanodegree的图像)[/caption]
但是,使用代理函数仍然会给我们留下一个问题,如果我们不断地重复过去使用的轨迹,同时不断地更新我们的策略,我们会发现,在某个时候,新策略可能会偏离旧策略,使我们之前对代用函数所做的所有近似都无效。这就是使用PPO的真正优势所在。
剪裁代理函数:
这是三个词的位置:
1、策略(要实现的最佳策略)
2、近端(代理函数的剪裁)
3、优化(使用代理函数)的出现及其实际意义,导致了算法的命名。
[caption id="attachment_43200" align="aligncenter" width="700"]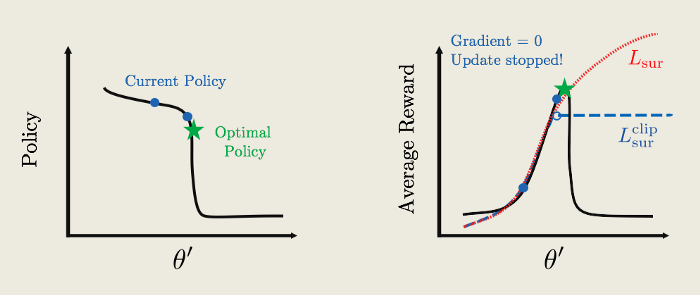 代理函数的裁剪(Udacity深层强化学习纳米图像)[/caption]
代理函数的裁剪(Udacity深层强化学习纳米图像)[/caption]
通过对代理函数的裁剪,使其扁平化,使其更容易、更方便地收敛到最优策略。在这个剪辑下,当我们开始对当前策略应用渐变上升时,更新将保持与正常代理函数中的更新相同,但当我们到达平台时,更新将停止。及时,因为奖励函数是平的,梯度是零,这直接意味着策略更新将停止,我们的最优策略将得到实现。

在理解了这样一个复杂的强化学习算法是如此容易被理解之后,我们的头脑绝对等于被炸了。
我们在Mario环境中也有代码实现,所以要保持稳定并集中精力。
安装和运行Mario环境
[caption id="attachment_43202" align="aligncenter" width="200"] 让我们动起来[/caption]
让我们动起来[/caption]
以下命令将帮助您安装超级马里奥兄弟的环境-
这个代码段将帮助您呈现env,并让您使用它来熟悉操作和状态空间
有关环境的更多细节,请参考此。
为了方便起见,我们将使用OpenAI给出的基线,因为OpenAI拥有大量的RL算法,并不断更新其GitHub存储库。
关于pip用法的说明-pip用于python 2,pip3用于python3
我们将首先下载所需的软件包,然后是RL代码的基线库-
根据您的需求安装Tensorflow (CPU或GPU)
最后,安装基线包-
使用基线中给出的RL代码的语法代码总是这样的-
例如,如果我们想训练一个完全连接的网络,用PPO2控制mujoco类人,持续20分钟,我们将写如下-
在这之后,确保你的gym-retro和atari-py已经成功。有关这些的更多信息,请参考RETRO和ATARI。
注意-如果要在行进的环境中直接使用基线代码运行Mario,请执行以下操作:
为了导入ROMS,您需要从Atari2600 VCS ROM集合中下载Roms.rar并提取.rar文件。完成后,请运行:
这应该在导入时打印出ROMs的名称。ROMs将被复制到您的atari_py安装目录中。
[caption id="attachment_43203" align="aligncenter" width="480"] 当您几乎完成安装时,突然出现一些错误。[/caption]
当您几乎完成安装时,突然出现一些错误。[/caption]
现在开始训练,我们使用下面的命令-
为了在训练过程中保存模型,在训练结束时添加以下参数,训练结束后加载模型也是如此
OK,你可以开始训练你的马里奥去救公主了。
[caption id="attachment_43204" align="aligncenter" width="500"] 庆祝代码完成!!恭喜[/caption]
庆祝代码完成!!恭喜[/caption]
原文链接:https://medium.com/analytics-vidhya/understanding-proximal-policy-optimization-ppo-and-its-implementation-on-mario-game-environment-31ab4ee024ab
[caption id="attachment_43197" align="aligncenter" width="1600"]
让AI准备好玩马里奥[/caption]OpenAI对PPO的引用:
近似策略优化(PPO),其性能与最先进的方法相当或更好,而且实现和调优要简单得多。
在深入研究PPO的细节之前,我们需要了解一些事情,其中包括代理函数的概念,这将帮助我们理解使用PPO的动机。
代理函数:
代理函数可以称为梯度的一种近似形式,它更像一个新物体的梯度。
[caption id="attachment_43198" align="aligncenter" width="389"]
梯度和代理函数[/caption]我们使用这个创新的梯度,这样我们就可以执行梯度上升来更新我们的策略,这可以被认为是直接最大化代理函数。
[caption id="attachment_43199" align="aligncenter" width="700"]
代理函数帮助实现最优策略(来自Udacity深度强化学习nanodegree的图像)[/caption]但是,使用代理函数仍然会给我们留下一个问题,如果我们不断地重复过去使用的轨迹,同时不断地更新我们的策略,我们会发现,在某个时候,新策略可能会偏离旧策略,使我们之前对代用函数所做的所有近似都无效。这就是使用PPO的真正优势所在。
剪裁代理函数:
这是三个词的位置:
1、策略(要实现的最佳策略)
2、近端(代理函数的剪裁)
3、优化(使用代理函数)的出现及其实际意义,导致了算法的命名。
[caption id="attachment_43200" align="aligncenter" width="700"]
代理函数的裁剪(Udacity深层强化学习纳米图像)[/caption]通过对代理函数的裁剪,使其扁平化,使其更容易、更方便地收敛到最优策略。在这个剪辑下,当我们开始对当前策略应用渐变上升时,更新将保持与正常代理函数中的更新相同,但当我们到达平台时,更新将停止。及时,因为奖励函数是平的,梯度是零,这直接意味着策略更新将停止,我们的最优策略将得到实现。
在理解了这样一个复杂的强化学习算法是如此容易被理解之后,我们的头脑绝对等于被炸了。
我们在Mario环境中也有代码实现,所以要保持稳定并集中精力。
安装和运行Mario环境
[caption id="attachment_43202" align="aligncenter" width="200"]
让我们动起来[/caption]以下命令将帮助您安装超级马里奥兄弟的环境-
pip install gym-super-mario-bros
这个代码段将帮助您呈现env,并让您使用它来熟悉操作和状态空间
from nes_py.wrappers import JoypadSpace
import gym_super_mario_bros
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
env = gym_super_mario_bros.make('SuperMarioBros-v0')
env = JoypadSpace(env, SIMPLE_MOVEMENT)
done = True
for step in range(5000):
if done:
state = env.reset()
state, reward, done, info = env.step(env.action_space.sample())
env.render()
env.close()
有关环境的更多细节,请参考此。
为《超级马里奥兄弟》编写PPO
为了方便起见,我们将使用OpenAI给出的基线,因为OpenAI拥有大量的RL算法,并不断更新其GitHub存储库。
关于pip用法的说明-pip用于python 2,pip3用于python3
我们将首先下载所需的软件包,然后是RL代码的基线库-
sudo apt-get install zlib1g-dev libopenmpi-dev ffmpeg
sudo apt-get update
pip3 install opencv-python cmake anyrl gym-retro joblib atari-py
git clone https://github.com/openai/baselines.git
根据您的需求安装Tensorflow (CPU或GPU)
pip install tensorflow-gpu # for GPU
pip install tensorflow # for CPU
最后,安装基线包-
cd baselines
pip3 install -e .
使用基线中给出的RL代码的语法代码总是这样的-
python -m baselines.run --alg=--env= [additional arguments]
例如,如果我们想训练一个完全连接的网络,用PPO2控制mujoco类人,持续20分钟,我们将写如下-
python -m baselines.run --alg=ppo2 --env=Humanoid-v2 --network=mlp --num_timesteps=2e7
在这之后,确保你的gym-retro和atari-py已经成功。有关这些的更多信息,请参考RETRO和ATARI。
注意-如果要在行进的环境中直接使用基线代码运行Mario,请执行以下操作:
为了导入ROMS,您需要从Atari2600 VCS ROM集合中下载Roms.rar并提取.rar文件。完成后,请运行:
python -m atari_py.import_roms
这应该在导入时打印出ROMs的名称。ROMs将被复制到您的atari_py安装目录中。
[caption id="attachment_43203" align="aligncenter" width="480"]
当您几乎完成安装时,突然出现一些错误。[/caption]现在开始训练,我们使用下面的命令-
python3 -m baselines.run --alg=ppo2 --env=SuperMarioBros-Nes
--gamestate=Level3-1.state --num_timesteps=1e7
为了在训练过程中保存模型,在训练结束时添加以下参数,训练结束后加载模型也是如此
--save_path=./PATH_TO_MODEL
--load_path=./PATH_TO_MODEL
OK,你可以开始训练你的马里奥去救公主了。
[caption id="attachment_43204" align="aligncenter" width="500"]
庆祝代码完成!!恭喜[/caption]原文链接:https://medium.com/analytics-vidhya/understanding-proximal-policy-optimization-ppo-and-its-implementation-on-mario-game-environment-31ab4ee024ab

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消