











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






创建更可靠网络爬虫的5个技巧
2019年08月24日 由 sunlei 发表
30478
0
 当我对网站使用爬虫工具的时候,被网站屏蔽可以说是最烦人的情况。要真正精通web爬行,您不仅应该能够快速编写xpath或css选择器,而且如何设计爬行器也非常重要,尤其是从长远来看。
当我对网站使用爬虫工具的时候,被网站屏蔽可以说是最烦人的情况。要真正精通web爬行,您不仅应该能够快速编写xpath或css选择器,而且如何设计爬行器也非常重要,尤其是从长远来看。在我的网络爬行之旅的第一年,我总是专注于如何抓取网站。能够搜集、清理和整理数据,这项成就已经让我很开心了。在爬了越来越多的网站后,我发现有4个重要的元素对构建一个伟大的网络爬虫来说是最重要的。
如何测定一个网络爬虫是否足够优秀?您可能需要考虑以下几点:
爬行器的速度
你能在有限的时间内收集数据吗?
所收集数据的完整性
您是否设法收集了所有感兴趣的数据?
所收集数据的准确性
如何确保您所抓取的数据是准确的?
web爬虫程序的可伸缩性
当网站数量增加时,您能扩展web爬虫程序吗?

为了回答以上所有问题,我将分享一些技巧,这些技巧可以帮助您构建一个优秀的web爬虫程序。
技巧#1减少请求web页面的次数。
使用web抓取框架:以Selenium为例。
如果我们想刮这个网站:https://www.yellowpages.com.sg/category/cleaning-services
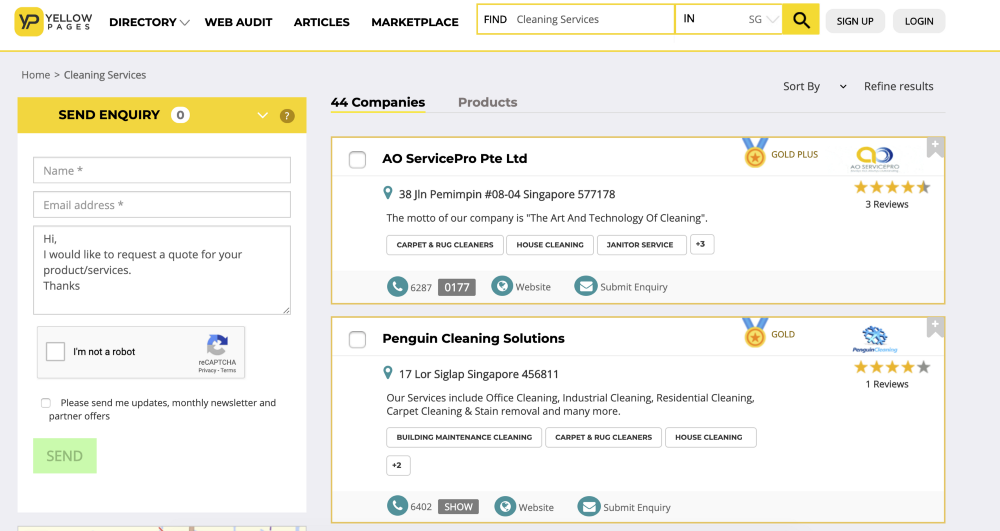
比如说,我们想得到公司地址和描述的数据。因此,对于Selenium,我们可以使用driver.findElement两次来分别检索地址和描述。更好的方法是使用驱动程序下载页面源代码,并使用BeautifulSoup提取所需的数据。总之,点击网站一次,而不是两次,以减少检测!
另一种情况是,当我们使用WebDriverWait(驱动程序、超时、poll_frequency=0.5、ignored_exception =None)来等待页面完全加载时,请记住将poll_frequency(调用之间的睡眠间隔)设置为较高的值,以最小化向页面发出请求的频率。更多的细节,你可以阅读这个官方文件!
技巧#2一旦一条记录被抓取,就将数据写入csv
以前当我抓取网站时,我只会输出一次记录——当所有记录都被抓取时。然而,这种方法可能不是完成任务的最聪明的方法。
相反,还有一种方法,刮取一个记录后,您将需要写入该文件,这样,当出现问题(例如你的电脑停止运行,或者程序因为错误而停止),你可以从网站出现问题的位置,重新开始你的爬虫/刮取:)

对于我来说,我通常使用python writerow函数将记录写入输出文件,这样我就可以从网站开始,如果我的scraper停止了,我就不需要重新刮除以前废弃的所有数据。
技巧#3减少被网站屏蔽的次数

有很多方法可以实现这些东西,这样爬行器或抓取器就不会被阻塞,但是一个好的爬行框架可以减少你实现它们的工作量。
我使用的主库是Request、Scrapy或Selenium。您可以参考这个链接来比较Scrapy和Selenium。我更喜欢Scrapy,因为它已经实现了一些减少被网站拦截的方法。
1、遵守robots.txt,在抓取网站之前,请务必检查文件。
2、使用已经存在于Scrapy框架中的下载延迟或自动节流机制,使您的scraper/crawler变慢。
3、最好的方法是轮换几个IP和用户代理来掩盖您的请求。
4、如果你使用的是scrapy-splash或selenium,随机点击和滚动有助于模仿人类行为。
有关详细信息,请参阅以下链接:
https://www.scrapehero.com/how-to-prevent-getting-blacklisted-while-scraping/
技巧#4通过API检索数据

例如Twitter。你可以抓取网站或者使用他们的API。通过API访问他们的数据,而不是跨过障碍,绝对会让你的生活更轻松!
技巧#5搜索谷歌缓存的网站而不是原始网站
以https://www.investment.com/为例:
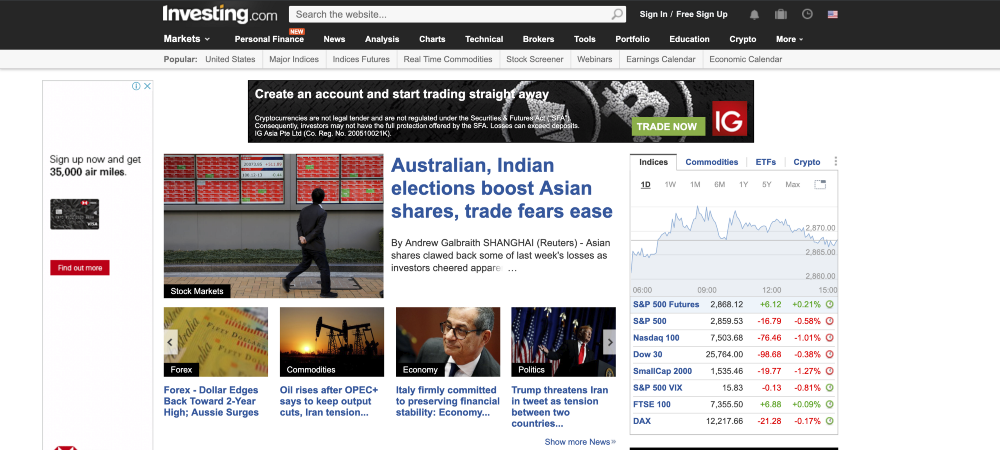
您可以访问缓存版本,如下所示:
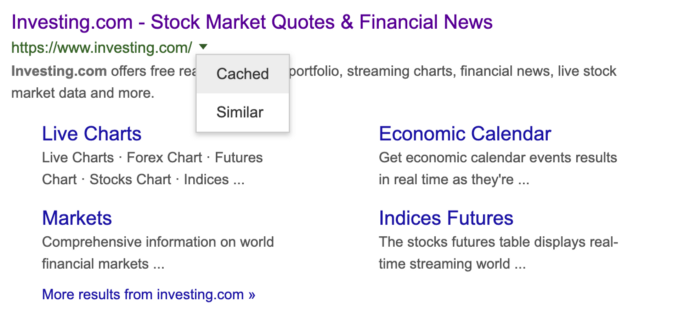
你将无法通过抓取缓存的网站而不是网站来获取最新的数据。然而,如果网站的数据仅仅改变几周甚至几个月,那么抓取谷歌缓存网站将是一个更明智的选择。
有关谷歌缓存的更多信息,请访问以下网站:https://blog.hubspot.com/marketing/google-cache
原文链接:https://towardsdatascience.com/https-towardsdatascience-com-5-tips-to-create-a-more-reliable-web-crawler-3efb6878f8db

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消