











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






(Keras)优化学习率提高模型性能
2019年08月25日 由 sunlei 发表
430424
0
学习率是一个超参数,它控制每次更新模型权重时响应估计错误而更改模型的程度。选择学习率具有挑战性,因为很小的值可能会导致很长的训练过程被卡住,而非常大的值可能会导致学习一组次优权重过快或训练过程不稳定。
我们使用转移学习将经过训练的机器学习模型应用于不同但相关的任务。这在深度学习中很有效,深度学习使用由层组成的神经网络。尤其是在计算机视觉中,这些网络的早期层倾向于学会识别更一般的特性。例如,它们检测边缘、梯度等。
这是一种在计算机视觉任务中产生更好结果的行之有效的方法。大多数预训练的架构(resnet、vgg、inception等)都是在imagenet上训练的,并且根据数据与imagenet上的图像的相似性,这些权重需要或多或少地改变。
在fast.ai课程中,Jeremy Howard探索了不同的学习速率策略,以提高模型的速度和准确性。
差分学习背后的直觉来自这样一个事实:虽然对预先训练的模型进行了微调,但靠近输入的层更有可能学习到更一般的特性。因此,我们不想改变太多。但是,当我们深入到模型中时,我们希望在更大程度上修改权重,以便适应手头的任务/数据。
“差分学习率”一词意味着在网络的不同部分使用不同的学习率,初始层的学习率较低,后期逐渐提高学习率。
[caption id="attachment_43284" align="aligncenter" width="898"]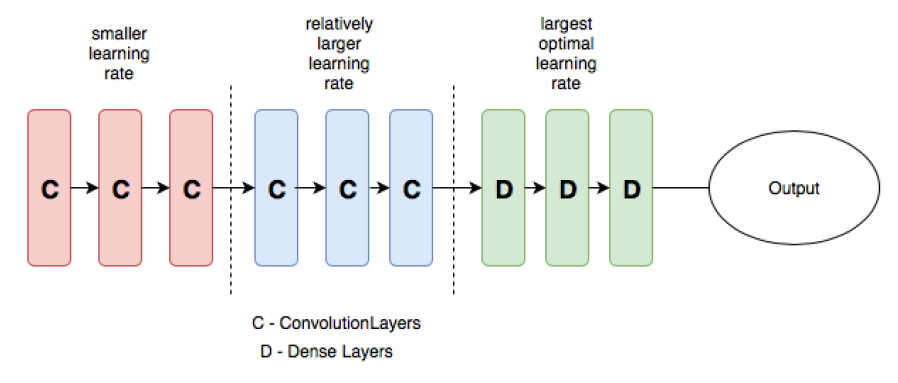 带DI的CNN示例[/caption]
带DI的CNN示例[/caption]
在Keras中实现差异学习率,为了在Keras中实现差异学习,需要修改优化器源代码。



[caption id="attachment_43288" align="aligncenter" width="866"]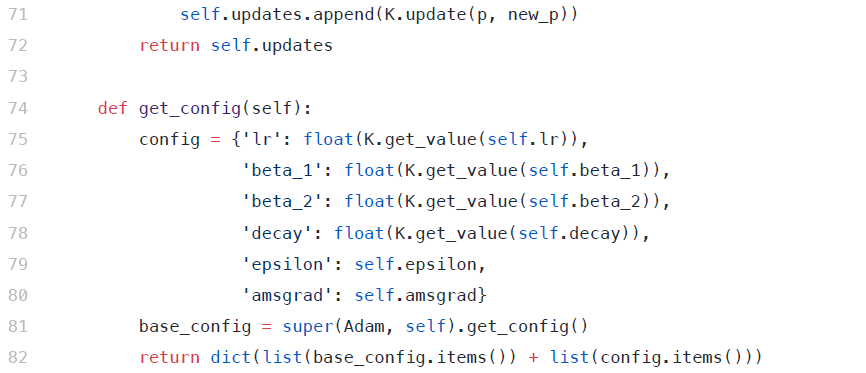 keras中的Adam优化器源代码[/caption]
keras中的Adam优化器源代码[/caption]
我们修改上述源代码,以包含以下内容-
修改后的函数为:
1、拆分层:拆分层1和拆分层2是分别进行第一个和第二个拆分的层的名称。
2、参数lr被修改为接受一个学习率列表-接受3个学习率列表(因为架构分为3个不同的部分)
在更新每一层的学习速率时,初始代码将迭代所有层,并为其分配一个学习速率。我们将此更改为包含不同层次的不同学习率

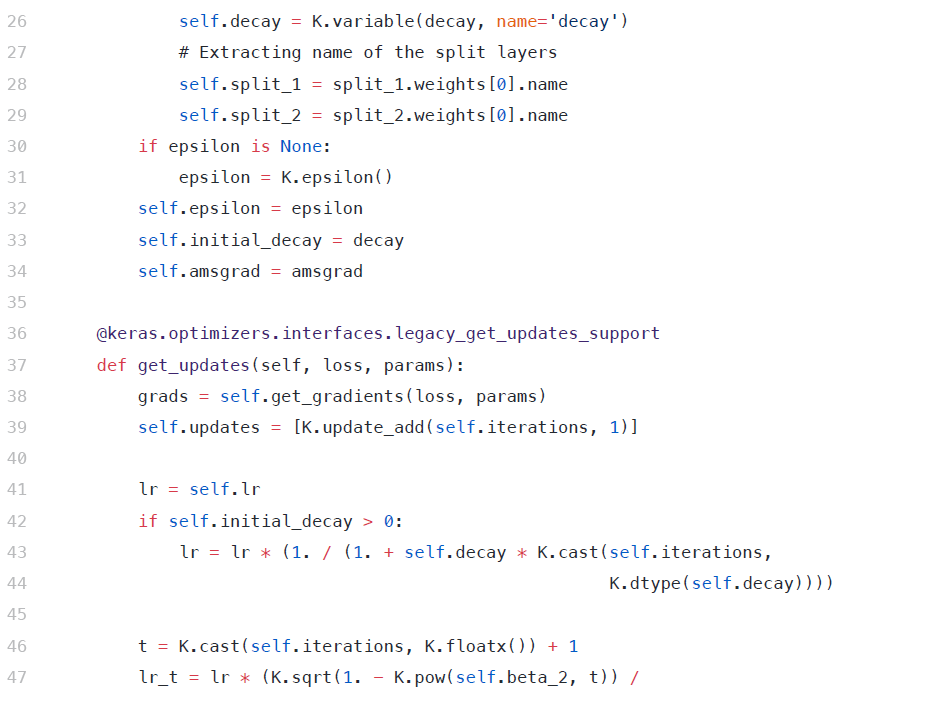


[caption id="attachment_43293" align="aligncenter" width="834"] 使用Di更新优化器代码[/caption]
使用Di更新优化器代码[/caption]
对于每一批随机梯度下降(SGD),理想情况下网络应该越来越接近损失的全局最小值。因此,随着训练的进行,降低学习速度是有意义的,这样算法就不会过冲,并且尽可能地接近最小值。通过余弦退火,我们可以通过一个余弦函数来降低学习速度。
[caption id="attachment_43294" align="aligncenter" width="933"]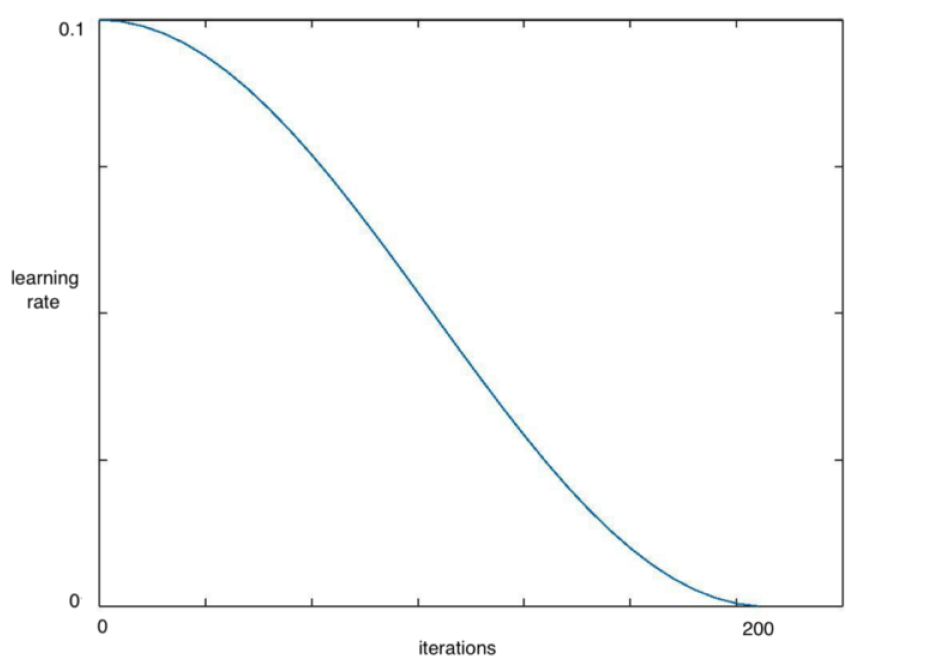 在包含200次迭代的历代中降低学习速度[/caption]
在包含200次迭代的历代中降低学习速度[/caption]
SGDR是Loshchilov和Hutter[5]在他们的论文《SGDR:带重新启动的随机梯度下降》中引入的学习速率退火的最新变体。在这种技术中,我们不时地突然提高学习速度。下面是一个例子,重置学习率为三个均匀间隔的间隔余弦退火。
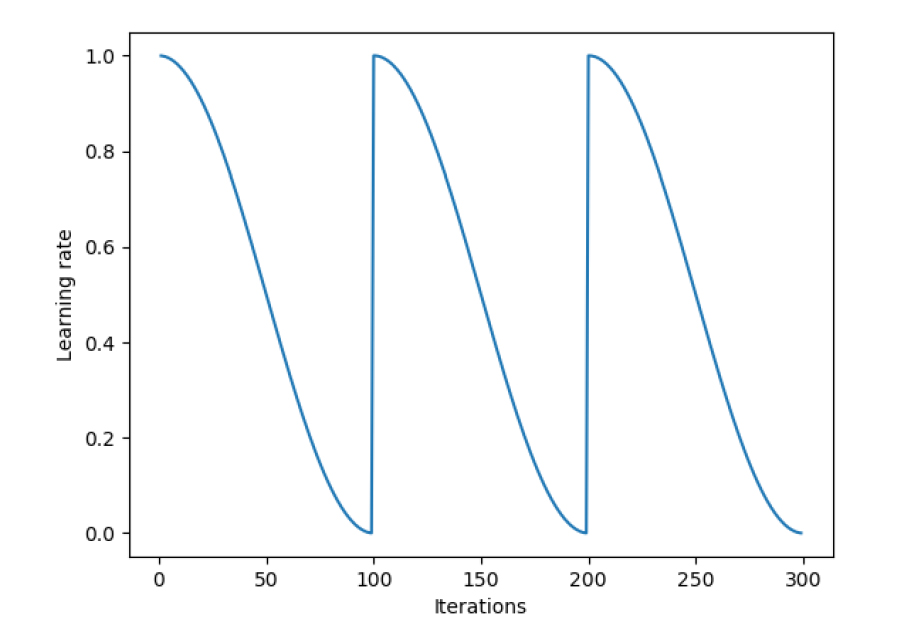
突然提高学习速率的基本原理是,这样做时,梯度下降不会停留在任何局部极小值上,并可能“跳跃”出它,以达到全局极小值。
每次学习率下降到最小值(上图中每100次迭代),我们都称之为循环。作者还建议通过一些常数因子使下一个周期比前一个周期长。
[caption id="attachment_43296" align="aligncenter" width="981"]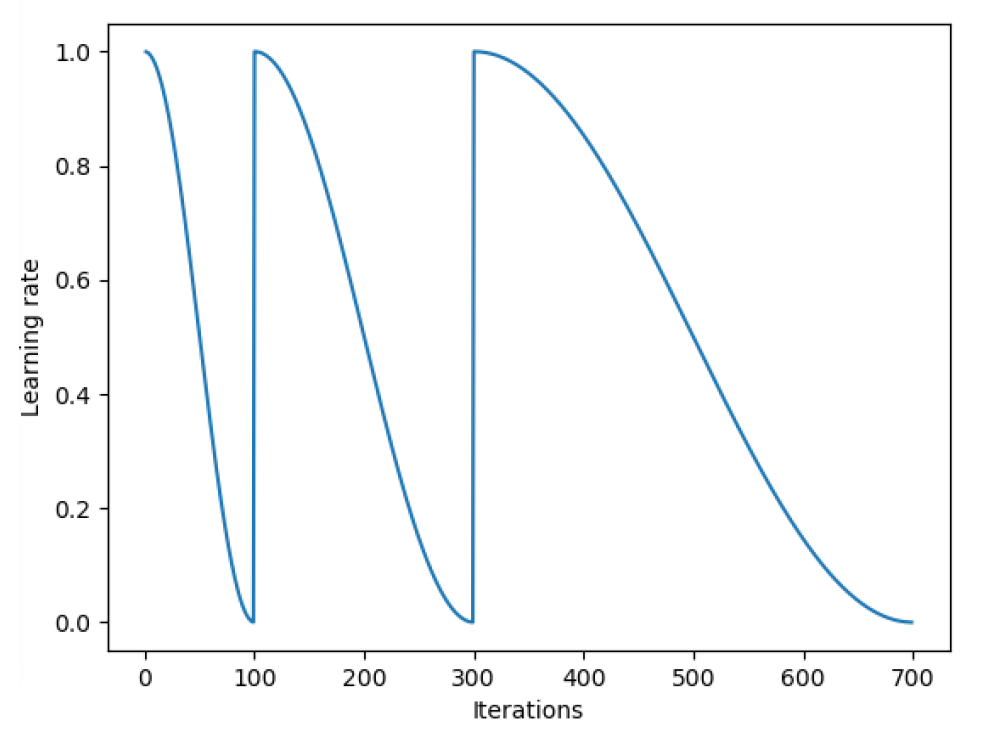 每一个周期完成的时间是前一个周期的两倍[/caption]
每一个周期完成的时间是前一个周期的两倍[/caption]
使用Keras回调,我们可以更新学习率以跟踪特定功能。我们可以参考已经实施周期性学习的回购协议。



以上就是我今天想要分享的内容,希望能帮助到大家。
原文链接:https://towardsdatascience.com/exploring-learning-rates-to-improve-model-performance-in-keras-e37f5e63f16c
转移学习
我们使用转移学习将经过训练的机器学习模型应用于不同但相关的任务。这在深度学习中很有效,深度学习使用由层组成的神经网络。尤其是在计算机视觉中,这些网络的早期层倾向于学会识别更一般的特性。例如,它们检测边缘、梯度等。
这是一种在计算机视觉任务中产生更好结果的行之有效的方法。大多数预训练的架构(resnet、vgg、inception等)都是在imagenet上训练的,并且根据数据与imagenet上的图像的相似性,这些权重需要或多或少地改变。
在fast.ai课程中,Jeremy Howard探索了不同的学习速率策略,以提高模型的速度和准确性。
1、差异学习
差分学习背后的直觉来自这样一个事实:虽然对预先训练的模型进行了微调,但靠近输入的层更有可能学习到更一般的特性。因此,我们不想改变太多。但是,当我们深入到模型中时,我们希望在更大程度上修改权重,以便适应手头的任务/数据。
“差分学习率”一词意味着在网络的不同部分使用不同的学习率,初始层的学习率较低,后期逐渐提高学习率。
[caption id="attachment_43284" align="aligncenter" width="898"]
带DI的CNN示例[/caption]在Keras中实现差异学习率,为了在Keras中实现差异学习,需要修改优化器源代码。
[caption id="attachment_43288" align="aligncenter" width="866"]
keras中的Adam优化器源代码[/caption]我们修改上述源代码,以包含以下内容-
修改后的函数为:
1、拆分层:拆分层1和拆分层2是分别进行第一个和第二个拆分的层的名称。
2、参数lr被修改为接受一个学习率列表-接受3个学习率列表(因为架构分为3个不同的部分)
在更新每一层的学习速率时,初始代码将迭代所有层,并为其分配一个学习速率。我们将此更改为包含不同层次的不同学习率
[caption id="attachment_43293" align="aligncenter" width="834"]
使用Di更新优化器代码[/caption]2、带重启的随机梯度下降(SGDR)
对于每一批随机梯度下降(SGD),理想情况下网络应该越来越接近损失的全局最小值。因此,随着训练的进行,降低学习速度是有意义的,这样算法就不会过冲,并且尽可能地接近最小值。通过余弦退火,我们可以通过一个余弦函数来降低学习速度。
[caption id="attachment_43294" align="aligncenter" width="933"]
在包含200次迭代的历代中降低学习速度[/caption]SGDR是Loshchilov和Hutter[5]在他们的论文《SGDR:带重新启动的随机梯度下降》中引入的学习速率退火的最新变体。在这种技术中,我们不时地突然提高学习速度。下面是一个例子,重置学习率为三个均匀间隔的间隔余弦退火。
突然提高学习速率的基本原理是,这样做时,梯度下降不会停留在任何局部极小值上,并可能“跳跃”出它,以达到全局极小值。
每次学习率下降到最小值(上图中每100次迭代),我们都称之为循环。作者还建议通过一些常数因子使下一个周期比前一个周期长。
[caption id="attachment_43296" align="aligncenter" width="981"]
每一个周期完成的时间是前一个周期的两倍[/caption]在Keras中实现SGDR
使用Keras回调,我们可以更新学习率以跟踪特定功能。我们可以参考已经实施周期性学习的回购协议。
以上就是我今天想要分享的内容,希望能帮助到大家。
原文链接:https://towardsdatascience.com/exploring-learning-rates-to-improve-model-performance-in-keras-e37f5e63f16c

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
创建更可靠网络爬虫的5个技巧








广告


写评论取消
回复取消