











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何在Python中保存ARIMA时间序列预测模型
2017年08月12日 由 yuxiangyu 发表
779093
0
自回归移动平均模型(ARIMA)是一种常用于时间序列分析和预测的线性模型。
statsmodels库提供了Python中使用ARIMA的实现。ARIMA模型可以保存到文件中,以便以后对新数据进行预测。在当前版本的statsmodels库中有一个bug,它阻止了保存的模型被加载。
在本教程中,你将了解如何诊断并解决此问题。
让我们开始吧。

首先,让我们看看标准时间序列数据集,我们可以用statsmodels ARIMA实现来理解这个问题
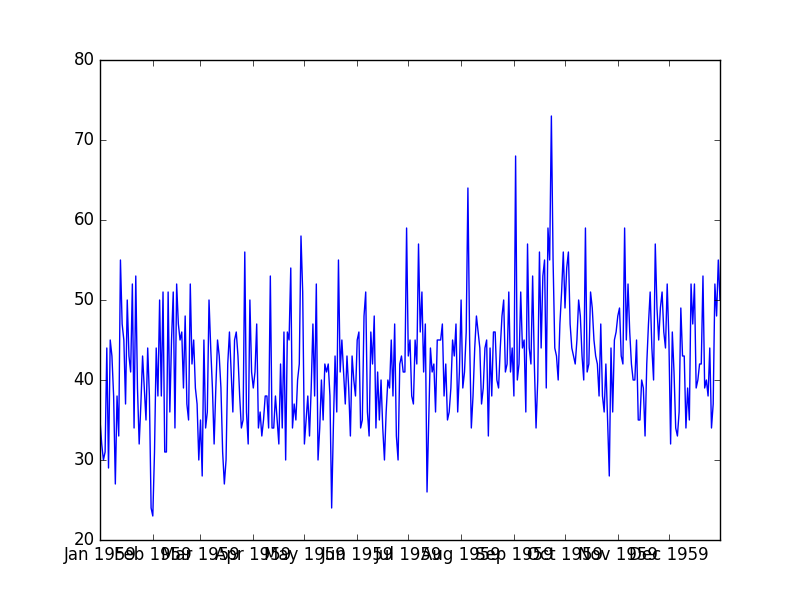
这个每日的女婴出生数据集描述了1959年加利福尼亚每日出生的女婴数量。
它的单位是数值型,有365个观察值。数据集的来源于Newton (1988)。
你可以从DataMarket网站了解更多信息并下载数据集。
下载数据集并将其放在你当前的工作目录中,文件名为 “ daily-total-female-births.csv ”。
以下的代码将加载并绘制数据集。
运行该示例加载数据库,并生成 Pandas 库中的 Series 对象,然后显示数据的折线图。
确认正在使用statsmodels库是最新版本。
你可以通过运行以下脚本来执行此操作:
运行脚本应该产生一个显示statsmodels 0.6或0.6.1的结果(目前更新到0.8,bug仍然存在)。
导出错误信息:
我们可以轻松地在每日女婴出生数据集上训练一个ARIMA模型。
下面的代码片段在数据集上训练了一个ARIMA(1,1,1)。
该model.fit()函数返回一个ARIMAResults对象,我们可以调用save()保存文件模型然后调用load()加载它。
运行此示例将训练模型并将其保存到文件中,没有遇到问题。
但当你尝试从文件加载模型时,就会报告错误。
错误信息如下:
那么我们该如何解决呢?
Zae Myung Kim在2016年9月发现并报告了这个错误。
你可以在这里阅读全文:
会发生这种错误是因为在statsmodels中尚未定义pickle(用于序列化Python对象的库)所需的函数。
在保存之前,必须在ARIMA模型中定义__getnewargs__函数,它定义构造对象所需的参数。
我们可以解决这个问题。修复涉及两件事情:
Zae Myung Kim在他的错误报告中提供了一个功能的例子,我们可以直接使用它:
Python允许我们对一个对象使用猴子补丁(monkey patch),像statsmodels库做的那样。
我们可以使用赋值在现有对象上定义一个新的函数。
我们可以在ARIMA对象上的__getnewargs__函数中执行以下操作:
在Python中使用猴子补丁训练、保存和加载ARIMA模型的完整示例如下:
运行该示例现在成功加载模型没有报错。
在这篇文章中,你学会了如何解决statsmodels ARIMA实现中的阻止你将ARIMA模型保存并加载到文件的bug。
你学会了如何编写一个猴子补丁来解决这个bug,以及如何证明它已经被修复了。
statsmodels库提供了Python中使用ARIMA的实现。ARIMA模型可以保存到文件中,以便以后对新数据进行预测。在当前版本的statsmodels库中有一个bug,它阻止了保存的模型被加载。
在本教程中,你将了解如何诊断并解决此问题。
让我们开始吧。
每日女婴出生数据集
首先,让我们看看标准时间序列数据集,我们可以用statsmodels ARIMA实现来理解这个问题
这个每日的女婴出生数据集描述了1959年加利福尼亚每日出生的女婴数量。
它的单位是数值型,有365个观察值。数据集的来源于Newton (1988)。
你可以从DataMarket网站了解更多信息并下载数据集。
下载数据集并将其放在你当前的工作目录中,文件名为 “ daily-total-female-births.csv ”。
以下的代码将加载并绘制数据集。
from pandas import Series
from matplotlib import pyplot
series = Series.from_csv('daily-total-female-births.csv', header=0)
series.plot()
pyplot.show()
运行该示例加载数据库,并生成 Pandas 库中的 Series 对象,然后显示数据的折线图。
Python环境
确认正在使用statsmodels库是最新版本。
你可以通过运行以下脚本来执行此操作:
import statsmodels
print('statsmodels: %s' % statsmodels.__version__)
运行脚本应该产生一个显示statsmodels 0.6或0.6.1的结果(目前更新到0.8,bug仍然存在)。
statsmodels: 0.6.1
导出错误信息:
AttributeError: 'ARIMA' object has no attribute 'dates'
ARIMA模型保存错误
我们可以轻松地在每日女婴出生数据集上训练一个ARIMA模型。
下面的代码片段在数据集上训练了一个ARIMA(1,1,1)。
该model.fit()函数返回一个ARIMAResults对象,我们可以调用save()保存文件模型然后调用load()加载它。
from pandas import Series
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.tsa.arima_model import ARIMAResults
# load data
series = Series.from_csv('daily-total-female-births.csv', header=0)
# prepare data
X = series.values
X = X.astype('float32')
# fit model
model = ARIMA(X, order=(1,1,1))
model_fit = model.fit()
# save model
model_fit.save('model.pkl')
# load model
loaded = ARIMAResults.load('model.pkl')
运行此示例将训练模型并将其保存到文件中,没有遇到问题。
但当你尝试从文件加载模型时,就会报告错误。
Traceback (most recent call last):
File "...", line 16, in
loaded = ARIMAResults.load('model.pkl')
File ".../site-packages/statsmodels/base/model.py", line 1529, in load
return load_pickle(fname)
File ".../site-packages/statsmodels/iolib/smpickle.py", line 41, in load_pickle
return cPickle.load(fin)
TypeError: __new__() takes at least 3 arguments (1 given)
错误信息如下:
TypeError: __new__() takes at least 3 arguments (1 given)
那么我们该如何解决呢?
ARIMA模型保存Bug解决方法
Zae Myung Kim在2016年9月发现并报告了这个错误。
你可以在这里阅读全文:
会发生这种错误是因为在statsmodels中尚未定义pickle(用于序列化Python对象的库)所需的函数。
在保存之前,必须在ARIMA模型中定义__getnewargs__函数,它定义构造对象所需的参数。
我们可以解决这个问题。修复涉及两件事情:
- 定义适用于ARIMA对象的__getnewargs__函数的实现。
- 将新的函数添加到ARIMA。
Zae Myung Kim在他的错误报告中提供了一个功能的例子,我们可以直接使用它:
def __getnewargs__(self):
return ((self.endog),(self.k_lags, self.k_diff, self.k_ma))
Python允许我们对一个对象使用猴子补丁(monkey patch),像statsmodels库做的那样。
我们可以使用赋值在现有对象上定义一个新的函数。
我们可以在ARIMA对象上的__getnewargs__函数中执行以下操作:
ARIMA.__getnewargs__ = __getnewargs__
在Python中使用猴子补丁训练、保存和加载ARIMA模型的完整示例如下:
from pandas import Series
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.tsa.arima_model import ARIMAResults
# monkey patch around bug in ARIMA class
def __getnewargs__(self):
return ((self.endog),(self.k_lags, self.k_diff, self.k_ma))
ARIMA.__getnewargs__ = __getnewargs__
# load data
series = Series.from_csv('daily-total-female-births.csv', header=0)
# prepare data
X = series.values
X = X.astype('float32')
# fit model
model = ARIMA(X, order=(1,1,1))
model_fit = model.fit()
# save model
model_fit.save('model.pkl')
# load model
loaded = ARIMAResults.load('model.pkl')
运行该示例现在成功加载模型没有报错。
总结
在这篇文章中,你学会了如何解决statsmodels ARIMA实现中的阻止你将ARIMA模型保存并加载到文件的bug。
你学会了如何编写一个猴子补丁来解决这个bug,以及如何证明它已经被修复了。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消