











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Pandas时序数据处理入门
2019年09月05日 由 sunlei 发表
569389
0

作为一个几乎每天处理时间序列数据的人,我发现pandas Python包对于时间序列的操作和分析非常有用。
使用pandas操作时间序列数据的基本介绍开始前需要您已经开始进行时间序列分析。因为我们的具体目标是向你展示下面这些:
- 1、创建一个日期范围
- 2、处理时间戳数据
- 3、将字符串数据转换为时间戳
- 4、数据帧中索引和切片时间序列数据
- 5、重新采样不同时间段的时间序列汇总/汇总统计数据
- 6、计算滚动统计数据,如滚动平均
- 7、处理丢失的数据
- 8、了解unix/epoch时间的基本知识
- 9、了解时间序列数据分析的常见陷阱
让我们开始吧。如果想要处理已有的实际数据,可以从使用pandas read_csv将文件读入数据帧开始,但是我们将从处理生成的数据开始。
首先导入我们将使用的库,然后使用它们创建日期范围
import pandas as pd
from datetime import datetime
import numpy as npdate_rng = pd.date_range(start='1/1/2018', end='1/08/2018', freq='H')
此日期范围具有每小时频率的时间戳。如果我们调用date_rng,我们会看到它如下所示:
DatetimeIndex(['2018-01-01 00:00:00', '2018-01-01 01:00:00',
'2018-01-01 02:00:00', '2018-01-01 03:00:00',
'2018-01-01 04:00:00', '2018-01-01 05:00:00',
'2018-01-01 06:00:00', '2018-01-01 07:00:00',
'2018-01-01 08:00:00', '2018-01-01 09:00:00',
...
'2018-01-07 15:00:00', '2018-01-07 16:00:00',
'2018-01-07 17:00:00', '2018-01-07 18:00:00',
'2018-01-07 19:00:00', '2018-01-07 20:00:00',
'2018-01-07 21:00:00', '2018-01-07 22:00:00',
'2018-01-07 23:00:00', '2018-01-08 00:00:00'],
dtype='datetime64[ns]', length=169, freq='H')
我们可以检查第一个元素的类型:
type(date_rng[0])
#returns
pandas._libs.tslib.Timestamp
让我们用时间戳数据创建一个示例数据框架,并查看前15个元素:
df = pd.DataFrame(date_rng, columns=['date'])
df['data'] = np.random.randint(0,100,size=(len(date_rng)))
df.head(15)
如果我们想做时间序列操作,我们需要一个日期时间索引,以便我们的数据帧在时间戳上建立索引。
将数据帧索引转换为datetime索引,然后显示第一个元素:
df['datetime'] = pd.to_datetime(df['date'])
df = df.set_index('datetime')
df.drop(['date'], axis=1, inplace=True)
df.head()
如果数据中的“时间”戳实际上是字符串类型,而不是数字类型呢?让我们将date_rng转换为字符串列表,然后将字符串转换为时间戳。
string_date_rng = [str(x) for x in date_rng]
string_date_rng
#returns['2018-01-01 00:00:00',
'2018-01-01 01:00:00',
'2018-01-01 02:00:00',
'2018-01-01 03:00:00',
'2018-01-01 04:00:00',
'2018-01-01 05:00:00',
'2018-01-01 06:00:00',
'2018-01-01 07:00:00',
'2018-01-01 08:00:00',
'2018-01-01 09:00:00',...
我们可以通过推断字符串的格式将其转换为时间戳,然后查看这些值:
timestamp_date_rng = pd.to_datetime(string_date_rng, infer_datetime_format=True)
timestamp_date_rng
#returnsDatetimeIndex(['2018-01-01 00:00:00', '2018-01-01 01:00:00',
'2018-01-01 02:00:00', '2018-01-01 03:00:00',
'2018-01-01 04:00:00', '2018-01-01 05:00:00',
'2018-01-01 06:00:00', '2018-01-01 07:00:00',
'2018-01-01 08:00:00', '2018-01-01 09:00:00',
...
'2018-01-07 15:00:00', '2018-01-07 16:00:00',
'2018-01-07 17:00:00', '2018-01-07 18:00:00',
'2018-01-07 19:00:00', '2018-01-07 20:00:00',
'2018-01-07 21:00:00', '2018-01-07 22:00:00',
'2018-01-07 23:00:00', '2018-01-08 00:00:00'],
dtype='datetime64[ns]', length=169, freq=None)
但是如果我们需要转换一个唯一的字符串格式呢?
让我们创建一个任意的字符串日期列表,并将其转换为时间戳:
string_date_rng_2 = ['June-01-2018', 'June-02-2018', 'June-03-2018']
timestamp_date_rng_2 = [datetime.strptime(x,'%B-%d-%Y') for x in string_date_rng_2]
timestamp_date_rng_2
#returns
[datetime.datetime(2018, 6, 1, 0, 0),
datetime.datetime(2018, 6, 2, 0, 0),
datetime.datetime(2018, 6, 3, 0, 0)]
如果我们把它放入一个数据帧中,它会是什么样子?
df2 = pd.DataFrame(timestamp_date_rng_2, columns=['date'])
df2
回到我们最初的数据框架,让我们通过解析时间戳索引来查看数据:
假设我们只想查看日期为每月2日的数据,我们可以使用如下索引。
df[df.index.day == 2]
顶部是这样的:
我们还可以通过数据帧的索引直接调用要查看的日期:
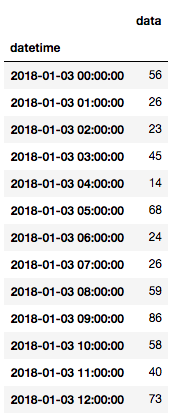
df['2018-01-03']
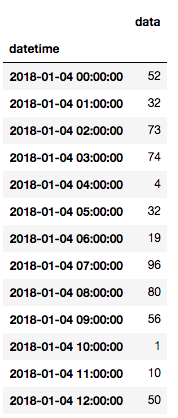
在特定日期之间选择数据如何?
df['2018-01-04':'2018-01-06']
我们已经填充的基本数据帧为我们提供了每小时频率的数据,但是我们可以以不同的频率对数据重新采样,并指定我们希望如何计算新采样频率的汇总统计。我们可以按照下面的示例,以日频率而不是小时频率,获取数据的最小值、最大值、平均值、总和等,其中我们计算数据的日平均值:
df.resample('D').mean()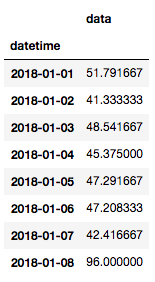
窗口统计数据,比如滚动平均值或滚动和呢?
让我们在原始df中创建一个新列,该列计算3个窗口期间的滚动和,然后查看数据帧的顶部:
df['rolling_sum'] = df.rolling(3).sum()
df.head(10)
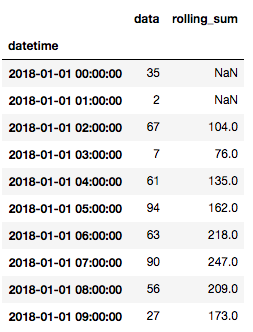
我们可以看到,这是正确的计算,只有当有三个周期可以回顾时,它才开始具有有效值。
这是一个很好的机会,可以看到当处理丢失的数据值时,我们如何向前或向后填充数据。
这是我们的df,但有一个新的列,采取滚动和和回填数据:
df['rolling_sum_backfilled'] =
df['rolling_sum'].fillna(method='backfill'
df.head(10)
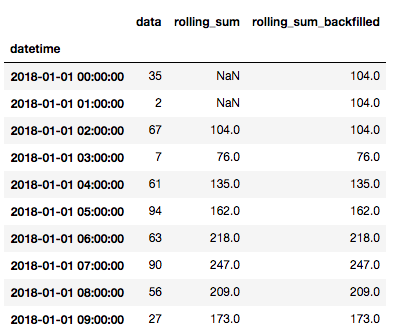
能够用实际值(如时间段的平均值)填充丢失的数据通常很有用,但请始终记住,如果您正在处理时间序列问题并希望数据真实,则不应像查找未来和获取你在那个时期永远不会拥有的信息。您可能希望更频繁地向前填充数据,而不是向后填充。
在处理时间序列数据时,可能会遇到UNIX时间中的时间值。Unix Time,也称为Epoch Time是自1970年1月1日星期四00:00:00协调世界时(UTC)以来经过的秒数。使用Unix时间有助于消除时间戳的歧义,这样我们就不会被时区、夏令时等混淆。
下面是一个时间t的例子,它是以Epoch Time表示的,并将unix/epoch时间转换为以UTC表示的常规时间戳:
epoch_t = 1529272655
real_t = pd.to_datetime(epoch_t, unit='s')
real_t
#returns
Timestamp('2018-06-17 21:57:35')
如果我想将以UTC为单位的时间转换为我自己的时区,我可以简单地执行以下操作:
real_t.tz_localize('UTC').tz_convert('US/Pacific')
#returns
Timestamp('2018-06-17 14:57:35-0700', tz='US/Pacific')有了这些基础知识,您应该可以使用时间序列数据。
以下是在处理时间序列数据时要记住的一些技巧和要避免的常见陷阱:
- 1、检查您的数据中是否有可能由特定地区的时间变化(如夏令时)引起的差异。
- 2、仔细跟踪时区-让其他人通过查看您的代码,了解您的数据所在的时区,并考虑转换为UTC或标准值,以保持数据的标准化。
- 3、丢失的数据可能经常发生-确保您记录了您的清洁规则,并且考虑到不回填您在采样时无法获得的信息。
- 4、请记住,当您对数据重新取样或填写缺少的值时,您将丢失有关原始数据集的一定数量的信息。我建议您跟踪所有的数据转换,并跟踪数据问题的根本原因。
- 5、当您对数据重新取样时,最佳方法(平均值、最小值、最大值、和等等)将取决于您拥有的数据类型和取样方式。要考虑如何重新对数据取样以便进行分析。
原文链接:https://towardsdatascience.com/basic-time-series-manipulation-with-pandas-4432afee64ea

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消