











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Python/PyMC3/ArviZ贝叶斯统计实战(下)
2019年09月08日 由 sunlei 发表
12517
0
在上半部分中,我们了解了贝叶斯方法步骤和高斯推论,也将贝叶斯方法应用到一个实际问题中,今天我主要介绍贝叶斯在Python中实现最终的后验分布。
前文回顾:Python/PyMC3/ArviZ贝叶斯统计实战(上)
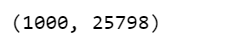
现在,ppc包含1000个生成的数据集(每个数据集包含25798个样本),每个数据集使用与后验不同的参数设置。
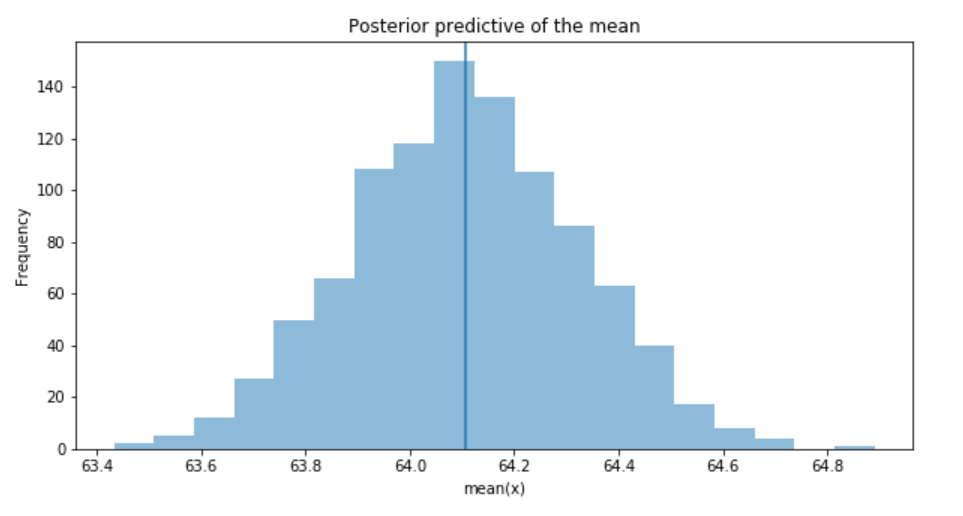
推断的平均值与实际的火车票价格平均值非常接近。
我们可能对不同票价类型下的价格比较感兴趣。我们将着重于估计效应的大小,即量化两类票价之间的差异。为了比较票价类别,我们将使用每种票价类型的平均值。因为我们是贝叶斯,所以我们将努力获得票价类别之间的均值差异的后验分布。
我们创建了三个变量:
群体比较问题的模型与以前的模型基本相同。唯一的区别在于,μ、σ是向量而不是标量变量。这意味着对于先验,我们传递一个形状参数,对于可能性,我们使用idx变量正确地索引平均值和sd变量:
对于6个组(票价类别),很难绘制每个组的μ和σ的跟踪图。因此,我们创建一个汇总表:
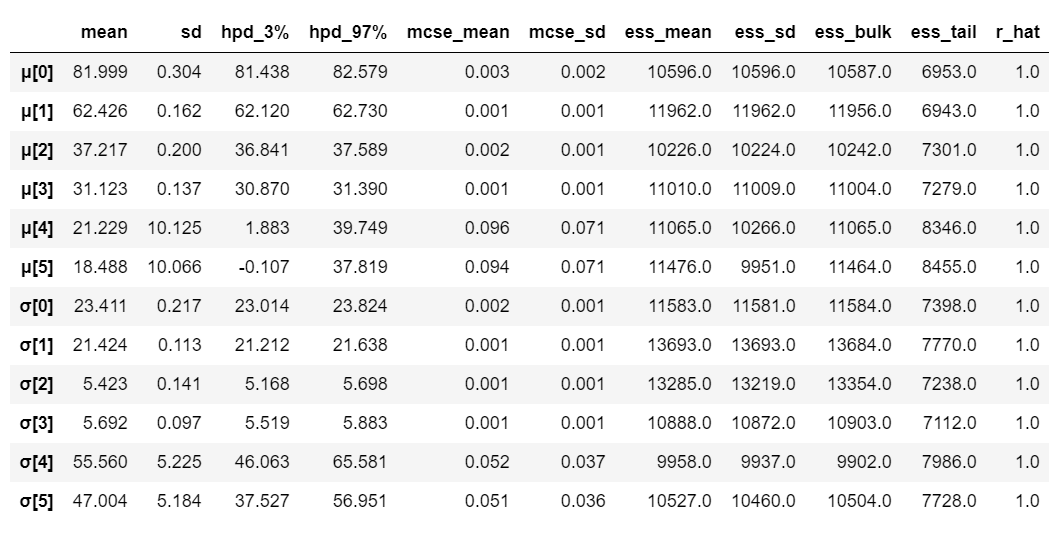
很明显,不同组别(即票价类别)的平均票价有显著差异。
为了更清楚地说明这一点,我们在不重复比较的情况下绘制了每个票价类别之间的差异。
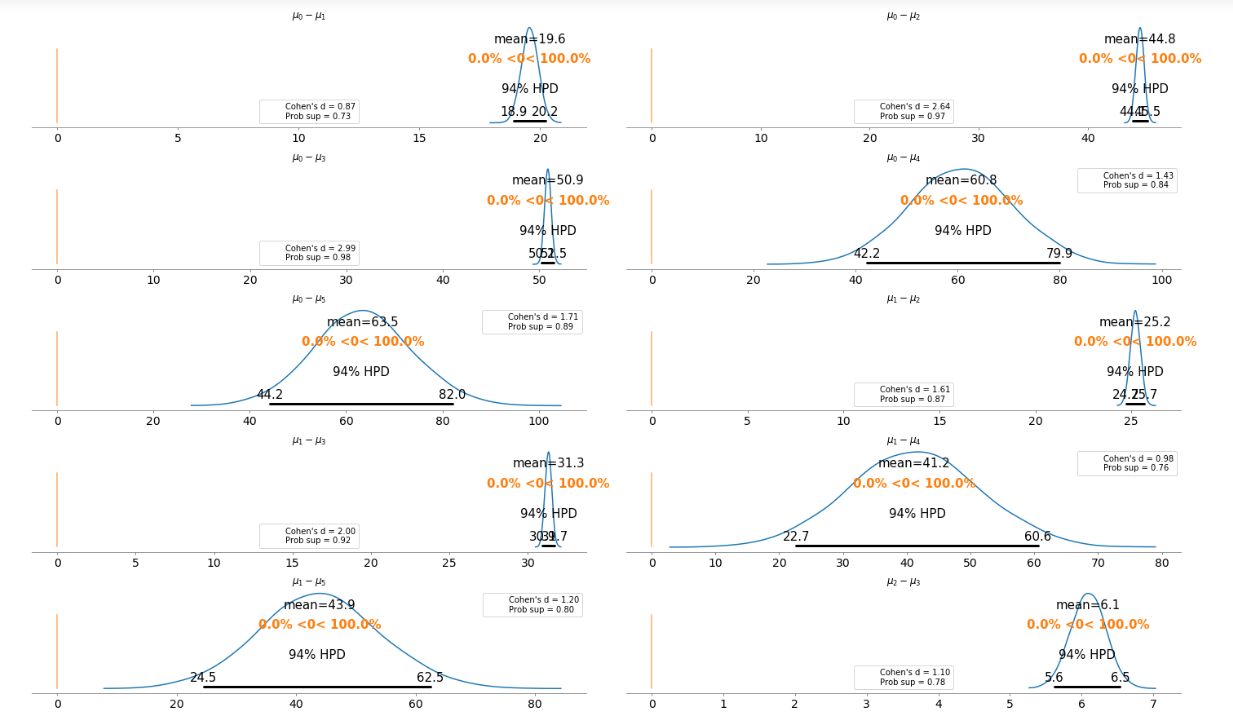 基本上,上面的图告诉我们,在上面的比较案例中,94%的HPD都没有包含0的参考值。这意味着对于所有的例子,我们可以排除0的差。6.1欧元到63.5欧元的平均差价足够大,顾客可以根据不同的票价类别购买机票。
基本上,上面的图告诉我们,在上面的比较案例中,94%的HPD都没有包含0的参考值。这意味着对于所有的例子,我们可以排除0的差。6.1欧元到63.5欧元的平均差价足够大,顾客可以根据不同的票价类别购买机票。
我们要建立一个模型来估计每种火车类型的火车票价格,同时估计所有火车类型的价格。这种类型的模型称为层次模型或多级模型。
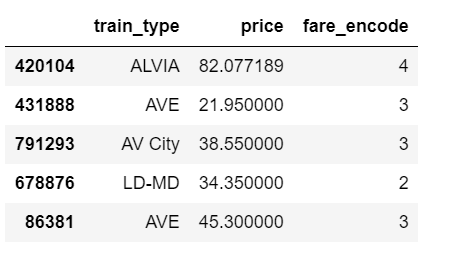
我们将建模的数据的相关部分如下所示。我们感兴趣的是不同的火车类型是否会影响票价。
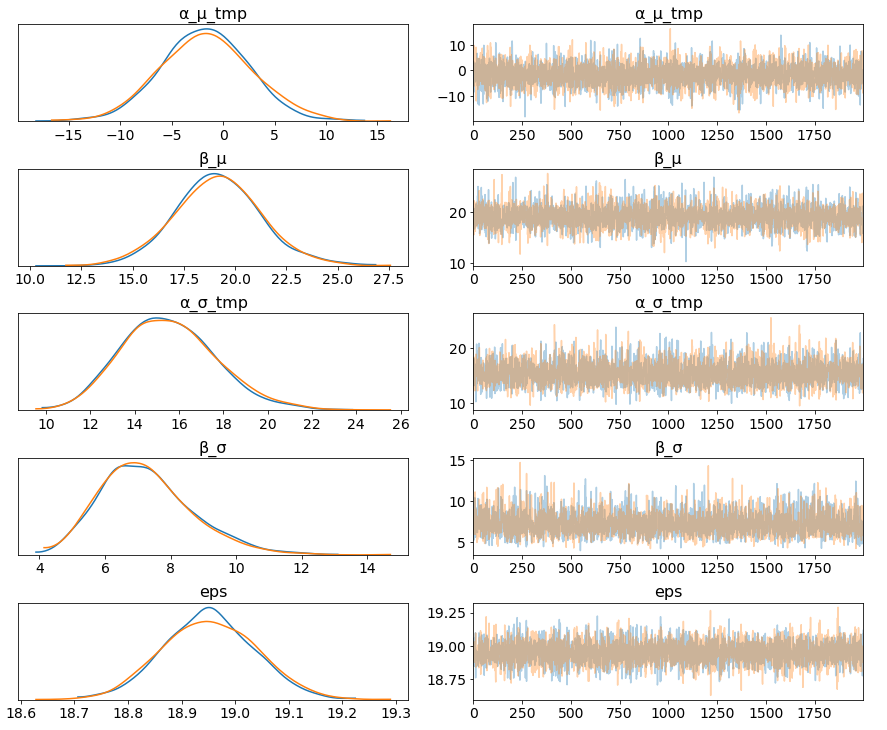
左列是高度的边缘后验信息,告诉我们“α_μ_tmp”组平均价格水平,“β_μ”告诉我们, 与票价类型“Adulto ida”和购买票价类别“Promo +”相比,购买票价类别“Promo +”显著提高了价格。与票价类型““Promo +”等(零下无质量)相比,价格明显降低。
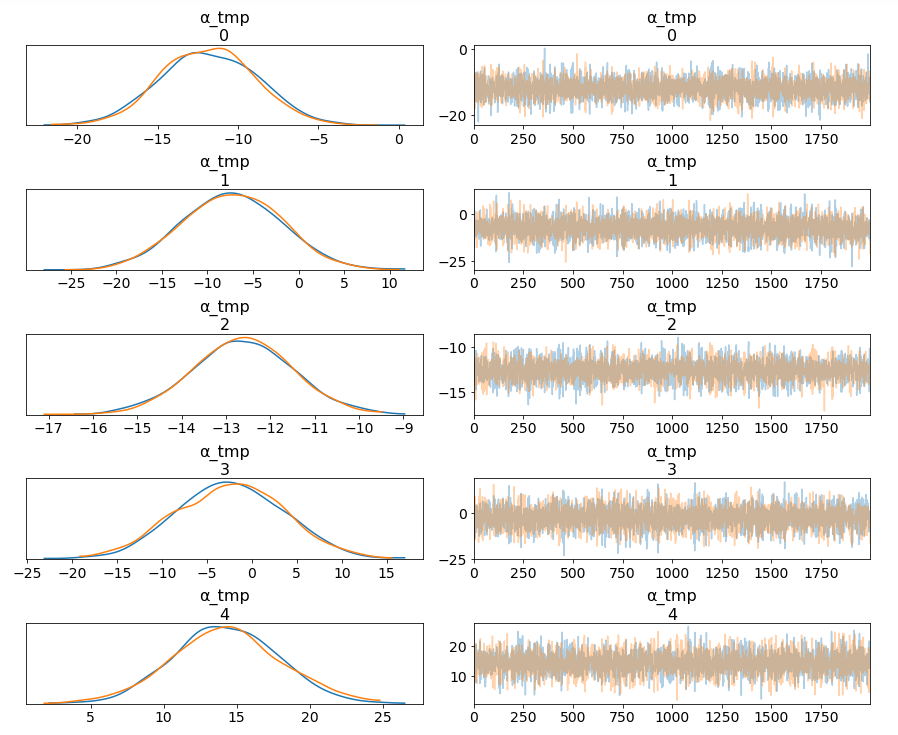
在16种火车类型中,我们可能想看看5种火车类型在票价方面的比较。从“α-tmp”的边缘可以看出,列车类型之间的价格差异很大;不同的宽度与我们对每个参数估计的置信度有关-每种列车类型的测量值越多,我们的置信度就越高。
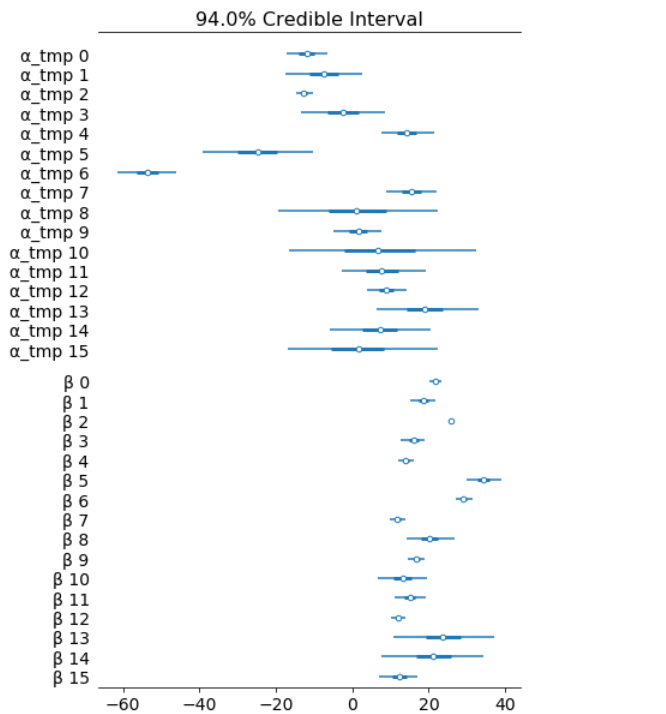
对我们的一些估计进行不确定性量化是贝叶斯模型的一个强大功能。对于不同类型的火车,我们有一个贝叶斯可信区间。
最后,我们要计算r的平方:

这篇文章的目的是学习、实践和解释贝叶斯,而不是从数据集中产生尽可能的最佳结果。否则,我们将直接使用XGBoost。
Jupyter notebook可以在Github上找到,享受这一周剩下的时间吧。
前文回顾:Python/PyMC3/ArviZ贝叶斯统计实战(上)
后预测检查
- 后验预测检验(PPCs)是验证模型的一种很好的方法。其思想是使用来自后验图的参数从模型中生成数据。
- 现在我们已经计算了后验,我们将说明如何使用模拟结果来推导预测。
- 下面的函数将从跟踪中随机抽取1000个参数样本。然后,对于每个样本,它将从该样本中μ和σ值指定的正态分布中提取25798个随机数。
ppc = pm.sample_posterior_predictive(trace_g, samples=1000, model=model_g)
np.asarray(ppc['y']).shape
现在,ppc包含1000个生成的数据集(每个数据集包含25798个样本),每个数据集使用与后验不同的参数设置。
_, ax = plt.subplots(figsize=(10, 5))
ax.hist([y.mean() for y in ppc['y']], bins=19, alpha=0.5)
ax.axvline(data.price.mean())
ax.set(title='Posterior predictive of the mean', xlabel='mean(x)', ylabel='Frequency');
推断的平均值与实际的火车票价格平均值非常接近。
分组比较
我们可能对不同票价类型下的价格比较感兴趣。我们将着重于估计效应的大小,即量化两类票价之间的差异。为了比较票价类别,我们将使用每种票价类型的平均值。因为我们是贝叶斯,所以我们将努力获得票价类别之间的均值差异的后验分布。
我们创建了三个变量:
- 价格变量,表示票价。
- idx变量,一个用数字编码票价类别的分类虚拟变量。
- 最后是组变量,包含票价类别的数量(6)
price = data['price'].values
idx = pd.Categorical(data['fare'],
categories=['Flexible', 'Promo', 'Promo +',
'Adulto ida', 'Mesa', 'Individual-Flexible']).codes
groups = len(np.unique(idx))
群体比较问题的模型与以前的模型基本相同。唯一的区别在于,μ、σ是向量而不是标量变量。这意味着对于先验,我们传递一个形状参数,对于可能性,我们使用idx变量正确地索引平均值和sd变量:
with pm.Model() as comparing_groups:
μ = pm.Normal('μ', mu=0, sd=10, shape=groups)
σ = pm.HalfNormal('σ', sd=10, shape=groups)
y = pm.Normal('y', mu=μ[idx], sd=σ[idx], observed=price)
trace_groups = pm.sample(5000, tune=5000)
对于6个组(票价类别),很难绘制每个组的μ和σ的跟踪图。因此,我们创建一个汇总表:
flat_fares = az.from_pymc3(trace=trace_groups)
fares_gaussian = az.summary(flat_fares)
fares_gaussian
很明显,不同组别(即票价类别)的平均票价有显著差异。
为了更清楚地说明这一点,我们在不重复比较的情况下绘制了每个票价类别之间的差异。
- Cohen’s d是比较两种方法的合适的效应大小。Cohen 's d通过标准差来引入每一组的变异性。
- 优势概率(ps)定义为随机从一个组取的数据点大于随机从另一个组取的数据点的概率。
dist = stats.norm()
_, ax = plt.subplots(5, 2, figsize=(20, 12), constrained_layout=True)
comparisons = [(i, j) for i in range(6) for j in range(i+1, 6)]
pos = [(k, l) for k in range(5) for l in (0, 1)]
for (i, j), (k, l) in zip(comparisons, pos):
means_diff = trace_groups['μ'][:, i] - trace_groups['μ'][:, j]
d_cohen = (means_diff / np.sqrt((trace_groups['σ'][:, i]**2 + trace_groups['σ'][:, j]**2) / 2)).mean()
ps = dist.cdf(d_cohen/(2**0.5))
az.plot_posterior(means_diff, ref_val=0, ax=ax[k, l])
ax[k, l].set_title(f'$\mu_{i}-\mu_{j}$')
ax[k, l].plot(
0, label=f"Cohen's d = {d_cohen:.2f}\nProb sup = {ps:.2f}", alpha=0)
ax[k, l].legend();
基本上,上面的图告诉我们,在上面的比较案例中,94%的HPD都没有包含0的参考值。这意味着对于所有的例子,我们可以排除0的差。6.1欧元到63.5欧元的平均差价足够大,顾客可以根据不同的票价类别购买机票。贝叶斯层次线性回归
我们要建立一个模型来估计每种火车类型的火车票价格,同时估计所有火车类型的价格。这种类型的模型称为层次模型或多级模型。
- 对分类变量进行编码。
- idx变量,一个分类虚拟变量,用于用数字对列车类型进行编码。
- 最后是组变量,以及列车类型的数量(16)
def replace_fare(fare):
if fare == 'Adulto ida':
return 1
elif fare == 'Promo +':
return 2
elif fare == 'Promo':
return 3
elif fare == 'Flexible':
return 4
elif fare == 'Individual-Flexible':
return 5
elif fare == 'Mesa':
return 6
data['fare_encode'] = data['fare'].apply(lambda x: replace_fare(x))
label_encoder = preprocessing.LabelEncoder()
data['train_type_encode']= label_encoder.fit_transform(data['train_type'])
train_type_names = data.train_type.unique()
train_type_idx = data.train_type_encode.values
n_train_types = len(data.train_type.unique())
data[['train_type', 'price', 'fare_encode']].head()
我们将建模的数据的相关部分如下所示。我们感兴趣的是不同的火车类型是否会影响票价。
层次模型
with pm.Model() as hierarchical_model:
# global model parameters
α_μ_tmp = pm.Normal('α_μ_tmp', mu=0., sd=100)
α_σ_tmp = pm.HalfNormal('α_σ_tmp', 5.)
β_μ = pm.Normal('β_μ', mu=0., sd=100)
β_σ = pm.HalfNormal('β_σ', 5.)
# train type specific model parameters
α_tmp = pm.Normal('α_tmp', mu=α_μ_tmp, sd=α_σ_tmp, shape=n_train_types)
# Intercept for each train type, distributed around train type mean
β = pm.Normal('β', mu=β_μ, sd=β_σ, shape=n_train_types)
# Model error
eps = pm.HalfCauchy('eps', 5.)
fare_est = α_tmp[train_type_idx] + β[train_type_idx]*data.fare_encode.values
# Data likelihood
fare_like = pm.Normal('fare_like', mu=fare_est, sd=eps, observed=data.price)
with hierarchical_model:
hierarchical_trace = pm.sample(2000, tune=2000, target_accept=.9)
pm.traceplot(hierarchical_trace, var_names=['α_μ_tmp', 'β_μ', 'α_σ_tmp', 'β_σ', 'eps']);
左列是高度的边缘后验信息,告诉我们“α_μ_tmp”组平均价格水平,“β_μ”告诉我们, 与票价类型“Adulto ida”和购买票价类别“Promo +”相比,购买票价类别“Promo +”显著提高了价格。与票价类型““Promo +”等(零下无质量)相比,价格明显降低。
pm.traceplot(hierarchical_trace, var_names=['α_tmp'], coords={'α_tmp_dim_0': range(5)});在16种火车类型中,我们可能想看看5种火车类型在票价方面的比较。从“α-tmp”的边缘可以看出,列车类型之间的价格差异很大;不同的宽度与我们对每个参数估计的置信度有关-每种列车类型的测量值越多,我们的置信度就越高。
对我们的一些估计进行不确定性量化是贝叶斯模型的一个强大功能。对于不同类型的火车,我们有一个贝叶斯可信区间。
az.plot_forest(hierarchical_trace, var_names=['α_tmp', 'β'], combined=True);
最后,我们要计算r的平方:
ppc = pm.sample_posterior_predictive(hierarchical_trace,
samples=2000, model=hierarchical_model)
az.r2_score(data.price.values, ppc['fare_like'])
这篇文章的目的是学习、实践和解释贝叶斯,而不是从数据集中产生尽可能的最佳结果。否则,我们将直接使用XGBoost。
Jupyter notebook可以在Github上找到,享受这一周剩下的时间吧。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消