











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌新探索,预测视频的人工智能——VideoBERT
2019年09月13日 由 TGS 发表
685132
0
 对人类来说,识别活动并预测接下来一段时间内可能发生的事情是很容易的,因为人类总是下意识地做出这样的预测,但机器要做到这一点就很困难,尤其是在标签数据相对缺乏的地方。(动作分类的人工智能系统通常会结合视频样本进行注释训练。)这就是谷歌研究团队推出VideoBERT的原因。VideoBERT是一个自我监督系统,可以处理各种代理任务,从未标记的视频中学习时间表示。
对人类来说,识别活动并预测接下来一段时间内可能发生的事情是很容易的,因为人类总是下意识地做出这样的预测,但机器要做到这一点就很困难,尤其是在标签数据相对缺乏的地方。(动作分类的人工智能系统通常会结合视频样本进行注释训练。)这就是谷歌研究团队推出VideoBERT的原因。VideoBERT是一个自我监督系统,可以处理各种代理任务,从未标记的视频中学习时间表示。正如研究人员在一篇论文和博客文章中解释的那样,VideoBERT的目标是发现随着时间推移而展开的事件和动作相对应的高级视听语义特征。“Peech往往与视频中的视觉信号在时间上保持一致,可以通过现成的自动语音识别(ASR)系统进行提取,这是自我监督的天然来源。”——谷歌研究员科学家Chen Sun和Cordelia Schmid。
为了定义能够引导模型学习活动关键特征的任务,团队使用了谷歌的BERT,这是一种自然语言人工智能系统,旨在为句子之间的关系建模。具体来说,他们使用图像帧结合语音,以识别系统的句子输出,根据特征相似性将帧转换为1.5秒的视觉标记,并将其与单词标记连接起来,最后,让VideoBERT来填补视觉文本句子中缺失的标记。
 研究人员对videobert进行了超过一百万个教学视频的培训,这些视频涉及烹饪、园艺和车辆维修等多个类别。为了确保它学会了视频和文本之间的语义对应,研究小组在一个烹饪视频数据集上测试了它的准确性,结果是喜人的,VideoBert成功预测了这样的情况:一碗面粉和可可粉在烤箱中烘烤后,可能会变成布朗尼或杯形蛋糕。并且,VideoBert还从视频和视频片段中生成了一组说明(例如食谱)来反映每一步所描述的内容。
研究人员对videobert进行了超过一百万个教学视频的培训,这些视频涉及烹饪、园艺和车辆维修等多个类别。为了确保它学会了视频和文本之间的语义对应,研究小组在一个烹饪视频数据集上测试了它的准确性,结果是喜人的,VideoBert成功预测了这样的情况:一碗面粉和可可粉在烤箱中烘烤后,可能会变成布朗尼或杯形蛋糕。并且,VideoBert还从视频和视频片段中生成了一组说明(例如食谱)来反映每一步所描述的内容。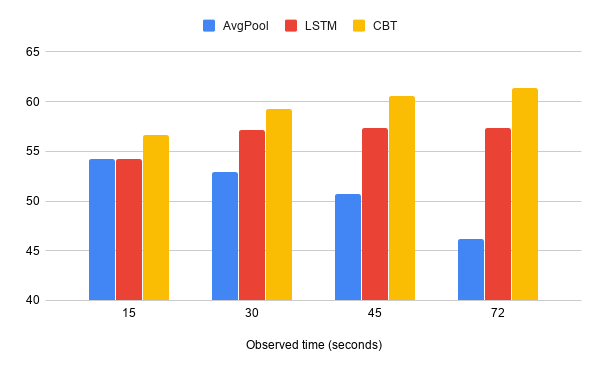 但可惜的是,VideoBERT并不是完美的,它的视觉标记往往会丢失细粒度的视觉信息,比如更小的物体和微妙的运动。在经过多次探索与实验后,研究小组用一个他们称为对比双向变压器(CBT)的模型去掉标记化步骤,从而解决了这个问题。
但可惜的是,VideoBERT并不是完美的,它的视觉标记往往会丢失细粒度的视觉信息,比如更小的物体和微妙的运动。在经过多次探索与实验后,研究小组用一个他们称为对比双向变压器(CBT)的模型去掉标记化步骤,从而解决了这个问题。研究人员表示,为了使VideoBERT更好地适应视频环境,他们的工作重心将会放在学习低水平的视觉特征和长期的时间表征上面。此外,他们计划扩大培训前视频的数量,让VideoBERT变得更加厉害。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消