











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






语言生成实战:自己训练能讲“人话”的神经网络(下)
2019年09月15日 由 sunlei 发表
762463
0
在昨天的学习当中,我们了解了培养一个会说话的语言生成模型所需要的如何创建数据集这一模块,今天我们继续学习构建语言生成模型。
前文链接:语言生成实战:自己训练能讲“人话”的神经网络(上)
我们将使用长短期记忆网络(LSTM)。LSTM的一个重要优点是能够理解对整个序列的依赖性,因此,句子的开头可能会对要预测的第15个单词产生影响。另一方面,递归神经网络(RNNs)只意味着依赖于网络的前一个状态,只有前一个词才能帮助预测下一个状态。如果选择RNNs,我们很快就会错过上下文,因此,LSTMs似乎是正确的选择。
由于训练可以非常(非常)(非常)(非常)(非常)(非常)(非常)(不开玩笑)长,我们将构建一个简单的1嵌入+ 1 LSTM层+ 1密集网络:
首先,我们添加一个嵌入层。我们将其传递到一个有100个神经元LSTM中,添加一个dropout来控制神经元的协同适应,最后是一个致密层。注意,我们在最后一层应用一个softmax激活函数来获得输出属于每个类的概率。所使用的损失是分类交叉熵,因为它是一个多类分类问题。
模型总结如下:

我们现在(终于)准备好训练模型了!
然后将开始训练模型:
在CPU上,一个时期大约需要8分钟。在GPU上(例如在Colab中), 您应该修改使用的Keras LSTM网络,因为它不能在GPU上使用。相反,您需要:
我倾向于在几个步骤中停止训练来进行样本预测,并控制给定几个交叉熵值的模型的质量。
以下是我的观察:
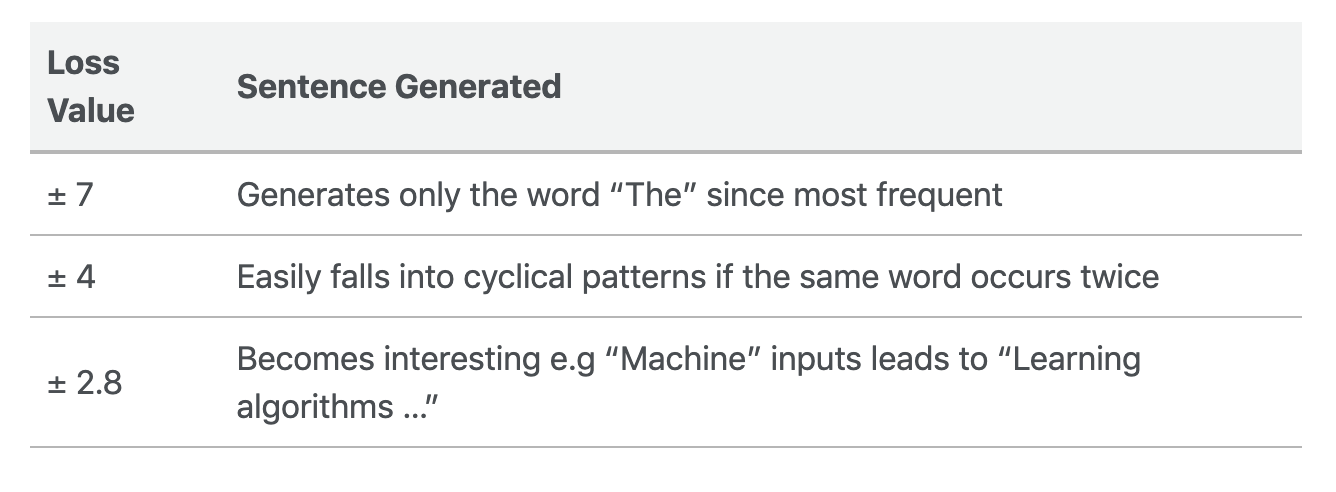
如果你读过这篇文章,这就是你所期待的:创造新的句子!要生成句子,我们需要对输入文本应用相同的转换。我们将建立一个循环,为给定的迭代次数生成下一个单词:
当损失在3.1左右时,以“谷歌”作为输入,生成如下句子:
谷歌是世界范围内产生的大量数据
这并没有什么实际意义,但它成功地将谷歌与大量数据的概念联系起来。这是相当令人印象深刻的,因为它仅仅依赖于单词的共现,而没有整合任何语法概念。
如果我们在训练中再等一段时间,让损失减小到2.5,然后输入“Random Forest”:
Random Forest是一个完全托管的服务,旨在支持大量初创企业的愿景基础设施
同样,生成的内容没有意义,但语法结构相当正确。
损失在大约50个时期后开始分化,并从未低于2.5。
我想我们已经达到了发展方法的极限:
同样,生成的东西没有任何意义,但是语法结构是相当正确的。
这种损失在大约50个时期之后就会出现分歧,而且从未低于2.5。
也就是说,我发现结果非常有趣,例如,经过训练的模型可以很容易地部署在Flask Web App上。
我希望这篇文章有用。我试图说明语言生成的主要概念、挑战和限制。与本文讨论的方法相比,更大的网络和更好的数据无疑是改进的来源。如有任何疑问或意见,请留言:)。
资料来源:
Kaggle Kernel : https://www.kaggle.com/shivamb/beginners-guide-to-text-generation-using-lstms
Originally published here: https://maelfabien.github.io/project/NLP_Gen/#generating-sequences
前文链接:语言生成实战:自己训练能讲“人话”的神经网络(上)
2.构建模型
我们将使用长短期记忆网络(LSTM)。LSTM的一个重要优点是能够理解对整个序列的依赖性,因此,句子的开头可能会对要预测的第15个单词产生影响。另一方面,递归神经网络(RNNs)只意味着依赖于网络的前一个状态,只有前一个词才能帮助预测下一个状态。如果选择RNNs,我们很快就会错过上下文,因此,LSTMs似乎是正确的选择。
a.模型架构
由于训练可以非常(非常)(非常)(非常)(非常)(非常)(非常)(不开玩笑)长,我们将构建一个简单的1嵌入+ 1 LSTM层+ 1密集网络:
def create_model(max_sequence_len, total_words):
input_len = max_sequence_len - 1
model = Sequential()
# Add Input Embedding Layer
model.add(Embedding(total_words, 10, input_length=input_len))
# Add Hidden Layer 1 - LSTM Layer
model.add(LSTM(100))
model.add(Dropout(0.1))
# Add Output Layer
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
return model
model = create_model(max_sequence_len, total_words)
model.summary()
首先,我们添加一个嵌入层。我们将其传递到一个有100个神经元LSTM中,添加一个dropout来控制神经元的协同适应,最后是一个致密层。注意,我们在最后一层应用一个softmax激活函数来获得输出属于每个类的概率。所使用的损失是分类交叉熵,因为它是一个多类分类问题。
模型总结如下:
b.训练模型
我们现在(终于)准备好训练模型了!
model.fit(X, y, batch_size=256, epochs=100, verbose=True)
然后将开始训练模型:
Epoch 1/10
164496/164496 [==============================] - 471s 3ms/step -
loss: 7.0687
Epoch 2/10
73216/164496 [============>.................] - ETA: 5:12 - loss:
7.0513
在CPU上,一个时期大约需要8分钟。在GPU上(例如在Colab中), 您应该修改使用的Keras LSTM网络,因为它不能在GPU上使用。相反,您需要:
# Modify Import
from keras.layers import Embedding, LSTM, Dense, Dropout, CuDNNLSTM
# In the Moddel
...
model.add(CuDNNLSTM(100))
...
我倾向于在几个步骤中停止训练来进行样本预测,并控制给定几个交叉熵值的模型的质量。
以下是我的观察:
3.生成序列
如果你读过这篇文章,这就是你所期待的:创造新的句子!要生成句子,我们需要对输入文本应用相同的转换。我们将建立一个循环,为给定的迭代次数生成下一个单词:
input_txt = "Machine"
for _ in range(10):
# Get tokens
token_list = tokenizer.texts_to_sequences([input_txt])[0]
# Pad the sequence
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
# Predict the class
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
# Get the corresponding work
for word,index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
input_txt += " "+output_word
当损失在3.1左右时,以“谷歌”作为输入,生成如下句子:
谷歌是世界范围内产生的大量数据
这并没有什么实际意义,但它成功地将谷歌与大量数据的概念联系起来。这是相当令人印象深刻的,因为它仅仅依赖于单词的共现,而没有整合任何语法概念。
如果我们在训练中再等一段时间,让损失减小到2.5,然后输入“Random Forest”:
Random Forest是一个完全托管的服务,旨在支持大量初创企业的愿景基础设施
同样,生成的内容没有意义,但语法结构相当正确。
损失在大约50个时期后开始分化,并从未低于2.5。
我想我们已经达到了发展方法的极限:
同样,生成的东西没有任何意义,但是语法结构是相当正确的。
这种损失在大约50个时期之后就会出现分歧,而且从未低于2.5。
- 模型仍然很简单
- 培训数据不够清晰
- 数据量非常有限
也就是说,我发现结果非常有趣,例如,经过训练的模型可以很容易地部署在Flask Web App上。
结论
我希望这篇文章有用。我试图说明语言生成的主要概念、挑战和限制。与本文讨论的方法相比,更大的网络和更好的数据无疑是改进的来源。如有任何疑问或意见,请留言:)。
资料来源:
Kaggle Kernel : https://www.kaggle.com/shivamb/beginners-guide-to-text-generation-using-lstms
Originally published here: https://maelfabien.github.io/project/NLP_Gen/#generating-sequences

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消