











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






图解十大CNN架构(上)
2019年10月02日 由 sunlei 发表
159398
0
您是如何跟上不同的卷积神经网络(CNNs)的?近年来,我们见证了无数CNNs的诞生。这些网络已经变得如此之深奥,以至于很难将整个模型可视化。我们不再跟踪它们,而是把它们当作黑盒模型。
本文是10种常见CNN架构的可视化集合,也许正是你需要的知识点。这些插图提供了整个模型的更紧凑的视图,无需去逐个浏览那些 Softmax 层。除了这些示意图,作者还提供了一些注释,阐述了它们是如何不断演变的——卷积层从 5 到 50 个、从普通的卷积层到卷积模块、从 2~3 tower 到 32 tower 、卷积核从 7⨉7 到 5⨉5 。
所谓“常见”,是指这些模型的预训练权重通常被深度学习库(如 TensorFlow 和 PyTorch )所共享,提供给开发者使用,这些模型通常会在课堂上讲授。其中一些模型已经在竞赛(如 ILSVRC ImageNet 大规模图像识别挑战)中取得了成功。
[caption id="attachment_44950" align="aligncenter" width="1100"]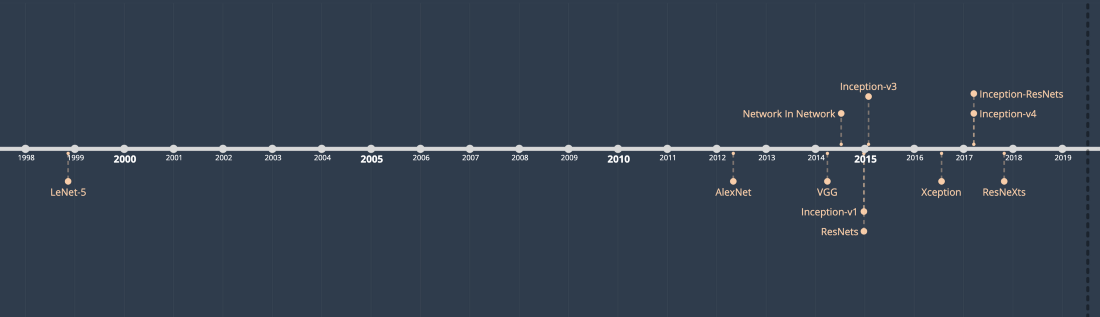 将要讨论的10个架构与相应的论文发布时间[/caption]
将要讨论的10个架构与相应的论文发布时间[/caption]
[caption id="attachment_44951" align="aligncenter" width="770"]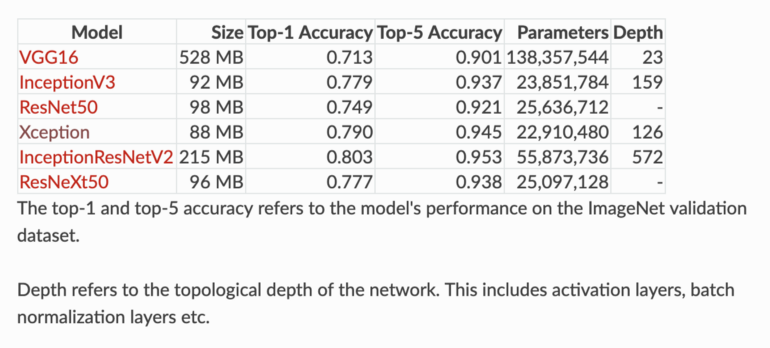 6个网络架构的预训练权重可以在 Keras 中获得,参见https://keras.io/applications/?source=post_page[/caption]
6个网络架构的预训练权重可以在 Keras 中获得,参见https://keras.io/applications/?source=post_page[/caption]
写这篇文章的原因在于没有多少博客和文章提到这些紧凑的结构图解。因此,作者决定自己写一篇作为参考。出于这个目的,作者阅读了本文提到的论文和代码(绝大部分是 TensorFlow 和 Keras ),得到了这些成果。这里还要特别指出,这些 CNN 网络结构的来源五花八门——计算机硬件性能的提高、ImageNet 竞赛、解决特定问题、新想法等等。一位在 Google 工作的研究员 Christian Szegedy 曾经提到:
“这个进程绝大多数不只是由于更强大的硬件、更大的数据集和更大的模型,更是一系列新想法、算法和网络结构的改进”。
现在让我们来看看这些“巨兽”般的网络架构是如何逐渐演变的。
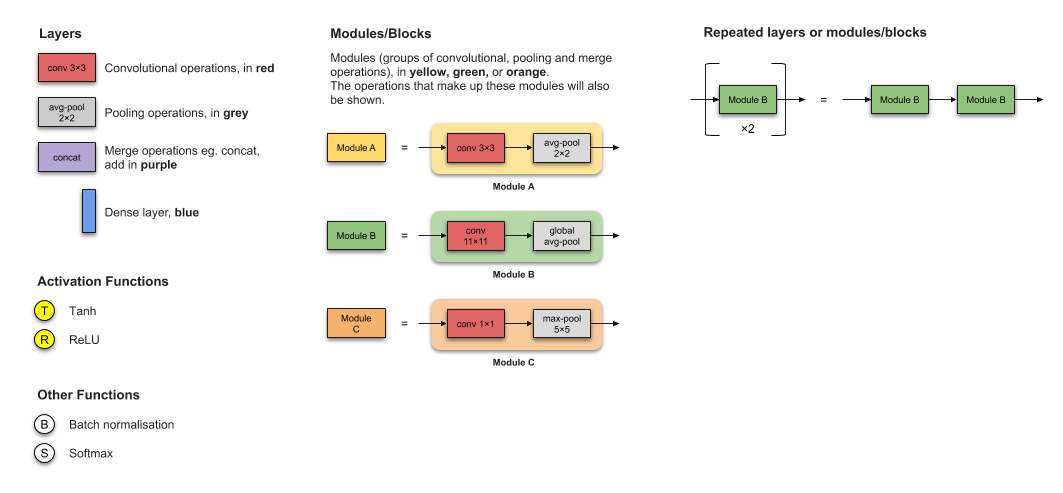
【作者注】对可视化的注释:请注意,在这些示意图中,作者略去了一些信息,如卷积过滤器的数量、Padding、Stride、Dropout 和 flatten 操作。
目录(按发表时间排序)
[caption id="attachment_44953" align="aligncenter" width="770"]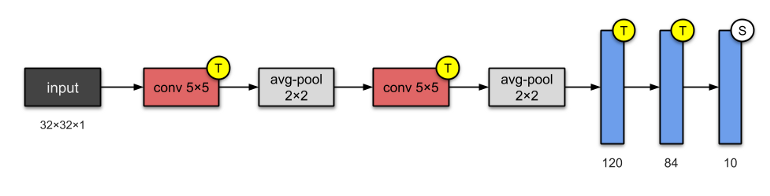 LeNet-5 网络结构[/caption]
LeNet-5 网络结构[/caption]
LeNet-5 一个最简单的网络架构。它有 2 个卷积层和 3 个全连接层(总共 5 层,这种命名方式在神经网络中很常见,这个数字代表卷积层和全连接层的总和)。Average-Pooling 层,我们现在称之为亚采样层,有一些可训练的权重(现在设计 CNN 网络时已经不常见了)。这个网络架构有大约 6 万个参数。
有哪些创新?
这个网络架构已经成为标准的“模板”:堆栈式卷积和池化层,以一个或多个全连接层作为网络的末端。
相关论著
链接:http://yann.lecun.com/exdb/publis/index.html?source=post_page
[caption id="attachment_44956" align="aligncenter" width="1100"] AlexNet 网络结构[/caption]
AlexNet 网络结构[/caption]
AlexNet 有 60 M 个参数,共有 8 层:5 个卷积层和 3 个全连接层。AlexNet 只是在 LeNet-5 中堆叠了更多的层。在该论文发表时,论文作者指出他们的网络架构是“当前最大的 ImageNet 子集卷积神经网络之一”。
有哪些创新?
相关论著
链接:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks?source=post_page
[caption id="attachment_44957" align="aligncenter" width="1100"] VGG-16 网络结构[/caption]
VGG-16 网络结构[/caption]
你应该已经注意到,CNN 开始变得越来越深。这是因为提高深度神经网络性能最直接的方法就是增加它们的规模( Szegedy et. al. )。视觉几何研究小组( VCG )的研究人员发明了 VCG-16 ,拥有 13 个卷积层和 3 个全连接层,继承了 AlexNet 的 ReLU 传统。它由 138 M 个变量组成,要占用 500 MB 存储空间。他们也设计了一个更深的版本 VCG-19 。
有哪些创新?
正如他们在论文摘要中所提到的,该论文的贡献是设计更深的网络(大约是 AlexNet 深度的两倍)。
相关论著
链接:https://arxiv.org/abs/1409.1556?source=post_page
[caption id="attachment_44958" align="aligncenter" width="1100"]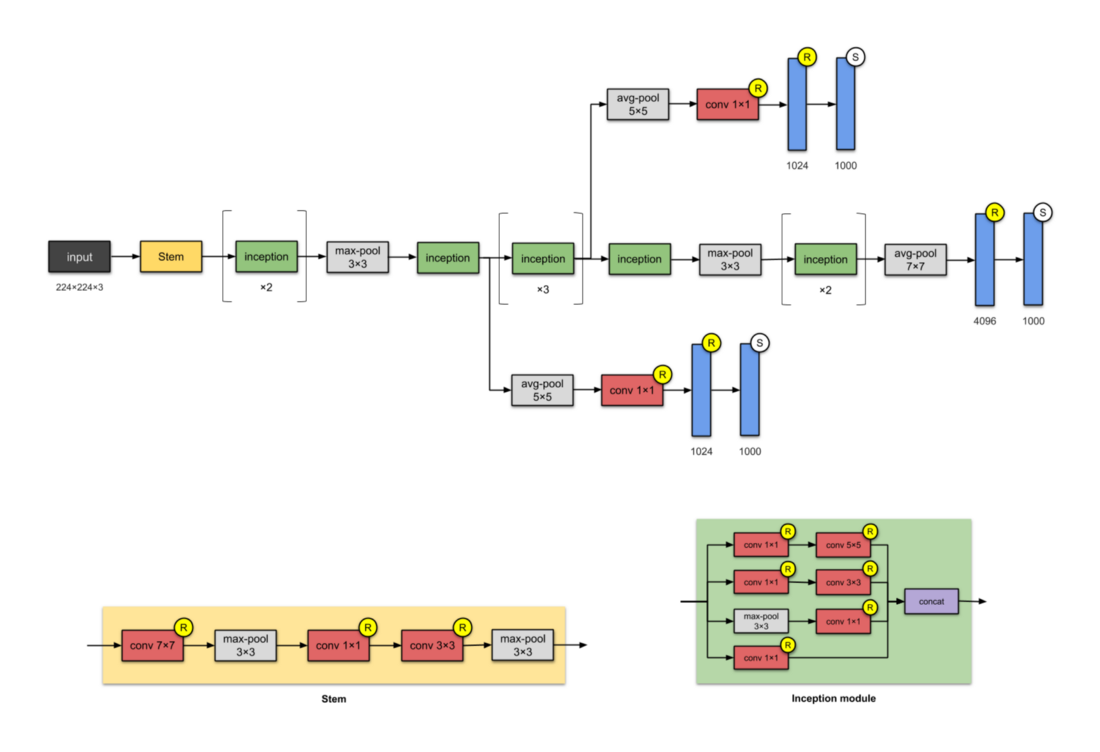 Inception-v1 网络结构. 这个 CNN 有两个辅助网络(在推断时被丢弃),网络结构基于论文中的图3[/caption]
Inception-v1 网络结构. 这个 CNN 有两个辅助网络(在推断时被丢弃),网络结构基于论文中的图3[/caption]
这个 22 层的网络架构有 5 M 参数,被称之为 Inception-v1 。在这个架构中,大量应用了 Network in Network 方法(参见附录),实现方法是采用 Inception Module 。模块的架构设计是通过对稀疏结构预估进行研究完成。
每个模块体现了 3 个思想:
值得注意的是,"这个网络架构的主要成果是提高网络内部计算资源的利用率"。
作者注:模块的命名( Stem 和 Inception )在这个版本的 Inception 网络架构中还没有提出,直到后面一些版本即 Inception-v4 和 Inception-ResNet 中才正式使用。作者把这些加入到这里是为了更容易进行比较。
有哪些创新?
采用紧密模块/板块构建网络。不采用堆叠卷积层的方法,而是堆叠由卷积层组成模块的方法。Inception 这一名字来自于科幻电影《盗梦空间》。
相关论著
链接:https://arxiv.org/abs/1409.4842?source=post_page
[caption id="attachment_44960" align="aligncenter" width="1100"]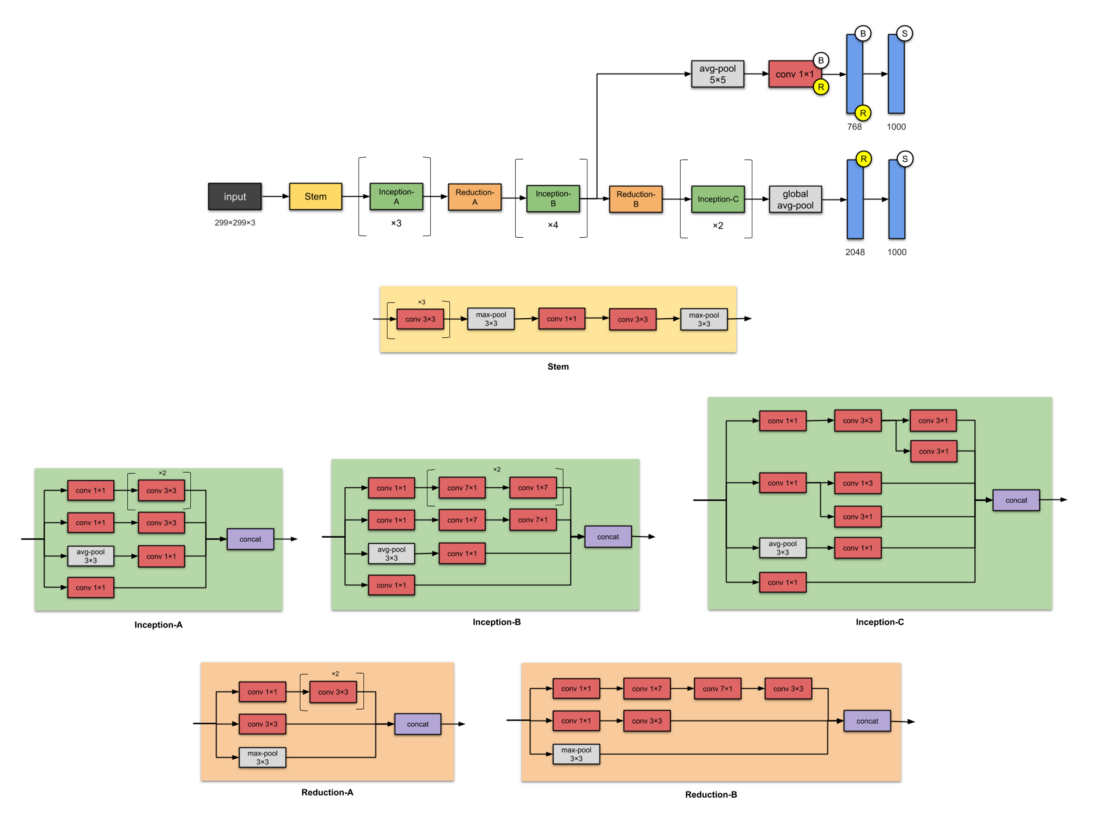 Inception-v3 网络架构 这个 CNN 有两个辅助网络(在推理时被丢弃)。注: 所有卷积层之后采用 batch norm 和 ReLU 激活[/caption]
Inception-v3 网络架构 这个 CNN 有两个辅助网络(在推理时被丢弃)。注: 所有卷积层之后采用 batch norm 和 ReLU 激活[/caption]
Inception-v3 是 Inception-v1 的后续版本,有 24 M 个参数。Inception-v2 去哪里了?别担心,它只不过是 v3 的一个早期原型,因此与 v3 十分相似,但不常被使用。该论文作者在提出 Inception-v2 时,在上面做了很多实验,并记录了一些成功经验。Inception 是这些成功经验的结晶(如对优化器、损失函数的改进,在辅助网络中对辅助层增加批量正则等等)。
提出 Inception-v2 和 Inception-v3 的原因是要避免表示瓶颈(这意味着大幅度地降低了下一层的输入维度),并通过采用分片方法提高了计算效率。
模块的命名( Stem 和 Inception )在这个版本的 Inception 网络架构中还没有提出,直到后面一些版本即 Inception-v4 和 Inception-ResNet 中才正式使用。作者把这些加入到这里是为了更容易进行比较。
有哪些创新?
首先采用批量正则化(为了简化,上图中未反映这一点)的设计者之一。
与之前的 Inception-v1 版本相比,有哪些改进?
相关论著
链接:https://arxiv.org/abs/1512.00567?source=post_page
本文是10种常见CNN架构的可视化集合,也许正是你需要的知识点。这些插图提供了整个模型的更紧凑的视图,无需去逐个浏览那些 Softmax 层。除了这些示意图,作者还提供了一些注释,阐述了它们是如何不断演变的——卷积层从 5 到 50 个、从普通的卷积层到卷积模块、从 2~3 tower 到 32 tower 、卷积核从 7⨉7 到 5⨉5 。
所谓“常见”,是指这些模型的预训练权重通常被深度学习库(如 TensorFlow 和 PyTorch )所共享,提供给开发者使用,这些模型通常会在课堂上讲授。其中一些模型已经在竞赛(如 ILSVRC ImageNet 大规模图像识别挑战)中取得了成功。
[caption id="attachment_44950" align="aligncenter" width="1100"]
将要讨论的10个架构与相应的论文发布时间[/caption][caption id="attachment_44951" align="aligncenter" width="770"]
6个网络架构的预训练权重可以在 Keras 中获得,参见https://keras.io/applications/?source=post_page[/caption]写这篇文章的原因在于没有多少博客和文章提到这些紧凑的结构图解。因此,作者决定自己写一篇作为参考。出于这个目的,作者阅读了本文提到的论文和代码(绝大部分是 TensorFlow 和 Keras ),得到了这些成果。这里还要特别指出,这些 CNN 网络结构的来源五花八门——计算机硬件性能的提高、ImageNet 竞赛、解决特定问题、新想法等等。一位在 Google 工作的研究员 Christian Szegedy 曾经提到:
“这个进程绝大多数不只是由于更强大的硬件、更大的数据集和更大的模型,更是一系列新想法、算法和网络结构的改进”。
现在让我们来看看这些“巨兽”般的网络架构是如何逐渐演变的。
【作者注】对可视化的注释:请注意,在这些示意图中,作者略去了一些信息,如卷积过滤器的数量、Padding、Stride、Dropout 和 flatten 操作。
目录(按发表时间排序)
- LeNet-5
- AlexNet
- VGG-16
- Inception-v1
- Inception-v3
- ResNet-50
- Xception
- Inception-v4
- Inception-ResNets
- ResNeXt-50
1. LeNet-5 (1998)
[caption id="attachment_44953" align="aligncenter" width="770"]
LeNet-5 网络结构[/caption]LeNet-5 一个最简单的网络架构。它有 2 个卷积层和 3 个全连接层(总共 5 层,这种命名方式在神经网络中很常见,这个数字代表卷积层和全连接层的总和)。Average-Pooling 层,我们现在称之为亚采样层,有一些可训练的权重(现在设计 CNN 网络时已经不常见了)。这个网络架构有大约 6 万个参数。
有哪些创新?
这个网络架构已经成为标准的“模板”:堆栈式卷积和池化层,以一个或多个全连接层作为网络的末端。
相关论著
- 论文: Gradient-Based Learning Applied to Document Recognition
链接:http://yann.lecun.com/exdb/publis/index.html?source=post_page
- 作者: Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner
- 发表在: Proceedings of the IEEE (1998)
2. AlexNet (2012)
[caption id="attachment_44956" align="aligncenter" width="1100"]
AlexNet 网络结构[/caption]AlexNet 有 60 M 个参数,共有 8 层:5 个卷积层和 3 个全连接层。AlexNet 只是在 LeNet-5 中堆叠了更多的层。在该论文发表时,论文作者指出他们的网络架构是“当前最大的 ImageNet 子集卷积神经网络之一”。
有哪些创新?
- 他们的网络架构是首个采用 ReLU 作为激活函数的 CNN ;
- 在 CNN 中采用交织池化(Overlapping pooling)。
相关论著
- 论文: ImageNet Classification with Deep Convolutional Neural Networks
链接:https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks?source=post_page
- 作者: Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton. University of Toronto, Canada.
- 发表在: NeurIPS 2012
3. VGG-16 (2014)
[caption id="attachment_44957" align="aligncenter" width="1100"]
VGG-16 网络结构[/caption]你应该已经注意到,CNN 开始变得越来越深。这是因为提高深度神经网络性能最直接的方法就是增加它们的规模( Szegedy et. al. )。视觉几何研究小组( VCG )的研究人员发明了 VCG-16 ,拥有 13 个卷积层和 3 个全连接层,继承了 AlexNet 的 ReLU 传统。它由 138 M 个变量组成,要占用 500 MB 存储空间。他们也设计了一个更深的版本 VCG-19 。
有哪些创新?
正如他们在论文摘要中所提到的,该论文的贡献是设计更深的网络(大约是 AlexNet 深度的两倍)。
相关论著
- 论文: Very Deep Convolutional Networks for Large-Scale Image Recognition
链接:https://arxiv.org/abs/1409.1556?source=post_page
- 作者: Karen Simonyan, Andrew Zisserman. University of Oxford, UK.
- 发表在 arXiv preprint, 2014
4. Inception-v1 (2014)
[caption id="attachment_44958" align="aligncenter" width="1100"]
Inception-v1 网络结构. 这个 CNN 有两个辅助网络(在推断时被丢弃),网络结构基于论文中的图3[/caption]这个 22 层的网络架构有 5 M 参数,被称之为 Inception-v1 。在这个架构中,大量应用了 Network in Network 方法(参见附录),实现方法是采用 Inception Module 。模块的架构设计是通过对稀疏结构预估进行研究完成。
每个模块体现了 3 个思想:
- 采用不同过滤器的并行卷积塔,然后进行堆叠,采用 1×1、3×3 、5×5 卷积核,识别不同特征,从而对其进行“聚类”。这个想法受到 Arora 等人的论文“ Provable bounds for learning some deep representations ”启发,建议采用逐层构建的方式,这样可以分析最后一层的相关统计,并把它们聚类到高相关的各单元组。
- 1×1 卷积核用来进行维度裁减,以避免计算瓶颈。
- 1×1 卷积核在一个卷积内增加了非线性。
- 该论文作者也引入了两个辅助分类器,以在分类器的最后阶段扩大差异,增加了反向传播的网格信号,提供了额外的正则化。辅助网络(与辅助分类分类器相连的分支)在推理时被丢弃。
值得注意的是,"这个网络架构的主要成果是提高网络内部计算资源的利用率"。
作者注:模块的命名( Stem 和 Inception )在这个版本的 Inception 网络架构中还没有提出,直到后面一些版本即 Inception-v4 和 Inception-ResNet 中才正式使用。作者把这些加入到这里是为了更容易进行比较。
有哪些创新?
采用紧密模块/板块构建网络。不采用堆叠卷积层的方法,而是堆叠由卷积层组成模块的方法。Inception 这一名字来自于科幻电影《盗梦空间》。
相关论著
- 论文: Going Deeper with Convolutions
链接:https://arxiv.org/abs/1409.4842?source=post_page
- 作者: Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich. Google, University of Michigan, University of North Carolina
- 发表在: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
5. Inception-v3 (2015)
[caption id="attachment_44960" align="aligncenter" width="1100"]
Inception-v3 网络架构 这个 CNN 有两个辅助网络(在推理时被丢弃)。注: 所有卷积层之后采用 batch norm 和 ReLU 激活[/caption]Inception-v3 是 Inception-v1 的后续版本,有 24 M 个参数。Inception-v2 去哪里了?别担心,它只不过是 v3 的一个早期原型,因此与 v3 十分相似,但不常被使用。该论文作者在提出 Inception-v2 时,在上面做了很多实验,并记录了一些成功经验。Inception 是这些成功经验的结晶(如对优化器、损失函数的改进,在辅助网络中对辅助层增加批量正则等等)。
提出 Inception-v2 和 Inception-v3 的原因是要避免表示瓶颈(这意味着大幅度地降低了下一层的输入维度),并通过采用分片方法提高了计算效率。
模块的命名( Stem 和 Inception )在这个版本的 Inception 网络架构中还没有提出,直到后面一些版本即 Inception-v4 和 Inception-ResNet 中才正式使用。作者把这些加入到这里是为了更容易进行比较。
有哪些创新?
首先采用批量正则化(为了简化,上图中未反映这一点)的设计者之一。
与之前的 Inception-v1 版本相比,有哪些改进?
- 把 n×n 卷积分解成不对称的卷积 1×n and n×1 卷积。
- 把 5×5 卷积分解成 2 个 3×3 卷积操作
- 把 7×7 卷积替换成一系列 3×3 卷积。
相关论著
- 论文: Rethinking the Inception Architecture for Computer Vision
链接:https://arxiv.org/abs/1512.00567?source=post_page
- 作者: Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna. Google, University College London
- 发表在: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
数据科学中的强大思维
下一篇
Pandas时序数据处理入门








广告


写评论取消
回复取消