











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用AI生成霉霉(Taylor Swift)的歌词(上)
2019年10月06日 由 sunlei 发表
4255
0

泰勒·斯威夫特歌词生成器
几天前,我开始学习LSTM RNN (Long - Short - Term Memory Neural Networks,长短时记忆递归神经网络),我想如果我用它来做一个项目会是个好主意。
LSTM RNN有很多应用,我决定使用自然语言生成,因为我一直想学习如何处理文本数据,而且看到由神经网络生成的文本会很有趣,所以我有了生成泰勒斯威夫特歌词的想法。
什么是LSTM递归神经网络?
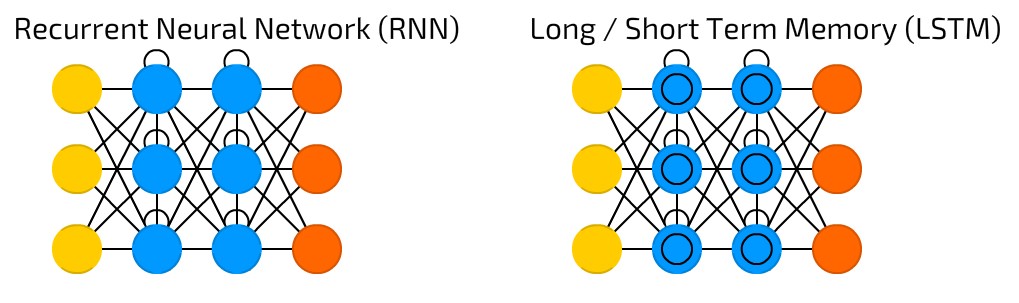
如果你不知道,LSTM递归神经网络是有循环的网络,允许信息持续存在,它们有一种特殊类型的节点叫做LSTM(长短时记忆)。
LSTM单元由单元格、输入门、输出门和遗忘门组成。细胞可以在任意的时间间隔内记住数值,这三个门控制着进出单元的信息流。如果你想了解更多关于LSTM的递归神经网络访问:
自然语言处理:从基础到RNN和LSTM(上)
https://www.atyun.com/41922.html
自然语言处理:从基础到RNN和LSTM(下)
https://www.atyun.com/41957.html
LSTM递归神经网络的应用
LSTM递归神经网络应用广泛,其中最常用的有:
- 语言建模
- 文本分类
- 对话系统
- 自然语言生成
现在,在我们学习了关于LSTM和RNN的一些基本信息之后,我们将开始实现这个想法(Taylor Swift Lyrics Generator)
我将使用两种方法来构建模型:
- 从头开始
- 使用名为textgenrnn的Python模块
您可以尝试在[本笔记本]中运行代码,我强烈建议您至少看看Colab笔记本。
处理数据集
为了训练LSTM模型,我们需要一个泰勒歌曲歌词的数据集。搜索之后,我在Kaggle中找到了这个很棒的数据集。
让我们来看看:
首先,导入项目所需的所有库:
# Import the dependencies
import numpy as np
import pandas as pd
import sys
from keras.models import Sequential
from keras.layers import LSTM, Activation, Flatten, Dropout, Dense, Embedding, TimeDistributed, CuDNNLSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
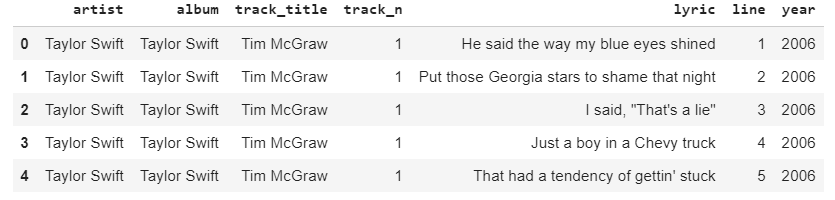
加载数据集:
#Load the dataset
dataset = pd.read_csv('taylor_swift_lyrics.csv', encoding = "latin1")
dataset.head()
将每首歌的歌词串联在一起,让每首歌都成为一个字符串:
def processFirstLine(lyrics, songID, songName, row):
lyrics.append(row['lyric'] + '\n')
songID.append( row['year']*100+ row['track_n'])
songName.append(row['track_title'])
return lyrics,songID,songName# define empty lists for the lyrics , songID , songName
lyrics = []
songID = []
songName = []# songNumber indicates the song number in the dataset
songNumber = 1# i indicates the song number
i = 0
isFirstLine = True# Iterate through every lyrics line and join them together for each song independently
for index,row in dataset.iterrows():
if(songNumber == row['track_n']):
if (isFirstLine):
lyrics,songID,songName = processFirstLine(lyrics,songID,songName,row)
isFirstLine = False
else :
#if we still in the same song , keep joining the lyrics lines
lyrics[i] += row['lyric'] + '\n'
#When it's done joining a song's lyrics lines , go to the next song :
else :
lyrics,songID,songName = processFirstLine(lyrics,songID,songName,row)
songNumber = row['track_n']
i+=1
定义新的pandas数据框以保存songID、songName、Lyric
lyrics_data = pd.DataFrame({'songID':songID, 'songName':songName, 'lyrics':lyrics })现在将歌词保存在文本文件中,以便在LSTM RNN中使用:
# Save Lyrics in .txt file
with open('lyricsText.txt', 'w',encoding="utf-8") as filehandle:
for listitem in lyrics:
filehandle.write('%s\n' % listitem)
从数据集中获得所需的数据后,我们需要对其进行预处理。
歌词预处理
1-将歌词转换为小写:
# Load the dataset and convert it to lowercase :
textFileName = 'lyricsText.txt'
raw_text = open(textFileName, encoding = 'UTF-8').read()
raw_text = raw_text.lower()
2-映射字符:
制作两个词典,一个用于将chars转换为ints,另一个用于将inst转换回chars:
# Mapping chars to ints :
chars = sorted(list(set(raw_text)))
int_chars = dict((i, c) for i, c in enumerate(chars))
chars_int = dict((i, c) for c, i in enumerate(chars))
获取文本中的字符数和词汇数量:
n_chars = len(raw_text)
n_vocab = len(chars)
print(‘Total Characters : ‘ , n_chars) # number of all the characters
in lyricsText.txt
print(‘Total Vocab : ‘, n_vocab) # number of unique characters
3-制作样品和标签:
制作样品和标签以满足LSTM RNN的要求
# process the dataset:
seq_len = 100
data_X = []
data_y = []for i in range(0, n_chars - seq_len, 1):
# Input Sequeance(will be used as samples)
seq_in = raw_text[i:i+seq_len]
# Output sequence (will be used as target)
seq_out = raw_text[i + seq_len]
# Store samples in data_X
data_X.append([chars_int[char] for char in seq_in])
# Store targets in data_y
data_y.append(chars_int[seq_out])
n_patterns = len(data_X)
print( 'Total Patterns : ', n_patterns)
4-准备样品和标签:
准备好样品和标签,准备进入我们的模型。
- 重塑样本
- 使它们正常化
- 一个热编码输出目标
# Reshape X to be suitable to go into LSTM RNN :
X = np.reshape(data_X , (n_patterns, seq_len, 1))
# Normalizing input data :
X = X/ float(n_vocab)
# One hot encode the output targets :
y = np_utils.to_categorical(data_y)
在处理完数据集之后,明天我们将开始构建LSTM RNN模型。
原文链接:https://towardsdatascience.com/ai-generates-taylor-swifts-song-lyrics-6fd92a03ef7e

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
图解十大CNN架构(下)








广告


写评论取消
回复取消