











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






数据科学家应该知道的10个深度学习的高级架构!
2017年08月11日 由 yining 发表
252170
0
随着深度学习不断地产生新进展,要跟上时代的脚步变得异常困难。几乎每天都有创新,或是产生一种新的深度学习的应用。
这篇文章包含了最近深度学习的一些进展,以及在Keras库中实现的代码。为了保持文章内容的简洁,本文只列出在计算机视觉领域取得成功的架构。

深度学习算法与传统的机器学习算法相比,是由一组不同的模型组成的。这是因为在构建完整的端到端模型时,神经网络提供了灵活性。神经网络有时可以与乐高积木相提并论,因为你可以根据你的想象力构建任何简单或复杂的架构。
我们可以定义一个高级的体系架构,从而作为一个成功的模型的可靠的记录。高级架构主要可以在ImageNet中看到,你在ImageNet中的任务是解决一个问题,比如使用给定的数据进行图像识别。
正如下面提到的架构中所描述的,每一个架构都有一个细微的差别,使它们与通常的模型不同;当它们被用来解决问题时,就会具有一些优势。这些架构也属于“深度”模型。
就像这个名字所显示的那样,它只是在创造一种可以复制人类所做的视觉任务的人工模型。这基本上意味着我们能看到的和我们所感知到的是一个可以在人造系统中被理解和实现的过程。
计算机视觉可以分类的主要任务类型如下:
既然我们已经了解了什么是高级架构,并探索了计算机视觉的任务,那么现在将列出最重要的架构及其描述:
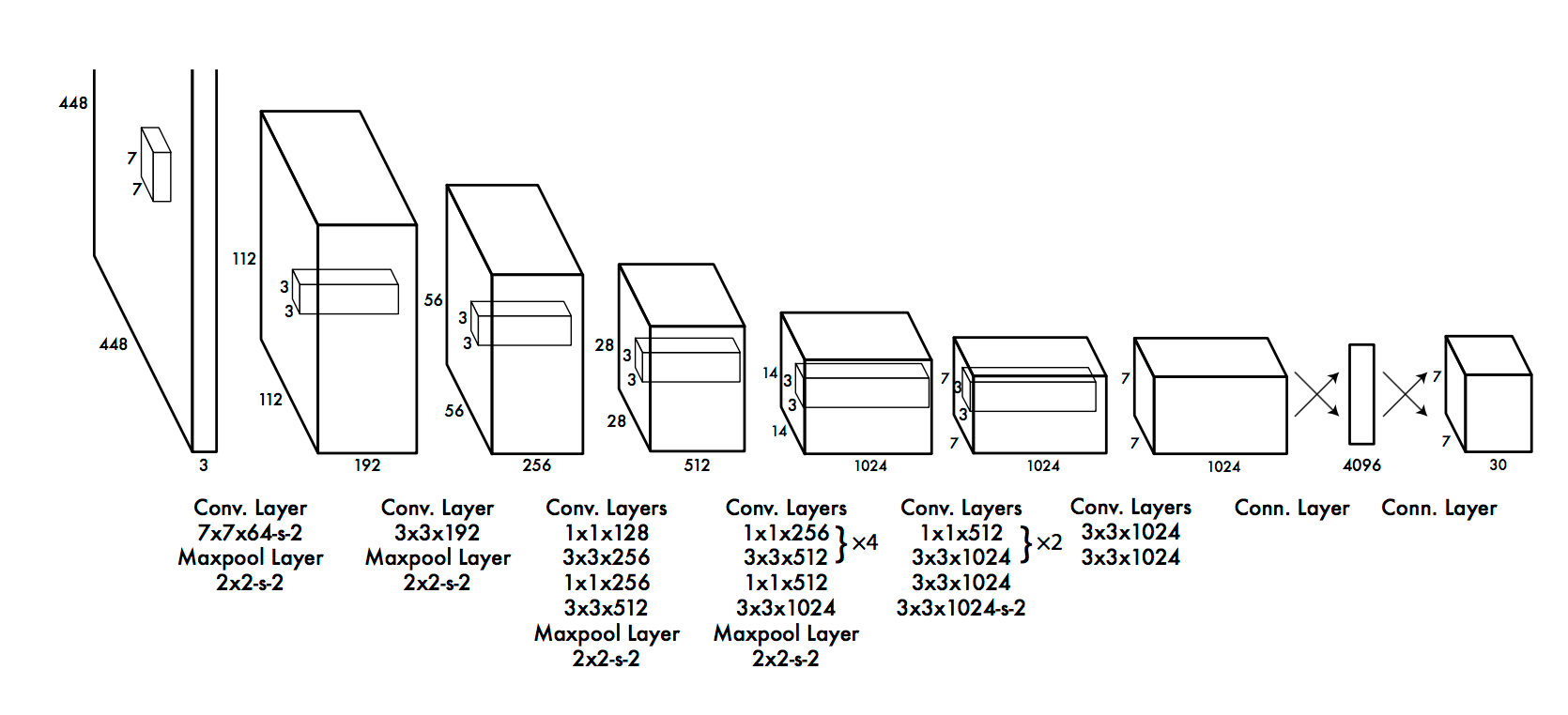
AlexNet是第一个深层架构,由深度学习的先驱之一,Geoffrey Hinton和他的同事们介绍。它是一个简单而又强大的网络架构,为深度学习的开创性研究铺平了道路。下面是体系架构的表示: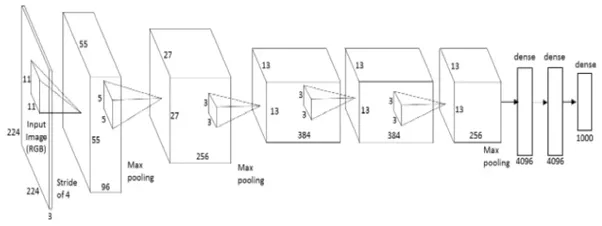
在出现故障的时候,AlexNet看起来就像一个简单的架构,上面有一个卷积和汇聚层,紧接着在顶部有完全关联层。这个非常简单的架构,在20世纪80年代就被概念化了。这个模型的不同之处在于它执行任务的规模,还有使用GPU进行训练。在20世纪80年代,CPU被用于训练神经网络。然而,AlexNet在使用GPU的情况下,将训练速度提高了10倍。
尽管目前有点过时,但AlexNet仍然被用作应用深度神经网络的起点,无论是在计算机视觉还是语音识别方面。
VGG Net是由牛津大学视觉图形组(Visual Graphics Group at Oxford)的研究人员引入的(因此得名VGG)。该网络有着特别的金字塔的形状,最接近图像的底层是宽的,而顶层是深的。
正如图像所描述的,VGG包含了随后的卷积层,然后是池化层。池化层负责使层变得更窄。在他们的论文中,他们提出了多种类型的网络,并且在架构的深度上有了变化。
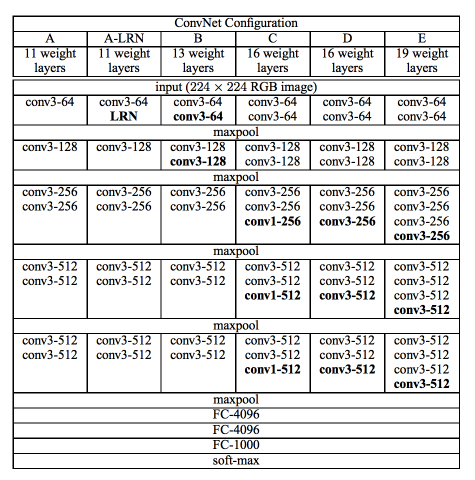
VGG的优点是,它是一个非常好的架构,用于对特定任务进行基准测试。此外,VGG预先训练的网络可以在互联网上免费使用,因此它通常被用于各种应用程序之中。另一方面,它的主要缺点是,如果从头开始训练,它的训练速度会变得非常慢。
即使是在一台像样的GPU上,也需要花费一周多的时间才能让它正常工作。
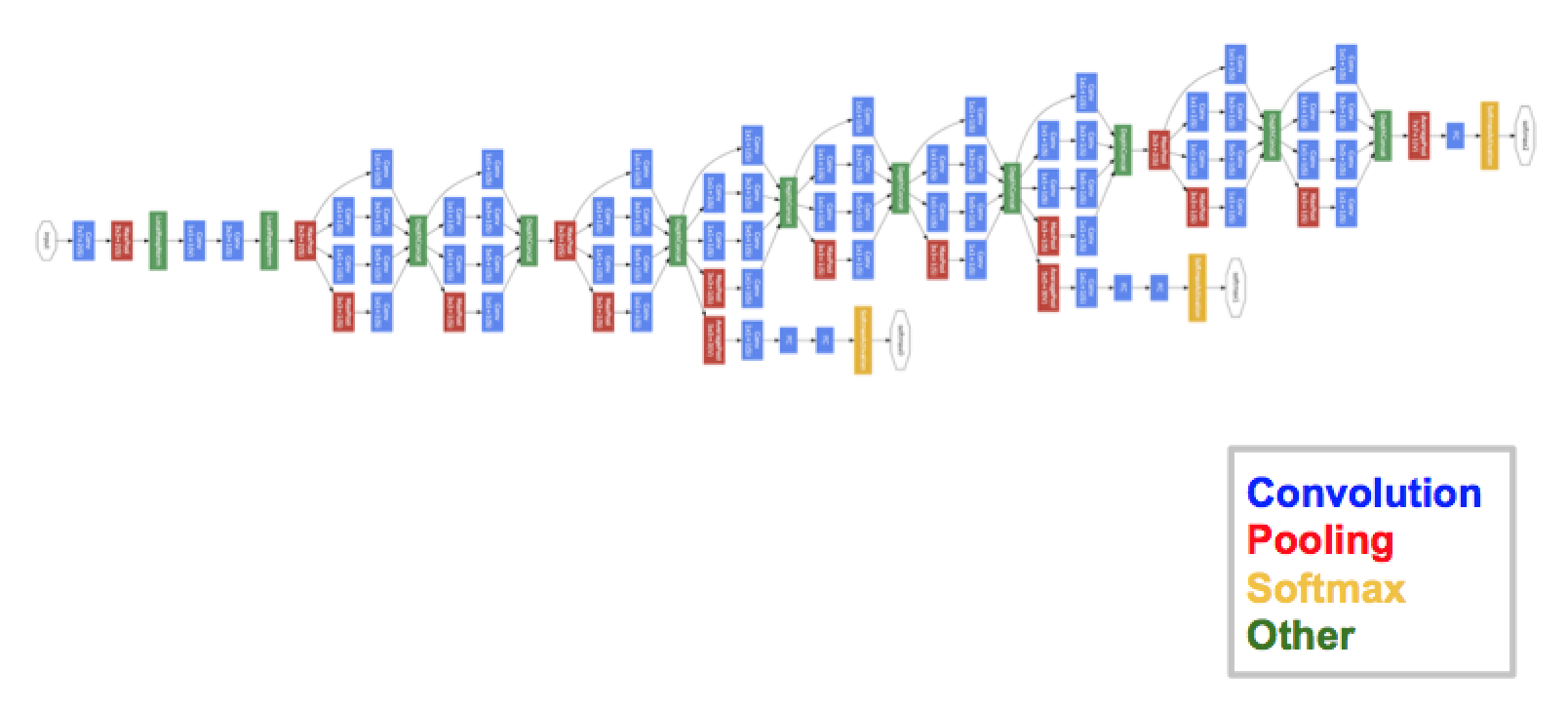
GoogleNet(或Inception Network)是由谷歌研究人员设计的一种架构。GoogleNet是2014年ImageNet的赢家,它被证明是一个强大的模型。
在这个架构中,随着不断深入(与19个层的VGG相比,它包含了22个层),研究人员还创建了一种被称为盗梦空间模块(Inception module)的新方法。
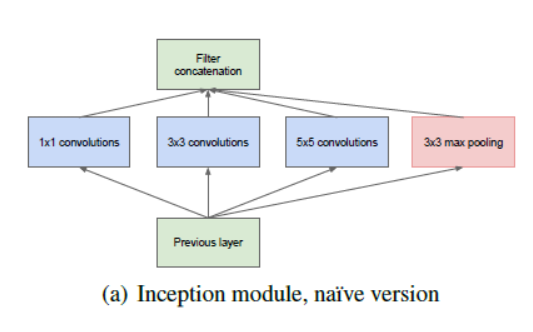
正如上面所看到的,这与我们之前看到的顺序架构相比,发生了巨大的变化。在一个单层中,有多种类型的“特征提取器”。这间接地帮助了网络更好的去表现,因为在训练本身的网络中有许多选项可以在解决任务时选择。它可以选择对输入进行卷积,也可以直接对其进行池化。
GoogleNet的优势是:
GoogleNet本身并没有直接的缺点,但是在架构上有了进一步的改变,这使得模型的性能变得更好。一个这样的变化被称为“Xception网络”,在这个网络中,盗梦空间模块的散度(如我们在上面的图片中看到的 GoogleNet的4个)的偏差被增加了。理论上它是无限的(因此被称为极限盗梦空间!)
ResNet是一个真正定义深度学习架构深度的怪物架构。剩余网络由多个后续的剩余模块组成,这些模块是ResNet体系结构的基本构建块。剩余模块的表示如下:
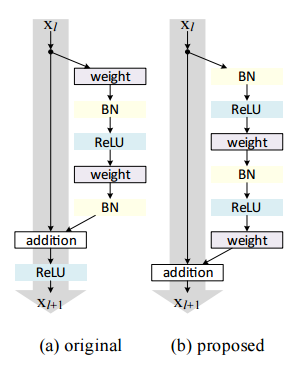
简单地说,一个剩余模块有两个选项,要么它可以在输入上执行一组函数,要么完全跳过这一步骤。与GoogleNet类似,这些剩余的模块堆叠在一起,形成一个完整的端到端网络。

ResNet新推出的一些技术是:
ResNet的主要优势是,成百上千的剩余层可以用来创建一个网络,然后进行训练。这与通常的顺序网络稍有不同,在增加层数时,你会看到性能升级会降低。
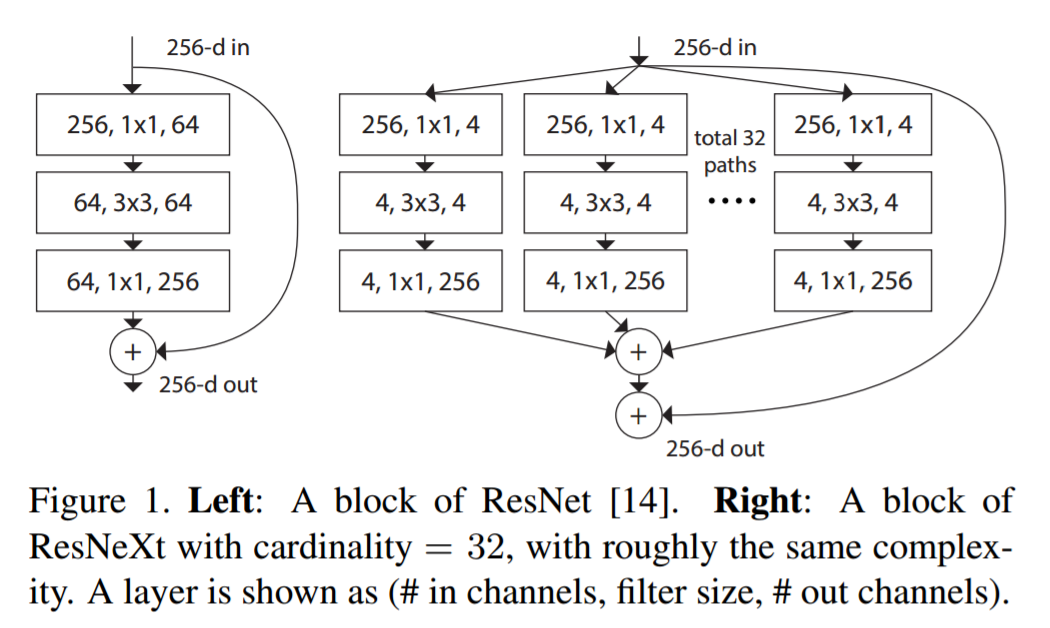
ResNeXt据说是目前最先进的物体识别技术。它建立在初始和ResNet的概念之上,以带来新的和改进的体系架构。下图是对ResNeXt模块的剩余模块的总结:
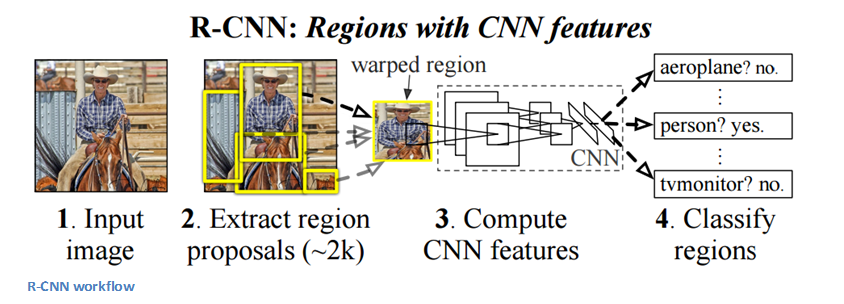
据报道,Region Based CNN架构是所有应用于物体检测问题的深度学习架构中最具影响力的一种。为了解决检测问题,RCNN所做的是尝试绘制一个边界框,将图像中的所有对象都画出来,然后识别图像中的对象。它的工作原理如下:
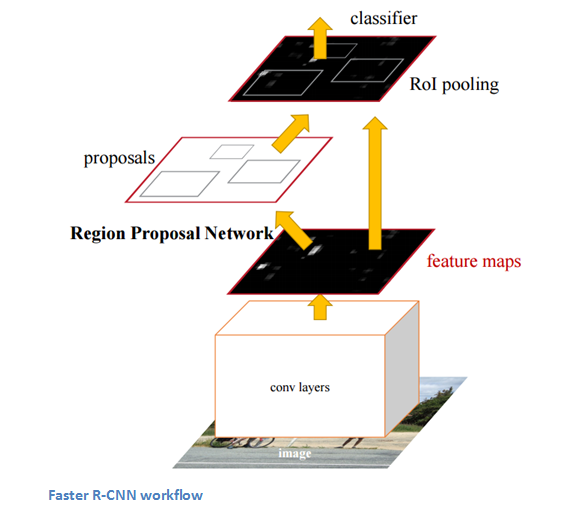
RCNN的结构如下:
YOLO是目前最先进的实时系统,它是基于深度学习来解决图像检测问题的。如下图所示,它首先将图像分割为已定义的边界框,然后在所有这些框中并行地运行识别算法,以确定它们属于哪个对象类。识别了这些类之后,它就会智能地合并这些框,从而形成一个围绕对象的最优的边界框。

这些都是并行完成的,所以它可以实时运行;每秒处理40个图像。
尽管它的性能比RCNN的要低,但它仍然有一个优势,那就是在日常问题中使用它的可行性较高。下面是YOLO架构的代表:
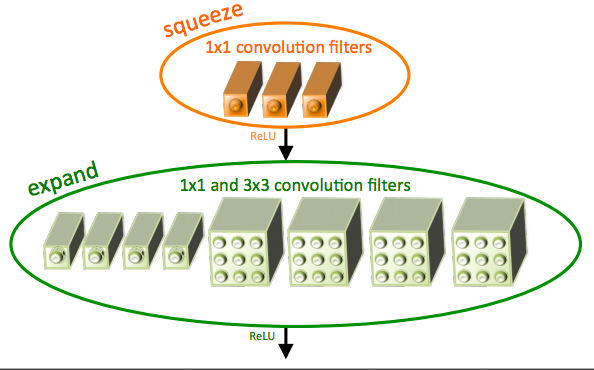
SqueezeNet架构是一种更强大的架构,在像移动平台这样的低带宽场景中非常有用。这个架构只占用了4.9 MB空间!这个巨大的变化是由一个叫做火模块(fire module)的特殊架构引起的。下图是火模块的表示:
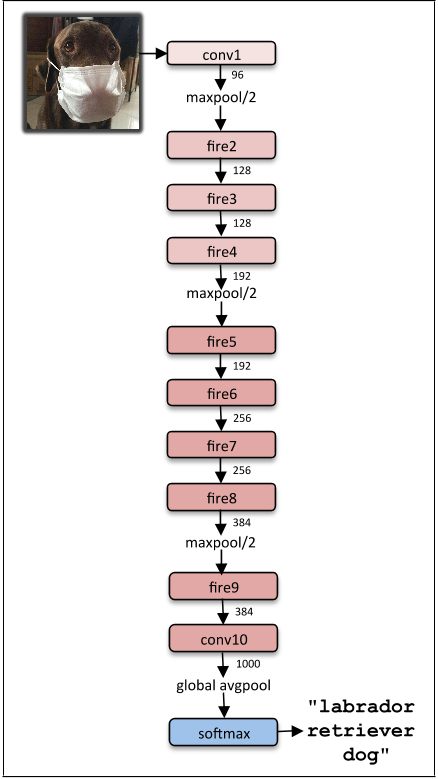
SqueezeNet的最后一种架构如下:
SegNet是一种应用于解决图像分割问题的深度学习架构。它由处理层(编码器)的序列组成,然后是对应的一组用于像素分类的解码器。下图总结了SegNet的工作内容:
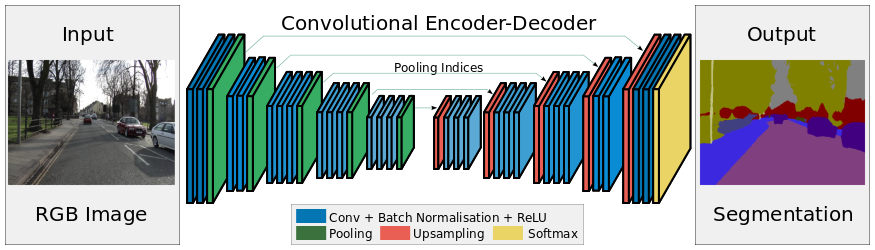
SegNet的一个关键特征是,它保留了分段图像中的高频细节,因为编码器网络的池化指数(pooling indices)与解码器网络的池化指数相连接。简而言之,信息是直接传递的。在处理图像分割问题时,SegNet是最好的模型。
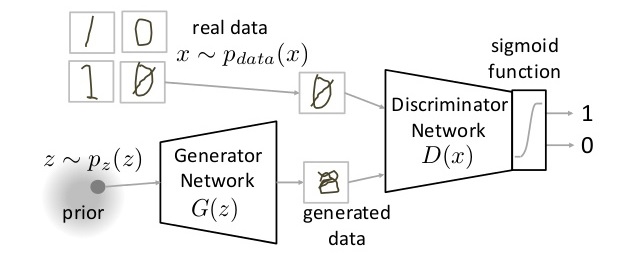
GAN是一种完全不同的神经网络架构,在这种架构中,神经网络被用来生成一个全新的图像,而这个新图像并不存在于训练数据集里,但在数据集里是足够真实的。例如,下面的图像是由故障的GANs构成的:
此文为编译作品,作者FAIZAN SHAIKH,原文链接:https://www.analyticsvidhya.com/blog/2017/08/10-advanced-deep-learning-architectures-data-scientists/
这篇文章包含了最近深度学习的一些进展,以及在Keras库中实现的代码。为了保持文章内容的简洁,本文只列出在计算机视觉领域取得成功的架构。
内容
- 我们所说的高级架构指的是什么?
- 计算机视觉任务类型
- 深度学习架构清单
我们所说的高级架构指的是什么?
深度学习算法与传统的机器学习算法相比,是由一组不同的模型组成的。这是因为在构建完整的端到端模型时,神经网络提供了灵活性。神经网络有时可以与乐高积木相提并论,因为你可以根据你的想象力构建任何简单或复杂的架构。
我们可以定义一个高级的体系架构,从而作为一个成功的模型的可靠的记录。高级架构主要可以在ImageNet中看到,你在ImageNet中的任务是解决一个问题,比如使用给定的数据进行图像识别。
正如下面提到的架构中所描述的,每一个架构都有一个细微的差别,使它们与通常的模型不同;当它们被用来解决问题时,就会具有一些优势。这些架构也属于“深度”模型。
计算机视觉任务类型
就像这个名字所显示的那样,它只是在创造一种可以复制人类所做的视觉任务的人工模型。这基本上意味着我们能看到的和我们所感知到的是一个可以在人造系统中被理解和实现的过程。
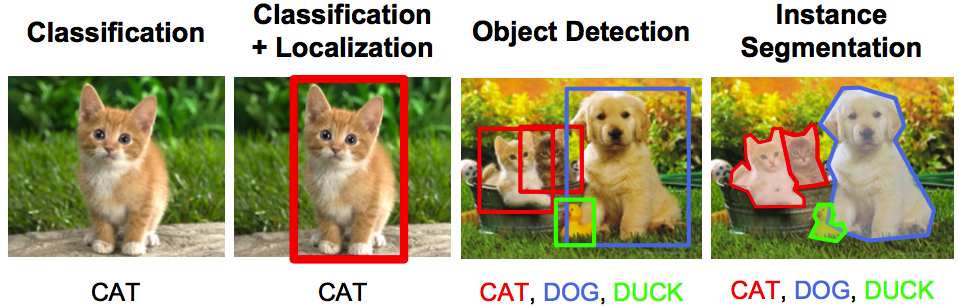
计算机视觉可以分类的主要任务类型如下:
- 对象识别/分类-在对象识别中,你得到一个原始的图像,你的任务是识别这个图像属于哪个类。
- 分类+本地化——如果图像中只有一个对象,而你的任务是找到该对象的位置,那么给出这个问题的一个更具体的术语就是本地化问题。
- 对象检测——在对象检测中,你的任务是识别图像中的对象处于哪个位置。这些对象可能是同一个类或不同的类。
- 图像分割——图像分割是一项复杂的任务,目标是将每个像素映射到其合法的类中。
深度学习架构列表
既然我们已经了解了什么是高级架构,并探索了计算机视觉的任务,那么现在将列出最重要的架构及其描述:
1. AlexNet
AlexNet是第一个深层架构,由深度学习的先驱之一,Geoffrey Hinton和他的同事们介绍。它是一个简单而又强大的网络架构,为深度学习的开创性研究铺平了道路。下面是体系架构的表示:
在出现故障的时候,AlexNet看起来就像一个简单的架构,上面有一个卷积和汇聚层,紧接着在顶部有完全关联层。这个非常简单的架构,在20世纪80年代就被概念化了。这个模型的不同之处在于它执行任务的规模,还有使用GPU进行训练。在20世纪80年代,CPU被用于训练神经网络。然而,AlexNet在使用GPU的情况下,将训练速度提高了10倍。
尽管目前有点过时,但AlexNet仍然被用作应用深度神经网络的起点,无论是在计算机视觉还是语音识别方面。
2. VGG Net
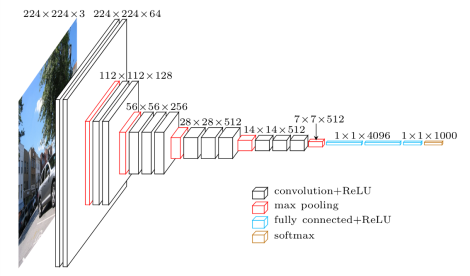
VGG Net是由牛津大学视觉图形组(Visual Graphics Group at Oxford)的研究人员引入的(因此得名VGG)。该网络有着特别的金字塔的形状,最接近图像的底层是宽的,而顶层是深的。
正如图像所描述的,VGG包含了随后的卷积层,然后是池化层。池化层负责使层变得更窄。在他们的论文中,他们提出了多种类型的网络,并且在架构的深度上有了变化。
VGG的优点是,它是一个非常好的架构,用于对特定任务进行基准测试。此外,VGG预先训练的网络可以在互联网上免费使用,因此它通常被用于各种应用程序之中。另一方面,它的主要缺点是,如果从头开始训练,它的训练速度会变得非常慢。
即使是在一台像样的GPU上,也需要花费一周多的时间才能让它正常工作。
3. GoogleNet
GoogleNet(或Inception Network)是由谷歌研究人员设计的一种架构。GoogleNet是2014年ImageNet的赢家,它被证明是一个强大的模型。
在这个架构中,随着不断深入(与19个层的VGG相比,它包含了22个层),研究人员还创建了一种被称为盗梦空间模块(Inception module)的新方法。
正如上面所看到的,这与我们之前看到的顺序架构相比,发生了巨大的变化。在一个单层中,有多种类型的“特征提取器”。这间接地帮助了网络更好的去表现,因为在训练本身的网络中有许多选项可以在解决任务时选择。它可以选择对输入进行卷积,也可以直接对其进行池化。
GoogleNet的优势是:
- GoogleNet训练速度比VGG快。
- 一个预先训练过的GoogleNet的空间要比VGG小。一个VGG模型空间超过了500MB,而 GoogleNet只有96MB。
GoogleNet本身并没有直接的缺点,但是在架构上有了进一步的改变,这使得模型的性能变得更好。一个这样的变化被称为“Xception网络”,在这个网络中,盗梦空间模块的散度(如我们在上面的图片中看到的 GoogleNet的4个)的偏差被增加了。理论上它是无限的(因此被称为极限盗梦空间!)
4. ResNet
ResNet是一个真正定义深度学习架构深度的怪物架构。剩余网络由多个后续的剩余模块组成,这些模块是ResNet体系结构的基本构建块。剩余模块的表示如下:
简单地说,一个剩余模块有两个选项,要么它可以在输入上执行一组函数,要么完全跳过这一步骤。与GoogleNet类似,这些剩余的模块堆叠在一起,形成一个完整的端到端网络。
ResNet新推出的一些技术是:
- 使用标准的SGD,而不是花哨的自适应学习技术。通过一个合理的初始化函数来完成,保持了训练的完整度。
- 预先处理输入的变化,输入首先被划分为补丁,然后被放到网络中。
ResNet的主要优势是,成百上千的剩余层可以用来创建一个网络,然后进行训练。这与通常的顺序网络稍有不同,在增加层数时,你会看到性能升级会降低。
5. ResNeXt
ResNeXt据说是目前最先进的物体识别技术。它建立在初始和ResNet的概念之上,以带来新的和改进的体系架构。下图是对ResNeXt模块的剩余模块的总结:
6. RCNN (Region Based CNN)
据报道,Region Based CNN架构是所有应用于物体检测问题的深度学习架构中最具影响力的一种。为了解决检测问题,RCNN所做的是尝试绘制一个边界框,将图像中的所有对象都画出来,然后识别图像中的对象。它的工作原理如下:
RCNN的结构如下:
7. YOLO (You Only Look Once)
YOLO是目前最先进的实时系统,它是基于深度学习来解决图像检测问题的。如下图所示,它首先将图像分割为已定义的边界框,然后在所有这些框中并行地运行识别算法,以确定它们属于哪个对象类。识别了这些类之后,它就会智能地合并这些框,从而形成一个围绕对象的最优的边界框。
这些都是并行完成的,所以它可以实时运行;每秒处理40个图像。
尽管它的性能比RCNN的要低,但它仍然有一个优势,那就是在日常问题中使用它的可行性较高。下面是YOLO架构的代表:
8. SqueezeNet
SqueezeNet架构是一种更强大的架构,在像移动平台这样的低带宽场景中非常有用。这个架构只占用了4.9 MB空间!这个巨大的变化是由一个叫做火模块(fire module)的特殊架构引起的。下图是火模块的表示:
SqueezeNet的最后一种架构如下:
9. SegNet
SegNet是一种应用于解决图像分割问题的深度学习架构。它由处理层(编码器)的序列组成,然后是对应的一组用于像素分类的解码器。下图总结了SegNet的工作内容:
SegNet的一个关键特征是,它保留了分段图像中的高频细节,因为编码器网络的池化指数(pooling indices)与解码器网络的池化指数相连接。简而言之,信息是直接传递的。在处理图像分割问题时,SegNet是最好的模型。
10. GAN
GAN是一种完全不同的神经网络架构,在这种架构中,神经网络被用来生成一个全新的图像,而这个新图像并不存在于训练数据集里,但在数据集里是足够真实的。例如,下面的图像是由故障的GANs构成的:
此文为编译作品,作者FAIZAN SHAIKH,原文链接:https://www.analyticsvidhya.com/blog/2017/08/10-advanced-deep-learning-architectures-data-scientists/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消