











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






微软的新型VPL模型,可以帮助人工智能更好的理解这个世界
2019年10月09日 由 TGS 发表
613266
0
 如果没有详细的标签注释,机器很难理解场景和语言,但标签注释通常是耗时且昂贵的,更为重要的是,即便是最好的标签,传达的也只是对场景的理解,而不是对语言的理解。为了解决这个问题,微软的研究人员设想了一个人工智能系统,可以通过模仿人类提高对世界理解的方式,对图像和文本进行训练。
如果没有详细的标签注释,机器很难理解场景和语言,但标签注释通常是耗时且昂贵的,更为重要的是,即便是最好的标签,传达的也只是对场景的理解,而不是对语言的理解。为了解决这个问题,微软的研究人员设想了一个人工智能系统,可以通过模仿人类提高对世界理解的方式,对图像和文本进行训练。据研究人员表示,他们的单模型编码器-解码器视觉语言预训练(VLP)模型,既可以生成图像描述,又可以回答关于场景的自然语言问题,为将来实现人类对等的框架奠定基础。
“理解我们周围的世界是一个技能,而作为人类,我们从小就开始学习,我们与物理环境的联系越深,就越能更好地理解和使用语言来解释事物的存在以及发生在我们周围的事情。”微软的高级研究员Hamid Palangi在博客中写道,“另一方面,对于机器来说,场景理解和语言理解是非常具有挑战性的,尤其是在只有弱监督的情况下。”
正如Palangi所解释的那样,图像字幕和视觉问答质量算法的表现通常不佳,具体原因有三:
- 它们不能利用上下文来描述图像并对其进行推理;
- 没有进行大规模的培训前数据挖掘;
- 架构设计不适合执行语言、视觉对齐和语言生成任务。
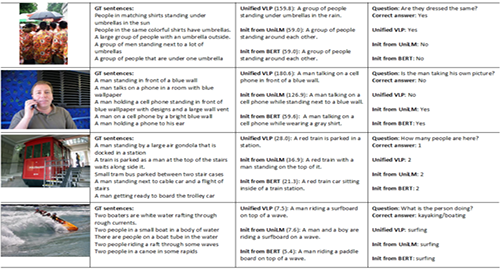 该团队试图克服这些问题,其架构包括编码器(学习给定数据的数字表示)和解码器(将编码器的表示转换为人类可解释的信息)一起进行预先训练,并针对两种预测进行优化。他们说,“它”最终会创造出更好的编码器和解码器表示,可以供研究人员使用相同的模型来实现不同的目标,如图像字幕和视觉问题回答。
该团队试图克服这些问题,其架构包括编码器(学习给定数据的数字表示)和解码器(将编码器的表示转换为人类可解释的信息)一起进行预先训练,并针对两种预测进行优化。他们说,“它”最终会创造出更好的编码器和解码器表示,可以供研究人员使用相同的模型来实现不同的目标,如图像字幕和视觉问题回答。研究人员评估了VLP在公共基准上(包括COCO、Flickr30K和VQA 2.0)对图像进行说明和推理的能力。他们报告说,它不仅在几个图像字幕和视觉问题回答指标上超过了最先进的模型,并且还成功回答了一些关于图像的问题(比如服装设计中的相似性问题),而之前只接受过语言训练的模型则很难回答这些问题。
“智能模型设计和智能数据选择,让我们可以利用现有的公开可用资源,达到更高的语言和场景理解高度,通过VLP,我们相信我们展示了统一模型的潜力。以达到成功完成各种不同的下游任务所必需的语言和场景理解水平,在不牺牲性能的情况下,高效且快速地完成多个任务,这意味着视觉语言系统的跨越性进步。”该团队表示,将继续加强模型的体系结构,同时在预培训期间添加更多数据。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消