











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






DeepMind已经悄悄地开放了三个令人印象深刻的强化学习框架
2019年10月10日 由 sunlei 发表
294045
0

近年来,深度强化学习(DRL)一直是人工智能(AI)一些重大突破的核心。然而,尽管DRL方法取得了很大的进步,但由于缺少工具和库,它仍然难以应用于主流解决方案中。因此,DRL在很大程度上仍然是一种研究活动,并没有在现实世界中大量采用机器学习解决方案。解决这个问题需要更好的工具和框架。在当前一代人工智能(AI)领导者中,DeepMind是唯一一家在推进DRL研发方面做得最多的公司。最近,Alphabet子公司发布了一系列新的开源技术,可以帮助简化DRL方法的采用。
DRL作为一种新的深度学习技术,其应用面临的挑战不仅仅是算法的简单实现。需要训练数据集、环境、监测优化工具以及精心设计的实验来简化DRL技术的采用。考虑到DRL的机制与大多数传统机器学习方法不同,这一点在DRL的情况下尤其正确。DRL代理试图在给定的环境中通过反复试验来掌握任务。在这种情况下,环境和实验的鲁棒性对DRL代理开发的知识起着重要的作用。
DRL一直是DeepMind推进人工智能的基石。从著名的AlphaGo开始,到医疗、生态研究、当然还有游戏等领域的重大里程碑,DeepMind已将DRL方法应用于重大人工智能挑战。为了实现这些里程碑,DeepMind不得不构建许多专有工具和框架,以简化对DRL代理的大规模培训、实验和管理。DeepMind非常低调地公开了其中的一些技术,以便其他研究人员可以使用它们来推进DRL方法的当前状态。最近:DeepMind开源了三个不同的DRL堆栈,值得进行更深入的探索。
OpenSpiel

游戏在DRL agent的训练中发挥着重要的作用。与其他数据集不同,游戏本质上是基于测试和奖励机制,这些机制可用于训练DRL代理。然而,正如你所能想象的那样,游戏环境的组装绝非易事。
OpenSpiel是一个环境和算法的集合,用于研究游戏中的一般强化学习和搜索/规划。OpenSpiel的目的是在许多不同的游戏类型中促进一般的多智能体强化学习,其方式与一般的游戏玩法类似,但强调学习而不是竞争形式。当前版本的OpenSpiel包含了超过20种不同类型的游戏的实现(完美的信息、同时移动、不完美的信息、网格世界游戏、拍卖游戏和一些标准形式/矩阵游戏)。
OpenSpiel的核心实现基于c++和Python绑定,这有助于在不同的深度学习框架中采用它。该框架包含一个游戏组合,允许DRL代理掌握合作和竞争行为。类似地,OpenSpiel包含了多种DRL算法,包括搜索、优化和单代理。
SpriteWorld
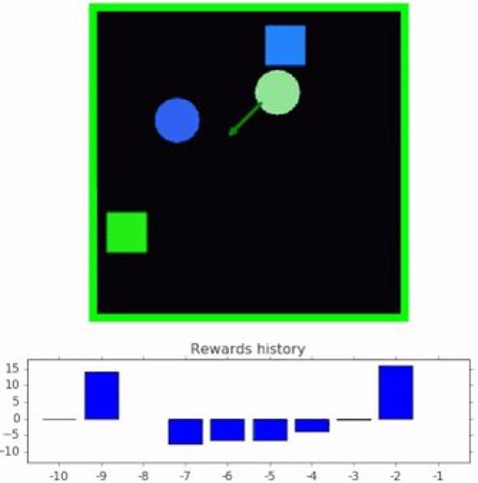
几个月前,DeepMind发表了一篇令人印象深刻的研究论文,介绍了一种基于好奇对象的搜索代理(COBRA),它使用强化学习来识别给定环境中的对象。眼镜蛇特工接受了一系列二维游戏的训练,在这些游戏中,人物可以自由移动。用于训练COBRA的环境被称为SpriteWorld,它是DeepMind最近的开源贡献之一。
Spriteworld是一个基于python的RL环境,它由一个可以自由移动的简单形状的二维竞技场组成。更具体地说,SpriteWorld是一个二维的正方形竞技场,拥有数量可变的彩色精灵,可以自由地放置和渲染,没有遮挡,但是也不会发生碰撞。SpriteWorld环境基于一系列关键特征:
- 多对象竞技场反映了现实世界的构成,杂乱的物体场景可以共享功能,但可以独立移动。这还提供了测试与任务无关的特性/对象的健壮性和组合泛化的方法。
- 连续点击-推送动作空间的结构反映了世界空间和运动的结构。它还允许代理向任何方向移动任何可见对象。
- 对象的概念不以任何特权方式提供(例如操作空间中没有对象特定的组件),并且可以被代理完全发现。
- SpriteWorld对每个DRL代理进行三个主要任务的培训:
- Goal-Finding。agent必须将一组目标对象(可通过某些特征识别,如“绿色”)带到屏幕上的隐藏位置,忽略干扰物对象(如非绿色)
- 排序。代理必须根据对象的颜色将每个对象带到目标位置。
- 集群。代理必须根据对象的颜色将其分组。
bsuite
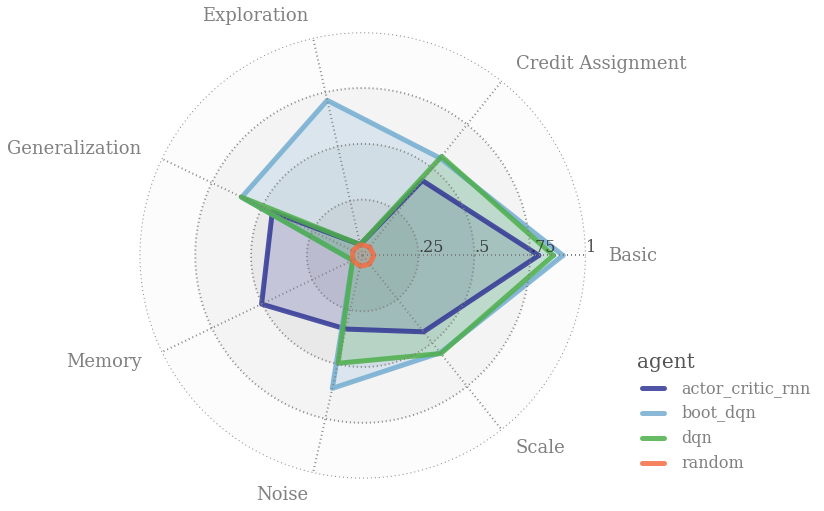
强化学习行为套件(bsuite)试图成为强化学习的MNIST。具体来说,bsuite是一组实验,旨在突出代理可伸缩性的关键方面。这些实验体现了一些基本的问题,例如“探索”或“记忆”,其方式可以很容易地测试和迭代。具体来说,bsuite有两个主要目标:
收集清晰、信息丰富和可扩展的问题,以捕捉设计高效和通用学习算法中的关键问题。
通过代理在这些共享基准上的性能来研究代理行为。
bsuite的当前实现实现了跨不同环境自动执行这些实验,并收集了相应的指标,这些指标可以简化DRL代理的培训。
正如你所看到的,DeepMind一直非常积极地开发新的强化学习技术。OpenSpiel、SpriteWorld和bsuite对于开始强化学习之旅的研究团队来说是不可思议的资产。
原文链接:https://towardsdatascience.com/deepmind-quietly-open-sourced-three-new-impressive-reinforcement-learning-frameworks-f99443910b16

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消