











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Facebook的人工智能可以在保留意义的同时简化句子
2019年10月15日 由 TGS 发表
266442
0
 简化文本的语法和结构是我们大多数人在学校学到的一项有用技能,经过长时间的应用,这几乎成了人的本能,简单而又轻易,但对于人工智能来说,由于缺乏语言知识,掌握这项技能很难。
简化文本的语法和结构是我们大多数人在学校学到的一项有用技能,经过长时间的应用,这几乎成了人的本能,简单而又轻易,但对于人工智能来说,由于缺乏语言知识,掌握这项技能很难。为此,Facebook和Inria的科学家们正在研究一种名为ACCESS的简化模型,他们声称,这种简化模型可以定制文本长度、释义量、词汇复杂性、句法复杂性和其他参数的同时,保持句子意义不变。
研究人员在一份详细介绍他们工作的文章中写道:“文本简化不仅对失语症、诵读困难和自闭症等认知障碍患者有益,对第二语言学习者和读写能力较低的人也有益。文本简化的研究主要集中在开发模型,为给定的源文本生成单一的通用简化,而不可能根据不同目标人群的需求调整输出。我们提出了一个可控的简化模型,它能为用户提供一种显式的方式,让他们可以根据需要操作和更新简化的输出。”
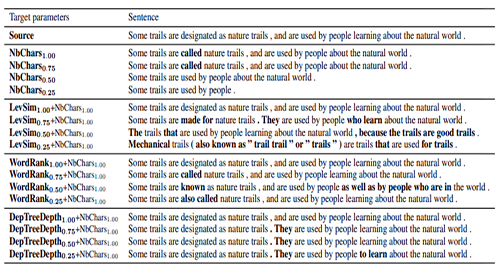 研究团队开发了一个通用的编码-解码器框架seq2seq,它可以将数据作为上下文输入,此外,研究人员还在源句的开头预先设定了一个特殊的标记值,用以计算目标句的参数(比如长度)相对于源句的值的比率。随后,他们又将该模型设定为四个选定的参数,即长度、释义、词汇复杂性和句法复杂性。最后,进行一系列测验。
研究团队开发了一个通用的编码-解码器框架seq2seq,它可以将数据作为上下文输入,此外,研究人员还在源句的开头预先设定了一个特殊的标记值,用以计算目标句的参数(比如长度)相对于源句的值的比率。随后,他们又将该模型设定为四个选定的参数,即长度、释义、词汇复杂性和句法复杂性。最后,进行一系列测验。实验中,研究小组在维基大数据集上训练了一个转换器模型,该数据集包含了来自英文维基百科和简单英文维基百科的296402个自动对齐的复杂-简单句对样本。他们用取自土耳其语料库的验证和测试集对其进行了评估,其中每个复杂的句子都有八个由亚马逊土耳其机械工人创造的“意译句子”(不拆分、结构过于简化或内容减少)。
在SARI上,ACCESS的得分为41.87,比以前的水平(40.45)有了“显著的”提高。SARI是一个流行的基准,它将预测的简化与源和目标引用进行了比较,在不考虑语法和意义保留的可读性衡量标准中,它以7.22分名列第三。研究人员在文本报告里写道:
“我们通过分析确认发现,每个参数对生成的简化都有预期的效果。在诸如长度、释义、词汇复杂性或句法复杂性等参数上对模型进行显式调整,可以显著提高它们在句子简化方面的性能。我们的方法模式,可以帮助文本简化适应不同需求的受众。”

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
AI的衍化源于现实的需求








广告


写评论取消
回复取消