











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌为最先进的人工智能视频理解模型开发了进化技术
2019年10月18日 由 TGS 发表
612193
0
为此,谷歌的研究人员进行了一系列关于自动搜索最佳计算机视觉算法的研究,并在今天的一篇博客中对其进行了详细介绍。该团队报告说,根据他们的三种方法(EvaNet、assembly enet和TinyVideoNet)确定的性能最佳体系结构证明,在多个公共数据集上的运行速度比现有的手工系统提高了10到100倍,这是一个巨大的突破。
研究人员在博客中写道:“据我们所知,这是神经结构搜索视频理解的第一项工作。我们用新的进化算法生成的视频架构,在公共数据集上的表现,远远超过最著名的、手工设计的CNN架构。”
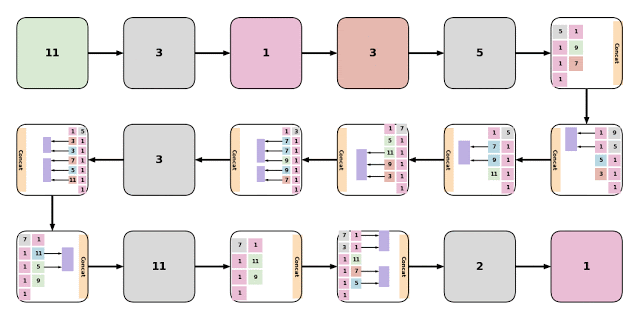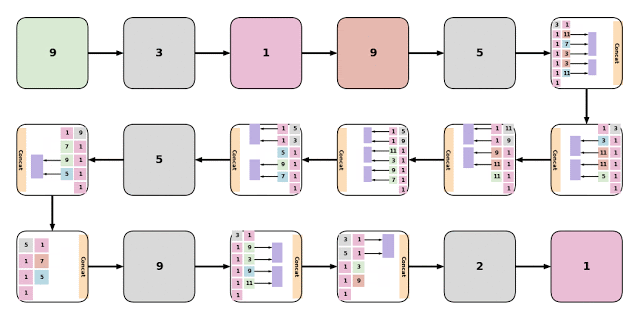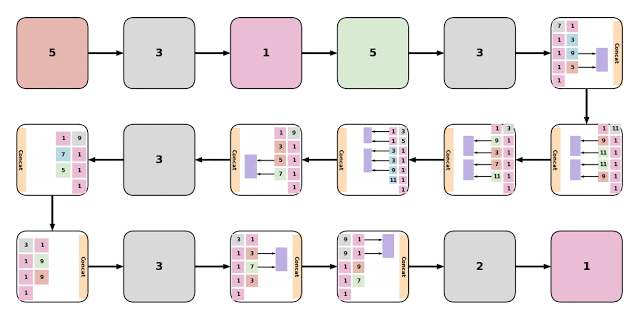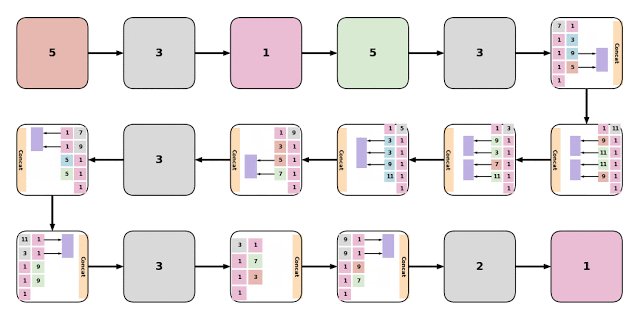 研究员认为第一个模型EvaNet是发现最优配置的模块级架构搜索器。进化算法以迭代方式更新候选AI模型,而EvaNet则是修改每个模型中的模块来生成全新的体系结构,两者是完全不同的模式。
研究员认为第一个模型EvaNet是发现最优配置的模块级架构搜索器。进化算法以迭代方式更新候选AI模型,而EvaNet则是修改每个模型中的模块来生成全新的体系结构,两者是完全不同的模式。Assemblenet是一种将不同的子模型与不同的输入模式和时间分辨率相融合的方法,在这种方法中,一个体系结构能通过进化来学习模式间的特征表示关系。谷歌官方声称,经过50到150轮训练的Assemblenet架构,在流行的视频识别数据集Charades和Moments in time(mit)上取得了最新的成果。
最后,能自动设计网络的TinyVideoNets,会为整体提供最先进的性能,它的精度极高,并且能在处理器上以37ms到100ms的速度高效运行,在图形芯片上以10ms的速度运行。此外,它的性价比极强,可以在体系结构演化过程中,考虑模型并同时变化算法以减少计算量,进而节约计算成本,提高整体收益。
在论文的最后,谷歌研究员们非常骄傲的写道:“我们的研究为视频理解开辟了新的方向,展示了机器进化Cnn的前景。”

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消