











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






文本识别系统是怎么“看”的
2019年10月20日 由 sunlei 发表
731629
0
[caption id="attachment_45782" align="aligncenter" width="740"]
 让我们来看看文本识别系统的神经网络“黑匣子”内部发生了什么[/caption]
让我们来看看文本识别系统的神经网络“黑匣子”内部发生了什么[/caption]用神经网络实现的现代文本识别系统的性能令人惊叹。他们可以接受中世纪文献的训练,能够阅读这些文献,并且只会犯很少的错误。这样的任务对我们大多数人来说都是非常困难的:看看图2,并尝试一下!
[caption id="attachment_45784" align="aligncenter" width="1121"]
 对于大多数人来说很难阅读,但是对于在这个数据集上训练的文本识别系统来说很容易[/caption]
对于大多数人来说很难阅读,但是对于在这个数据集上训练的文本识别系统来说很容易[/caption]这些系统是如何工作的?这些系统通过查看图像中的哪些部分来识别文本?他们是否利用了一些巧妙的模式?还是通过使用数据集特定模式之类的捷径来作弊?在接下来的文章中,我们将观察两个实验,以更好地理解在这样一个神经网络中发生的事情。
第一个实验:像素相关性
在我们的第一个实验中,我们提出以下问题:给定一个输入图像和正确的类(ground-truth文本),输入图像中的哪些像素表示支持,哪些表示反对正确的文本?
我们可以通过比较两个场景中正确类的分数来计算单个像素对结果的影响:
- 1、像素包含在图像中。
- 2、该像素被排除在图像之外(通过将该像素的所有可能灰度值边缘化)。
通过比较这两个分数,我们可以看到一个像素是支持还是反对正确的类。图3显示了图像中的像素与ground-truth文本“are”的相关性。红色像素投票给文本“是”,蓝色像素投票反对它。
[caption id="attachment_45785" align="aligncenter" width="514"]
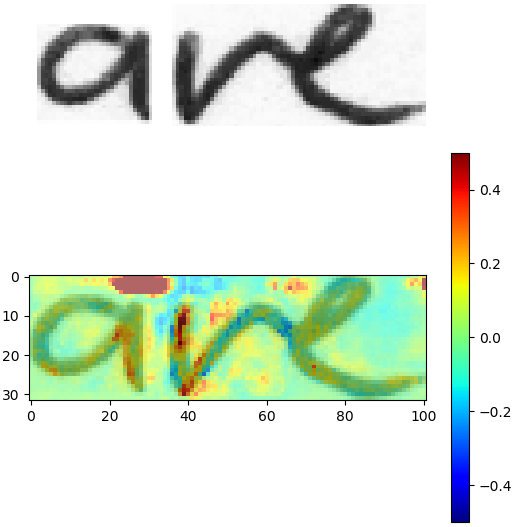 顶部:输入图像。底部:像素相关性和混合输入图像。红色像素投票赞成,蓝色像素反对正确的文本“是”[/caption]
顶部:输入图像。底部:像素相关性和混合输入图像。红色像素投票赞成,蓝色像素反对正确的文本“是”[/caption]现在,我们可以查看一些关键区域(深红、深蓝),了解哪些图像特征对神经网络做出决定是非常重要的:
- 1、“a”上方的红色区域在输入图像中是白色的,对于正确的结果“are”非常重要。你可能猜到了,如果一个黑点出现在“a”的垂直线上,那么这条垂直线可以被解释为“i”。
- 2、“r”与“e”相连,“e”将神经网络与蓝色区域相混淆。如果这两个字符被断开,这应该会增加“are”的分数。
- 3、“a”(左下内侧)内的灰色像素略微反对“are”。如果洞里面的“a”将是完全白色的,这应该增加分数。
- 4、在图像的右上方是正确投票的重要区域。目前还不清楚如何解释这一地区。
我们来研究一下假设1.- 3.都是正确的,而且明确是什么意思,4.是通过改变这些区域内的一些像素值。在图4中显示了原始和更改后的图像、正确文本的评分和识别文本。第一行显示原始图像,文本“are”的得分为0.87。
- 1、如果我们在“a”的垂直线上画一个点,“are”的分数会下降10倍,我们得到的文本是“aive”。因此,神经网络大量使用上标点来决定一条垂直线是“i”还是别的什么。
- 2、删除“r”和“e”之间的连接将使得分增加到96。即使神经网络能够隐式地分割字符,断开的字符似乎也能简化任务。
- 3、“a”内部的孔对于检测“a”非常重要,因此将灰色像素与白色像素进行交换可以将分数提高到88。
- 4、当在图像的右上角绘制一些灰度像素时,系统识别“ane”,“are”的分数下降到13。在这种情况下,系统显然已经学会了与文本无关的特性。
[caption id="attachment_45786" align="aligncenter" width="800"]
 改变一些关键区域内的像素,观察发生了什么[/caption]
改变一些关键区域内的像素,观察发生了什么[/caption]总结我们的第一个实验:系统学习了一些有意义的文本特征,比如识别字符“i”的上标点。但它也学会了一些对我们毫无意义的特征。然而,这些特性仍然帮助系统识别它所训练的数据集中的文本:这些特性让系统走捷径,而不是学习真正的文本特性。
第二个实验:平移不变性
翻译不变文本识别系统能够正确地识别独立于其在图像中的位置的文本。图5显示了文本的三个不同水平翻译。我们希望神经网络能够识别“to”的所有三个位置。
[caption id="attachment_45787" align="aligncenter" width="396"]
让我们再次从包含文本“are”的第一个实验中获取图像。我们将它一个像素一个像素地向右移动,查看正确的类的分数,以及预测的文本,如图6所示。
[caption id="attachment_45788" align="aligncenter" width="1558"]
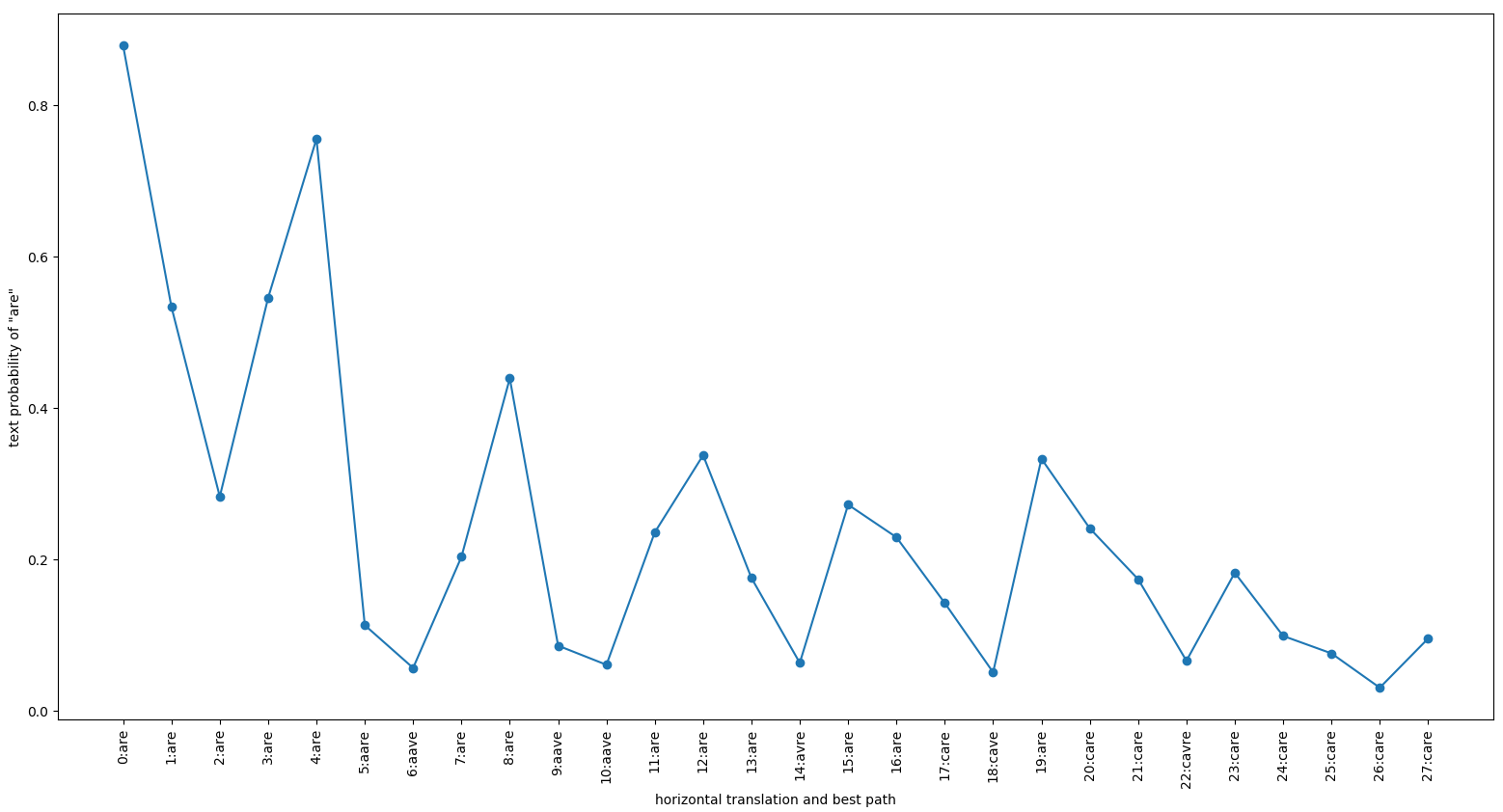 当文本逐像素向右移动时,文本的得分为“are”。x轴上的标签显示了图像移动的像素数和可识别的文本(使用最佳路径解码)[/caption]
当文本逐像素向右移动时,文本的得分为“are”。x轴上的标签显示了图像移动的像素数和可识别的文本(使用最佳路径解码)[/caption]可以看出,系统不是平移不变量。原始图像的得分为0.87。通过将图像向右移动一个像素,分数降低到0.53。将它向右移动一个像素将把分数降低到0.28。神经网络能够识别正确的文本,直到四个像素的平移。之后,系统偶尔会输出错误的结果,从右边的“aare”五个像素开始。
神经网络是在所有单词都是左对齐的IAM数据集上训练的。因此,系统从未学习过如何处理左侧空白的图像。忽略空白对我们来说可能是显而易见的——这是一种需要学习的能力。如果系统从来没有被强迫去处理这种情况——它为什么要学习它呢?
score函数的另一个有趣的特性是4个像素的周期性。这四个像素等于卷积网络的缩减因子,从宽度128像素到序列长度32像素。还需要进一步的调查来解释这种行为,但这可能是由于具有不连续性的池层造成的:将像素向右移动一个位置,它可能保持在同一池集群,也可能步到下一个,这取决于它的位置。
结论
文本识别系统学习任何有助于提高其所训练的数据集准确性的内容。如果一些随机的像素有助于识别正确的类,那么系统将使用它们。如果系统只需要处理左对齐的文本,那么它将不会学习任何其他类型的对齐。有时,它学习我们人类认为对阅读有用的特性,这些特性概括为广泛的文本样式,但有时它学习只对一个特定数据集有用的捷径。
我们必须提供不同的数据(例如混合多个数据集或使用数据增强),以确保系统真正学习文本功能,而不仅仅是一些欺骗。
参考文献
关于文本识别模型的文章
文本代码识别模型
原文链接:https://towardsdatascience.com/what-a-text-recognition-system-actually-sees-6c04864b8a98

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消