











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌提出了评估人工智能生成的音频和视频质量的新指标
2019年10月23日 由 TGS 发表
969313
0
 随着人工智能的发展,各个领域的应用多不胜数,用人工智能生成音频或视频更不是什么新鲜事,关于衡量这些“AI大师作品”的度量标准也有不少,但是,目前还没有一个被广泛采用。
随着人工智能的发展,各个领域的应用多不胜数,用人工智能生成音频或视频更不是什么新鲜事,关于衡量这些“AI大师作品”的度量标准也有不少,但是,目前还没有一个被广泛采用。例如:Frechet Inception Distance (FID),它能从目标分布和被评估的模型中获取照片,并使用人工智能对象识别系统捕捉重要特征,找出相似性。尽管它是最受欢迎的图像度量之一,但依然不是完全被大众接受的指标,为了解决这个问题,谷歌的开发人员开始了研究。
目前,他们已经有了两项成果——Frechet音频距离(FAD)和Frechet视频距离(FVD),能分别测量合成音频和视频的整体质量。
研究人员称,他们的成果与峰值信噪比、结构相似度指数或其他任何已被提出的指标都不同,FVD主要着眼于视频的整体,AUD不需要任何参考,可以用在所有类型的音频上。
软件工程师Kevin Kilgour和Thomas Unterthiner在一篇博客中写道:“生成模型评估的可靠指标对于衡量音频和视频理解领域的进展至关重要,但目前还没有这样的指标。下面展示的一些生成视频看起来是不是比其他的生成视频更加真实呢?”
 事实证明:是的。
事实证明:是的。在FAD评估中,两组音频样本(生成的和真实的)的分布,随着畸变量的增大,其重叠会相应减小,这说明合成样品的质量相对较低。
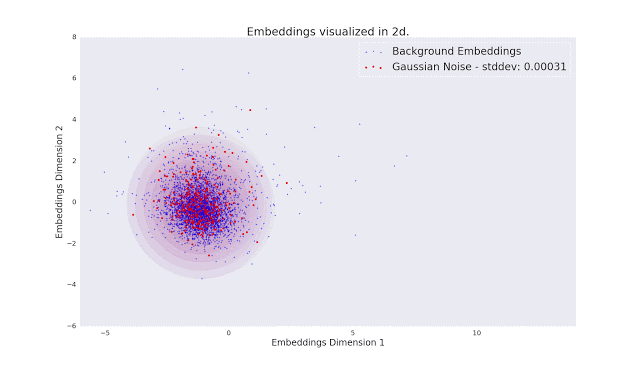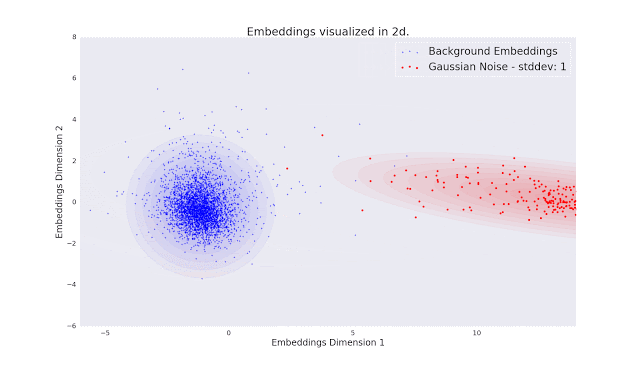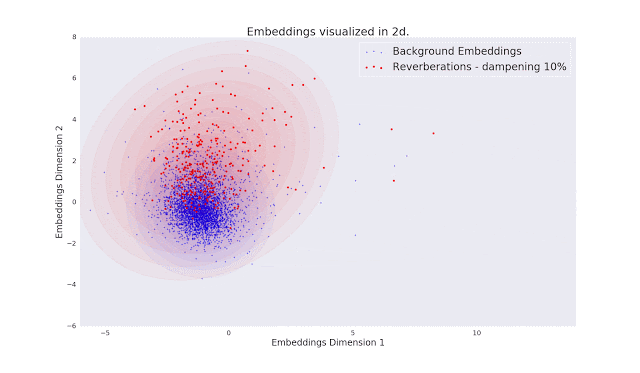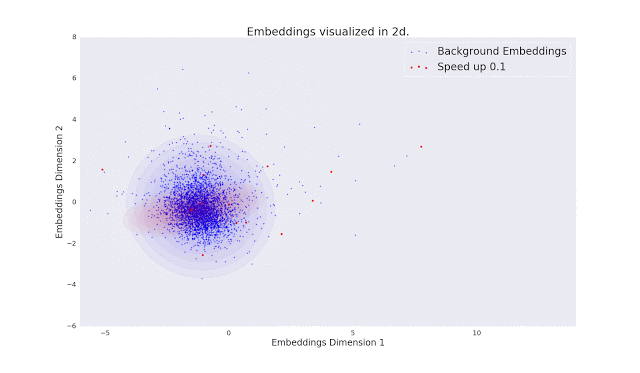 为了评估Fad和Fvd标准是否符合人类的审美,研究人员进行了一项涉及人类评估者的大规模研究。实验中,评估人员的任务是检查10000个视频对和69000个5秒音频剪辑。具体来说,就是要进行比较两种不同视频失真,以及对同一音频片段的影响实验,然后使用一个模型对收集到的成对评估集进行排序。
为了评估Fad和Fvd标准是否符合人类的审美,研究人员进行了一项涉及人类评估者的大规模研究。实验中,评估人员的任务是检查10000个视频对和69000个5秒音频剪辑。具体来说,就是要进行比较两种不同视频失真,以及对同一音频片段的影响实验,然后使用一个模型对收集到的成对评估集进行排序。最终的研究结论是:价值的比较结果表明,新指标非常符合人类的审美标准。最后,Kilgour和Unterthiner表示:“我们目前在可生成AI模型方面取得了巨大进展。FAD和FVD将帮助我们保持这一进展的可测量性,并有望引导我们改进音频和视频生成的模型。”

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消