











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌将把生物多样性研究人工智能引入Tensorflow Hub
2019年10月28日 由 TGS 发表
126369
0
 机器学习算法在生物多样性研究中有很多,但大都没有正确的归因或监督。为了提高学术水平,谷歌表示,它将发布与全球生物多样性信息基金(GBIF)、自然主义者和Visipedia合作开发的机构人工智能工作流程。这家科技巨头的研究人员表示,该工作流程将支持跨团队的数据聚合与协作,同时确保公司遵守标准化的许可条款,使用兼容的文件格式,并为手头的任务提供公平、充分的数据覆盖。
机器学习算法在生物多样性研究中有很多,但大都没有正确的归因或监督。为了提高学术水平,谷歌表示,它将发布与全球生物多样性信息基金(GBIF)、自然主义者和Visipedia合作开发的机构人工智能工作流程。这家科技巨头的研究人员表示,该工作流程将支持跨团队的数据聚合与协作,同时确保公司遵守标准化的许可条款,使用兼容的文件格式,并为手头的任务提供公平、充分的数据覆盖。“机器学习用于物种识别的前景即将实现,这揭示了它在生物多样性研究中的变革潜力。”访问教师Serge Belongie和谷歌研究工程主任Hartwig Adam在一篇将于荷兰莱顿生物多样性下次会议上发表的学术文章中写道,“国际研讨会的特色比赛,多以发展最先进的分类算法,根据野生动物相机陷阱的图像压制花卉标本和植物标本表。这些竞赛产生的令人鼓舞的结果,会激励我们将生物多样性数据集和ML模型的可用性,从车间规模扩大到全球范围。”
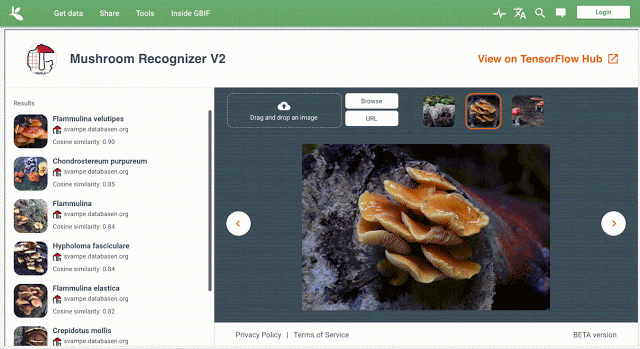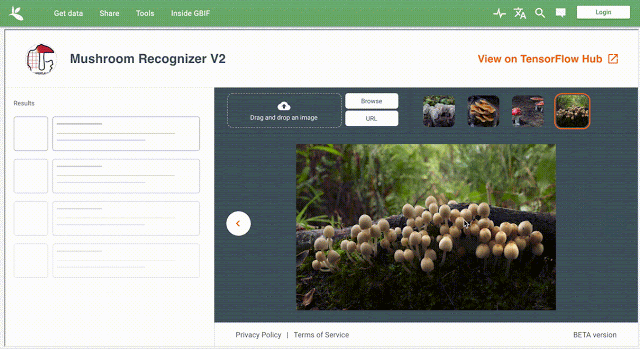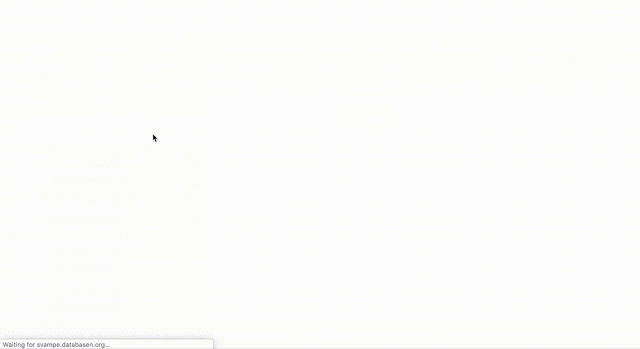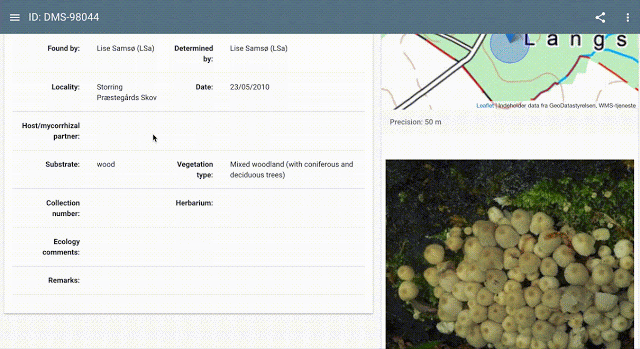 工作流程将由两部分组成:GBIF打包的数据集,以及由谷歌与Visipedia培训和发布的模型。前者将被审查,以确保它们满足基线许可和引用要求,它们将通过数字对象标识符(用于唯一标识对象的持久标识符或句柄)发布,并通过国际标准化组织的DOI引用图进行链接。与此同时,后者将与TensorFlow Hub(谷歌的机器学习模型公共存储库)的文档一起提供,其中将包含关于出处、体系结构、许可证信息等诸多信息,以及在用户提供的图像上运行的交互式模型演示。
工作流程将由两部分组成:GBIF打包的数据集,以及由谷歌与Visipedia培训和发布的模型。前者将被审查,以确保它们满足基线许可和引用要求,它们将通过数字对象标识符(用于唯一标识对象的持久标识符或句柄)发布,并通过国际标准化组织的DOI引用图进行链接。与此同时,后者将与TensorFlow Hub(谷歌的机器学习模型公共存储库)的文档一起提供,其中将包含关于出处、体系结构、许可证信息等诸多信息,以及在用户提供的图像上运行的交互式模型演示。Belongie和Adam表示:“学术研究传统的核心是引用和归属通用惯例,因此,当ML将其触角延伸到生命科学领域时,它应该把这些惯例的适当对应物也带来。更广泛地说,人们越来越意识到道德、公平和透明度在ML社区中的重要性……我们期待着与全球各地的机构合作,以实现机器学习在生物多样性方面的创新应用。”
机器学习由来已久,在各个领域中皆颇有建树,生物领域中应用的例子也是屡见不鲜,但关于多样性的研究目前尚处于起步阶段,谷歌的探索,无论成果如何,皆会为该领域积累重要的经验。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消