Google的Live Caption可以为视频添加实时字幕
2019年10月31日 由 KING 发表
68952
0
音频内容的字幕不仅对于聋哑人和听力障碍者至关重要,同时也会使所有人受益。不论是在火车上,在会议上,在晚上还是在孩子们睡觉时,静音观看视频都是很普遍的现象。研究表明,字幕可以使用户观看视频的时间延长近40%。然而,字幕支持插件在各个应用程序之间甚至在应用程序内部都是零散的,从而导致无法访问大量音频内容。
最近,Google AI团队推出了Live Caption,这是一项新的功能,可为您在手机上播放的媒体自动添加字幕。字幕是实时添加的,完全在设备上进行,无需使用网络资源,因此可以保护隐私并降低延迟。该功能目前仅可在Google Pixel 4和Pixel 4 XL上使用,将于今年晚些时候在Pixel 3型号上推出,并将很快在其他Android设备上广泛使用。
建立准确高效的语音识别模型
实时字幕通过以下三种设备上深度学习模型的组合来工作:用于语音识别的递归神经网络(RNN)序列转导模型(RNN-T)、用于语音识别的基于文本的递归神经网络模型无声标点和用于声音事件分类的卷积神经网络(CNN)模型。实时字幕集成了来自三个模型的信号,以创建一个字幕轨道,在该轨道上,声音事件标签出现时不会中断语音识别结果的进程。在并行更新文本时,它会自动预测标点符号。
对于声音识别,该团队利用在AudioSet数据集之上构建的模型,为进行声音事件检测做准备。声音识别模型不仅可用于生成流行的声音效果标签,还可用于检测语音时段。全自动语音识别(ASR)RNN-T驱动仅在语音时段期间运行,以最小化存储器和电池使用。例如,当检测到音乐并且音频流中不存在语音时,[MUSIC]标签将出现在屏幕上,并且ASR模型将被卸载。仅当语音再次出现在音频流中时,ASR模型才被加载回内存。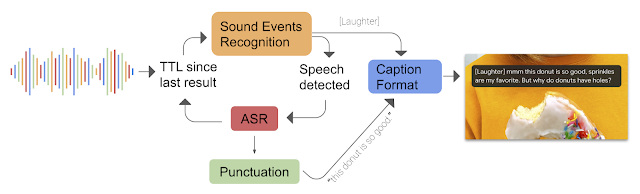 为了使实时字幕能够长时间连续运行,Live Caption的ASR模型使用多种技术(例如神经连接修剪)针对边缘设备进行了优化,与全尺寸语音模型相比,该技术将功耗降低了50%。然而,尽管该模型在能源效率方面要高得多,但在各种场景中仍然表现 良好,同时还对背景噪声具有鲁棒性。
为了使实时字幕能够长时间连续运行,Live Caption的ASR模型使用多种技术(例如神经连接修剪)针对边缘设备进行了优化,与全尺寸语音模型相比,该技术将功耗降低了50%。然而,尽管该模型在能源效率方面要高得多,但在各种场景中仍然表现 良好,同时还对背景噪声具有鲁棒性。
基于文本的标点符号模型经过优化,可使用比云计算更小的体系结构在设备上连续运行。随着字幕的形成,语音识别结果每秒会快速更新几次。为了节省计算资源并提供流畅的用户体验,对最近识别的句子中文本的结尾执行标点预测,并且如果下一个更新的ASR结果没有更改该文本,则将先前的标点结果保留并重新使用。
展望未来
Live Caption现在在Pixel 4上以英语提供,并且很快将在Pixel 3和其他Android设备上提供。我们希望通过扩展对其他语言的支持并进一步改善格式,以提高字幕的可感知准确性和连贯性,从而将这一功能带给更多用户。





























