











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






损失函数详解
2019年10月31日 由 sunlei 发表
674000
0
在任何深度学习项目中,配置损失函数是确保模型以预期方式工作的最重要步骤之一。损失函数可以为神经网络提供很多实际的灵活性,它将定义网络的输出如何与网络的其他部分连接。
神经网络可以完成几项任务,从预测连续值(如每月支出)到分类离散类(如猫和狗)。每个不同的任务需要不同类型的损失,因为输出格式不同。对于非常特殊的任务,如何定义损失取决于我们自己。
从一个非常简单的角度来看,损失函数(J)可以定义为一个包含两个参数的函数:
[caption id="attachment_46309" align="aligncenter" width="616"]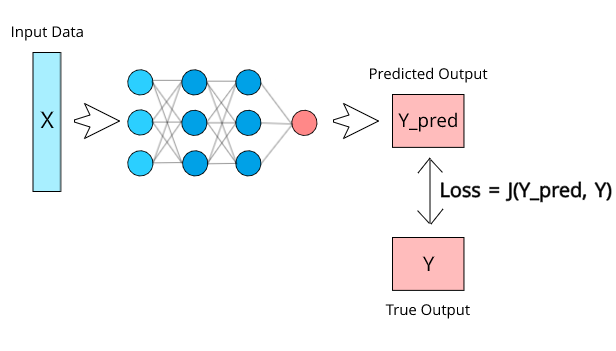 神经网络损耗显示[/caption]
神经网络损耗显示[/caption]
这个函数将通过比较模型预测的值和它应该输出的实际值来计算我们的模型的性能有多差。如果Y_pred离Y很远,则损失值将非常高。但是,如果两个值几乎相同,则损失值将非常低。因此,我们需要保留一个损失函数,当模型在数据集上训练时,它可以有效地惩罚模型。
如果损失很高,这个巨大的值会在训练时通过网络传播,权重也会比平时稍有变化。如果它很小,那么权重不会有太大变化,因为网络已经做得很好了。
这种情况有点类似于为考试而学习。如果一个人在考试中表现不好,我们可以说损失是非常大的,而这个人将不得不改变自己的许多事情,以便下次得到更好的分数。然而,如果考试顺利的话,他们就不会做任何与下次考试不同的事情了。
现在让我们把分类看作一项任务,并了解在这种情况下损失函数是如何工作的。
当神经网络试图预测一个离散值时,我们可以认为它是一个分类模型。这可能是一个试图预测图像中存在何种动物的网络,也可能是一封电子邮件是否是垃圾邮件的网络。首先让我们看看如何表示分类神经网络的输出。
[caption id="attachment_46310" align="aligncenter" width="345"]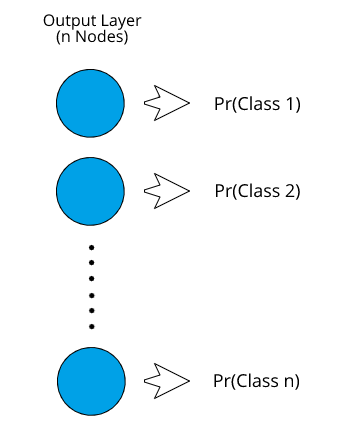 分类神经网络输出格式[/caption]
分类神经网络输出格式[/caption]
输出层的节点数量将取决于数据中存在的类的数量。每个节点将代表一个类。每个输出节点的值本质上表示该类成为正确类的概率。
一旦我们得到了所有不同类的概率,我们将考虑具有最高概率的类作为该实例的预测类。首先,让我们探讨如何进行二进制分类。
在二进制分类中,即使我们在两个类之间进行预测,输出层中也只有一个节点。为了得到概率格式的输出,我们需要应用一个激活函数。因为概率需要介于0和1之间的值,所以我们将使用sigmoid函数,它可以将任何实际值压缩为介于0和1之间的值。
[caption id="attachment_46313" align="aligncenter" width="396"]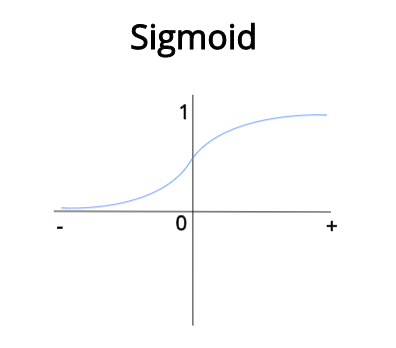 函数图形可视化[/caption]
函数图形可视化[/caption]
当sigmoid的输入变得更大并趋于正无穷时,sigmoid的输出将趋于1。当输入变小并趋于负无穷大时,输出将趋于0。现在我们保证总是得到一个介于0和1之间的值,这正是我们所需要的,因为我们需要概率。
如果输出高于0.5(50%概率),我们将认为它属于正类,如果低于0.5,我们将认为它属于负类。例如,如果我们训练一个网络来对猫和狗进行分类,我们可以给狗分配正类,狗数据集中的输出值为1,同样地,猫将被分配负类,猫的输出值为0。
我们用于二元分类的损失函数称为二元交叉熵(BCE)。该函数有效地惩罚了用于二值分类任务的神经网络。让我们看看这个函数的外观。
[caption id="attachment_46314" align="aligncenter" width="771"]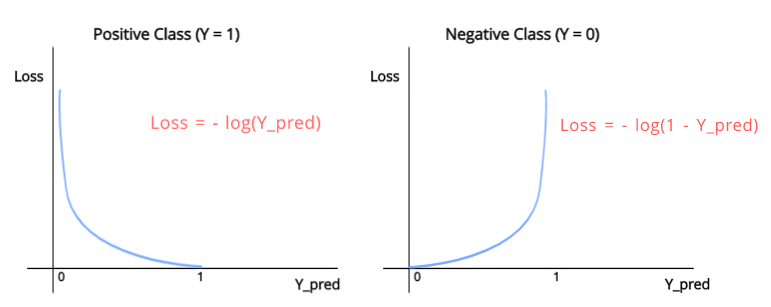 二元交叉熵损失图[/caption]
二元交叉熵损失图[/caption]
如您所见,有两个单独的函数,每个函数对应一个Y值。当我们需要预测正的类(Y = 1)时,我们将使用
当我们需要预测负的类(Y = 0)时,我们将使用
正如你在图表中看到的。第一个函数,当Y_pred = 1,损失= 0,这是有道理的,因为Y_pred与y完全相同,当Y_pred值变得更接近0,我们可以观察到的损失价值以非常高的速度增加,当Y_pred变成0它趋于无穷大。这是因为,从分类的角度来看,0和1必须是完全相反的,因为它们各自代表完全不同的类。因此,当Y_pred为0时, Y为1时,损失将非常大,以便网络更有效地学习它的错误。
[caption id="attachment_46315" align="aligncenter" width="516"]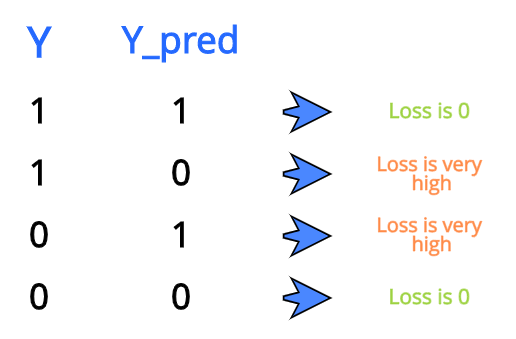 二元分类损失比较[/caption]
二元分类损失比较[/caption]
我们可以用数学方法将整个损失函数表示为一个方程式,如下所示:
[caption id="attachment_46316" align="aligncenter" width="1075"]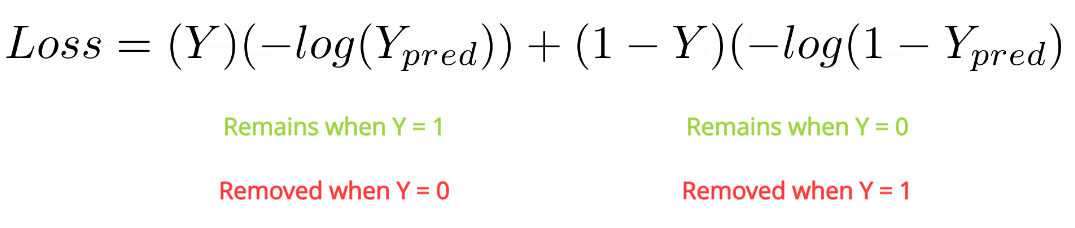 二元交叉熵全方程[/caption]
二元交叉熵全方程[/caption]
这个丢失函数也称为日志丢失。这就是为二值分类神经网络设计损失函数的方法。现在让我们来看看如何定义多类分类网络的损失。
当我们需要我们的模型每次预测一个可能的类输出时,多类分类是合适的。现在,由于我们仍在处理概率问题,所以对所有输出节点应用sigmoid可能是有意义的,这样我们就可以得到所有输出的0-1之间的值,但这里有一个问题。当我们考虑多个类的概率时,我们需要确保所有单个概率之和等于1,因为这就是概率的定义。应用sigmoid并不能确保总和总是等于1,因此我们需要使用另一个激活函数。
我们在本例中使用的激活函数是softmax。这个函数确保所有输出节点的值都在0-1之间,并且所有输出节点值的总和总是等于1。softmax的计算公式如下:
[caption id="attachment_46317" align="aligncenter" width="956"]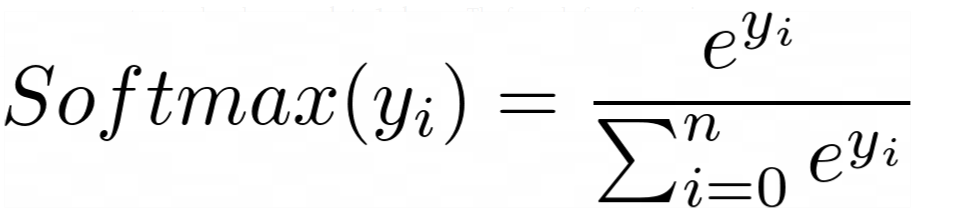 Softmax公式[/caption]
Softmax公式[/caption]
让我们用一个例子来形象地说明这一点:
[caption id="attachment_46318" align="aligncenter" width="417"]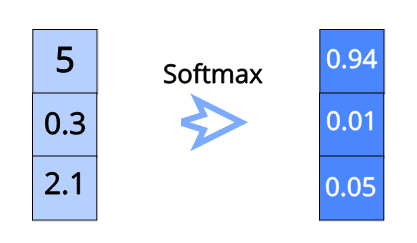 Softmax可视化例子[/caption]
Softmax可视化例子[/caption]
正如你所看到的,我们只是把所有的值都转化成一个指数函数。之后,为了确保它们都在0-1的范围内为了确保所有输出值的和等于1,我们只是用每个指数除以所有指数的和。
那么,为什么我们必须在标准化之前通过一个指数来传递每个值呢?为什么我们不能将这些值本身正常化呢?这是因为softmax的目标是确保一个值非常高(接近1),而所有其他值非常低(接近0)。然后我们标准化,因为我们需要概率。
现在我们的输出是正确的格式,让我们来看看如何为此配置损失函数。好的方面是,损失函数在本质上与二元分类是相同的。我们将在每个输出节点上针对其各自的目标值应用日志损失,然后我们将在所有输出节点上找到日志损失的总和。
[caption id="attachment_46319" align="aligncenter" width="536"]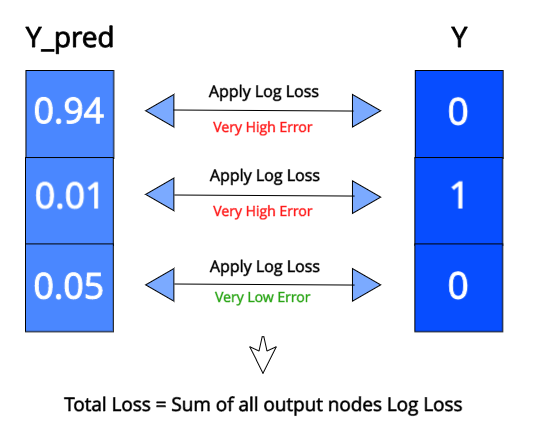 分类交叉熵可视化[/caption]
分类交叉熵可视化[/caption]
这种损失称为分类交叉熵。现在让我们来看一个特殊的分类案例,叫做多标签分类。
多标签分类是在模型需要预测多个类作为输出时完成的。例如,假设你正在训练一个神经网络来预测一些食物图片中的成分。我们需要预测多种成分所以Y中会有多种1。
在这种情况下,我们不能使用softmax,因为softmax总是会强制一个类变成1,而其他类变成0。因此,我们可以简单地对所有输出节点值保持sigmoid,因为我们试图预测每个类的单独概率。
至于损失,我们可以直接在每个节点上使用日志损失并将其求和,类似于我们在多类分类中所做的。
既然我们已经讨论了分类,现在让我们继续讨论回归。
在回归中,我们的模型试图预测一个连续的值。回归模型的一些例子是:
在回归模型中,我们的神经网络对于我们试图预测的每个连续值都有一个输出节点。回归损失是通过直接比较输出值和真实值来计算的。
我们在回归模型中最常用的损失函数是均方误差损失函数。在这里,我们只需计算Y和Y_pred之间的差的平方,然后对所有数据求平均值。假设有n个数据点:
[caption id="attachment_46320" align="aligncenter" width="1058"]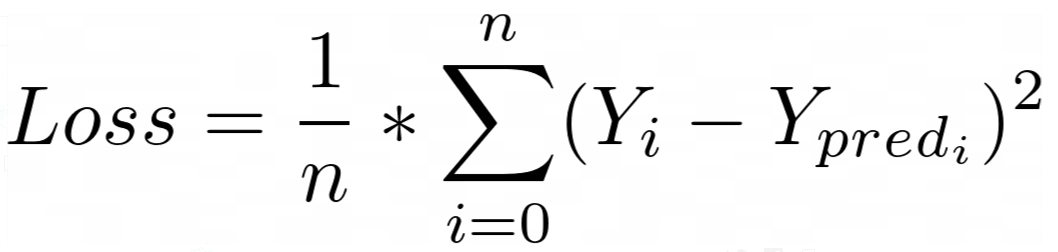 均方误差损失函数[/caption]
均方误差损失函数[/caption]
这里Y_i和Y_pred_i指的是数据集中的第i个Y值,对应的Y_pred指的是来自神经网络的相同数据。
本文到此结束。希望现在您对如何为深度学习中的各种任务配置损失函数有了更深入的理解。感谢您的阅读!
原文链接:https://medium.com/deep-learning-demystified/loss-functions-explained-3098e8ff2b27
神经网络可以完成几项任务,从预测连续值(如每月支出)到分类离散类(如猫和狗)。每个不同的任务需要不同类型的损失,因为输出格式不同。对于非常特殊的任务,如何定义损失取决于我们自己。
从一个非常简单的角度来看,损失函数(J)可以定义为一个包含两个参数的函数:
- 预测输出
- 真实输出
[caption id="attachment_46309" align="aligncenter" width="616"]
神经网络损耗显示[/caption]这个函数将通过比较模型预测的值和它应该输出的实际值来计算我们的模型的性能有多差。如果Y_pred离Y很远,则损失值将非常高。但是,如果两个值几乎相同,则损失值将非常低。因此,我们需要保留一个损失函数,当模型在数据集上训练时,它可以有效地惩罚模型。
如果损失很高,这个巨大的值会在训练时通过网络传播,权重也会比平时稍有变化。如果它很小,那么权重不会有太大变化,因为网络已经做得很好了。
这种情况有点类似于为考试而学习。如果一个人在考试中表现不好,我们可以说损失是非常大的,而这个人将不得不改变自己的许多事情,以便下次得到更好的分数。然而,如果考试顺利的话,他们就不会做任何与下次考试不同的事情了。
现在让我们把分类看作一项任务,并了解在这种情况下损失函数是如何工作的。
分类损失
当神经网络试图预测一个离散值时,我们可以认为它是一个分类模型。这可能是一个试图预测图像中存在何种动物的网络,也可能是一封电子邮件是否是垃圾邮件的网络。首先让我们看看如何表示分类神经网络的输出。
[caption id="attachment_46310" align="aligncenter" width="345"]
分类神经网络输出格式[/caption]输出层的节点数量将取决于数据中存在的类的数量。每个节点将代表一个类。每个输出节点的值本质上表示该类成为正确类的概率。
Pr(Class 1) = Probability of Class 1 being the correct class
一旦我们得到了所有不同类的概率,我们将考虑具有最高概率的类作为该实例的预测类。首先,让我们探讨如何进行二进制分类。
二进制分类
在二进制分类中,即使我们在两个类之间进行预测,输出层中也只有一个节点。为了得到概率格式的输出,我们需要应用一个激活函数。因为概率需要介于0和1之间的值,所以我们将使用sigmoid函数,它可以将任何实际值压缩为介于0和1之间的值。
[caption id="attachment_46313" align="aligncenter" width="396"]
函数图形可视化[/caption]当sigmoid的输入变得更大并趋于正无穷时,sigmoid的输出将趋于1。当输入变小并趋于负无穷大时,输出将趋于0。现在我们保证总是得到一个介于0和1之间的值,这正是我们所需要的,因为我们需要概率。
如果输出高于0.5(50%概率),我们将认为它属于正类,如果低于0.5,我们将认为它属于负类。例如,如果我们训练一个网络来对猫和狗进行分类,我们可以给狗分配正类,狗数据集中的输出值为1,同样地,猫将被分配负类,猫的输出值为0。
我们用于二元分类的损失函数称为二元交叉熵(BCE)。该函数有效地惩罚了用于二值分类任务的神经网络。让我们看看这个函数的外观。
[caption id="attachment_46314" align="aligncenter" width="771"]
二元交叉熵损失图[/caption]如您所见,有两个单独的函数,每个函数对应一个Y值。当我们需要预测正的类(Y = 1)时,我们将使用
Loss = -log(Y_pred)
当我们需要预测负的类(Y = 0)时,我们将使用
Loss = -log(1-Y_pred)
正如你在图表中看到的。第一个函数,当Y_pred = 1,损失= 0,这是有道理的,因为Y_pred与y完全相同,当Y_pred值变得更接近0,我们可以观察到的损失价值以非常高的速度增加,当Y_pred变成0它趋于无穷大。这是因为,从分类的角度来看,0和1必须是完全相反的,因为它们各自代表完全不同的类。因此,当Y_pred为0时, Y为1时,损失将非常大,以便网络更有效地学习它的错误。
[caption id="attachment_46315" align="aligncenter" width="516"]
二元分类损失比较[/caption]我们可以用数学方法将整个损失函数表示为一个方程式,如下所示:
[caption id="attachment_46316" align="aligncenter" width="1075"]
二元交叉熵全方程[/caption]这个丢失函数也称为日志丢失。这就是为二值分类神经网络设计损失函数的方法。现在让我们来看看如何定义多类分类网络的损失。
多类分类
当我们需要我们的模型每次预测一个可能的类输出时,多类分类是合适的。现在,由于我们仍在处理概率问题,所以对所有输出节点应用sigmoid可能是有意义的,这样我们就可以得到所有输出的0-1之间的值,但这里有一个问题。当我们考虑多个类的概率时,我们需要确保所有单个概率之和等于1,因为这就是概率的定义。应用sigmoid并不能确保总和总是等于1,因此我们需要使用另一个激活函数。
我们在本例中使用的激活函数是softmax。这个函数确保所有输出节点的值都在0-1之间,并且所有输出节点值的总和总是等于1。softmax的计算公式如下:
[caption id="attachment_46317" align="aligncenter" width="956"]
Softmax公式[/caption]让我们用一个例子来形象地说明这一点:
[caption id="attachment_46318" align="aligncenter" width="417"]
Softmax可视化例子[/caption]正如你所看到的,我们只是把所有的值都转化成一个指数函数。之后,为了确保它们都在0-1的范围内为了确保所有输出值的和等于1,我们只是用每个指数除以所有指数的和。
那么,为什么我们必须在标准化之前通过一个指数来传递每个值呢?为什么我们不能将这些值本身正常化呢?这是因为softmax的目标是确保一个值非常高(接近1),而所有其他值非常低(接近0)。然后我们标准化,因为我们需要概率。
现在我们的输出是正确的格式,让我们来看看如何为此配置损失函数。好的方面是,损失函数在本质上与二元分类是相同的。我们将在每个输出节点上针对其各自的目标值应用日志损失,然后我们将在所有输出节点上找到日志损失的总和。
[caption id="attachment_46319" align="aligncenter" width="536"]
分类交叉熵可视化[/caption]这种损失称为分类交叉熵。现在让我们来看一个特殊的分类案例,叫做多标签分类。
多标签分类
多标签分类是在模型需要预测多个类作为输出时完成的。例如,假设你正在训练一个神经网络来预测一些食物图片中的成分。我们需要预测多种成分所以Y中会有多种1。
在这种情况下,我们不能使用softmax,因为softmax总是会强制一个类变成1,而其他类变成0。因此,我们可以简单地对所有输出节点值保持sigmoid,因为我们试图预测每个类的单独概率。
至于损失,我们可以直接在每个节点上使用日志损失并将其求和,类似于我们在多类分类中所做的。
既然我们已经讨论了分类,现在让我们继续讨论回归。
回归损失
在回归中,我们的模型试图预测一个连续的值。回归模型的一些例子是:
- 房价预测
- 人年龄的预测
在回归模型中,我们的神经网络对于我们试图预测的每个连续值都有一个输出节点。回归损失是通过直接比较输出值和真实值来计算的。
我们在回归模型中最常用的损失函数是均方误差损失函数。在这里,我们只需计算Y和Y_pred之间的差的平方,然后对所有数据求平均值。假设有n个数据点:
[caption id="attachment_46320" align="aligncenter" width="1058"]
均方误差损失函数[/caption]这里Y_i和Y_pred_i指的是数据集中的第i个Y值,对应的Y_pred指的是来自神经网络的相同数据。
本文到此结束。希望现在您对如何为深度学习中的各种任务配置损失函数有了更深入的理解。感谢您的阅读!
原文链接:https://medium.com/deep-learning-demystified/loss-functions-explained-3098e8ff2b27

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
图卷积网络图深度学习(下)








广告


写评论取消
回复取消