











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






心灵阅读:使用人工神经网络预测从EEG Readings中看到的图像类别
2017年08月22日 由 xiaoshan.xiang 发表
372720
0
人工神经网络如何理解我们大脑的神经网络?
在3月24日至26日的周末,ycombinator支持的创业公司DeepGram举办了一场深度学习黑客马拉松。参加这个周末活动的人包括谷歌大脑的发言人和法官。我选择了由DeepGram提出的EEG readings数据集,它来自斯坦福的一个研究项目,在该项目使用线性判别分析来预测测试对象看到的图像类别。Winning Kaggle竞赛小组已经成功地将人工神经网络应用于EEG数据。人工神经网络模型能在斯坦福的数据集上做得更好吗?
测试对象的六个主要类别是:人的身体,人的脸,动物的身体,动物的脸,自然的物体和人造的物体。

斯坦福的研究论文含有下载他们的数据集的链接。可以在GitHub.上找到。
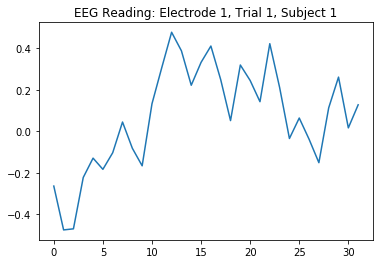
根据数据集附带的README文本文件,他们在测试对象上使用的EEG传感器就是这个装置:该装置有124个电极,每人每次显示一个图像,每个电极可以收集32个读数,每次读数为62.5 Hz。以下是第一次试验时EEG readings中电极1的图像,该图表示在第一个测试对象(十分之一)上进行试验时,测试对象显示图像的时间大约为半秒。
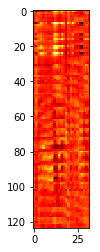
现在,想象一下如何安排EEG readings,每一个试验都是32×124的热图。
近年来,卷积神经网络(CNN)在计算机视觉任务方面表现良好。CNN是否可以在这幅热图上进行训练,并且准确地猜出每个测试对象查看的图像的类别?
训练分类器前的第一件事是检查类数据的平衡。如果一种图像类别在数据中被过多地表示,我们的神经网络就会被训练成偏向于那个被夸大的类别,并有可能对少见的类别进行错误分类。幸运的是,我们的数据集是均衡的。
经过一些实验,我最终选定了一个二维卷积层,然后是致密层部分。为了减少过度拟合,增加了Dropout。更复杂的层和池似乎没有帮助。但不要相信我的话。我鼓励你尝试不同的架构和超参数。例如,尝试不同的激活函数,而不是纠正深度学习中常见的线性单元(ReLU),然后在我的模型中应用。或者,尝试不同大小的密集层和卷积层过滤器,内核和跨步。
前9个测试对象的EEG readings作为训练集,而第十个测试对象的 EEG readings作为抵抗集。为了评估你的模型是否适用于“新人”,不能在训练数据中包含测试对象(新人)的读数。
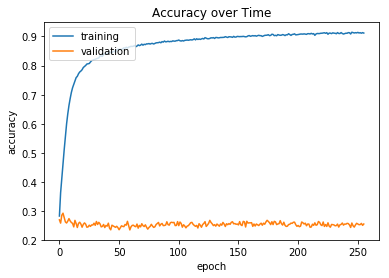
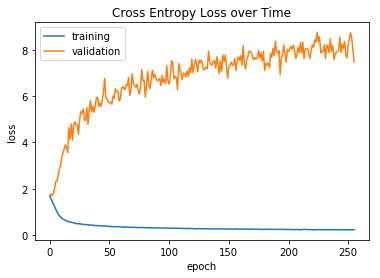
下面的两个图显示了CNN模型在测试数据集上的准确性和分类交叉熵损失的训练历史,以及holdout数据集(在图中标记为“validation”)。当模型过度拟合训练数据的准确度达到90%以上时,holdout设置的精度稳定在25%左右。然而,holdout的分类交叉熵损失加剧了。由于黑客马拉松的时间限制,我没有时间进行交叉验证,也没有时间去尝试不同的CNN架构,所以我把这些作为练习留给读者。
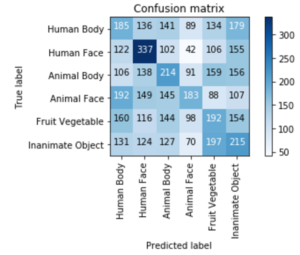
测量精度和交叉熵损失是对模型性能的粗略评估。图中显示混乱的矩阵提供了更多的细节,说明CNN的预测与真实的图像类别匹配,而这一类别是holdout的测试对象所看到的。CNN对人类面部的EEG readings的分类做得很好。
这篇文章已经表明,CNN是一个很好的分类EEG数据的方法。也许你能做得更好。一些建议尝试:
在3月24日至26日的周末,ycombinator支持的创业公司DeepGram举办了一场深度学习黑客马拉松。参加这个周末活动的人包括谷歌大脑的发言人和法官。我选择了由DeepGram提出的EEG readings数据集,它来自斯坦福的一个研究项目,在该项目使用线性判别分析来预测测试对象看到的图像类别。Winning Kaggle竞赛小组已经成功地将人工神经网络应用于EEG数据。人工神经网络模型能在斯坦福的数据集上做得更好吗?
测试对象的六个主要类别是:人的身体,人的脸,动物的身体,动物的脸,自然的物体和人造的物体。
数据集描述和表达
斯坦福的研究论文含有下载他们的数据集的链接。可以在GitHub.上找到。
根据数据集附带的README文本文件,他们在测试对象上使用的EEG传感器就是这个装置:该装置有124个电极,每人每次显示一个图像,每个电极可以收集32个读数,每次读数为62.5 Hz。以下是第一次试验时EEG readings中电极1的图像,该图表示在第一个测试对象(十分之一)上进行试验时,测试对象显示图像的时间大约为半秒。
现在,想象一下如何安排EEG readings,每一个试验都是32×124的热图。
近年来,卷积神经网络(CNN)在计算机视觉任务方面表现良好。CNN是否可以在这幅热图上进行训练,并且准确地猜出每个测试对象查看的图像的类别?
训练分类器前的第一件事是检查类数据的平衡。如果一种图像类别在数据中被过多地表示,我们的神经网络就会被训练成偏向于那个被夸大的类别,并有可能对少见的类别进行错误分类。幸运的是,我们的数据集是均衡的。
模型架构
经过一些实验,我最终选定了一个二维卷积层,然后是致密层部分。为了减少过度拟合,增加了Dropout。更复杂的层和池似乎没有帮助。但不要相信我的话。我鼓励你尝试不同的架构和超参数。例如,尝试不同的激活函数,而不是纠正深度学习中常见的线性单元(ReLU),然后在我的模型中应用。或者,尝试不同大小的密集层和卷积层过滤器,内核和跨步。
模型训练
前9个测试对象的EEG readings作为训练集,而第十个测试对象的 EEG readings作为抵抗集。为了评估你的模型是否适用于“新人”,不能在训练数据中包含测试对象(新人)的读数。
下面的两个图显示了CNN模型在测试数据集上的准确性和分类交叉熵损失的训练历史,以及holdout数据集(在图中标记为“validation”)。当模型过度拟合训练数据的准确度达到90%以上时,holdout设置的精度稳定在25%左右。然而,holdout的分类交叉熵损失加剧了。由于黑客马拉松的时间限制,我没有时间进行交叉验证,也没有时间去尝试不同的CNN架构,所以我把这些作为练习留给读者。
模型质量
测量精度和交叉熵损失是对模型性能的粗略评估。图中显示混乱的矩阵提供了更多的细节,说明CNN的预测与真实的图像类别匹配,而这一类别是holdout的测试对象所看到的。CNN对人类面部的EEG readings的分类做得很好。
进一步的工作
这篇文章已经表明,CNN是一个很好的分类EEG数据的方法。也许你能做得更好。一些建议尝试:
- 交叉验证
- 不同的层数,高参数,dropout,激活
- 细粒度的分类与72个图像子类别

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消