利用深度学习为2D动画生成实时同步口型
2019年11月14日 由 KING 发表
221402
0
实时二维动画是一种相当新颖而强大的交流形式,它使表演者可以实时控制卡通人物,同时与其他演员或观众互动和即兴表演。例如迪斯尼的《星际大战:邪恶力量》和My Little Pony通过YouTube或Facebook Live与粉丝们进行实时聊天会话。
制作逼真的实时2D动画需要使用交互式系统,该系统可以自动将人类表演实时转换为动画。这些系统的关键是获得良好的口型同步,这实质上意味着动画人物的嘴巴在说话时会适当移动,模仿在表演者的嘴巴中观察到的动作。
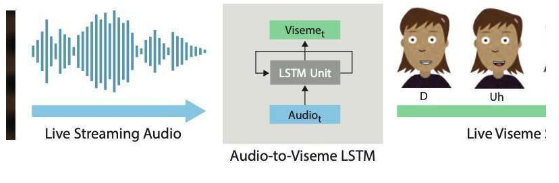
良好的口型同步可以使实时2D动画更具说服力,使动画角色可以更真实地体现它们的功能。相反,不当的口型同步通常会破坏角色作为现场表演或对话参与者的体验。 在最近公布在arXiv上的论文中,两位研究人员介绍了在Adobe和华盛顿大学推出的深基础的学习互动系统,可自动生成分层2D动画人物唇音同步。他们开发的系统使用了长短期记忆(LSTM)模型,一种递归神经网络(RNN)架构,该架构通常应用于涉及对数据进行分类或处理以及进行预测的任务。
在最近公布在arXiv上的论文中,两位研究人员介绍了在Adobe和华盛顿大学推出的深基础的学习互动系统,可自动生成分层2D动画人物唇音同步。他们开发的系统使用了长短期记忆(LSTM)模型,一种递归神经网络(RNN)架构,该架构通常应用于涉及对数据进行分类或处理以及进行预测的任务。
两位研究人员Wilmot Li和Deepali Aneja介绍说:“由于语音几乎是每个实时动画的主要组成部分,因此我们认为在这一领域要解决的最关键的问题是实时口型同步,这需要将演员的语音转换为动画角色中相应的嘴部动作(即视位序列)。在这项工作中,我们专注于为实时2D动画创建高质量的口型同步。”
Li和Aneja开发的系统使用简单的LSTM模型,以每秒24帧的速度将流音频输入转换为相应的视位音素序列,延迟小于200毫秒。换句话说,他们的系统允许动画人物的嘴唇以与实时说话的人类用户相似的方式移动,语音和嘴唇移动之间的延迟小于200毫秒。 Li和Aneja说:“在这项工作中,我们做出了两点贡献:识别适当的特征表示和网络配置,以实现实时2D唇形同步的最新结果,并设计出一种新的增强方法来收集模型的训练数据。对于手工创作的口型同步,专业的动画制作人员会对视位的具体选择以及过渡的时间和数量做出风格上的决定。因此,训练一个'通用'模型对于大多数应用来说是不够的。”
Li和Aneja说:“在这项工作中,我们做出了两点贡献:识别适当的特征表示和网络配置,以实现实时2D唇形同步的最新结果,并设计出一种新的增强方法来收集模型的训练数据。对于手工创作的口型同步,专业的动画制作人员会对视位的具体选择以及过渡的时间和数量做出风格上的决定。因此,训练一个'通用'模型对于大多数应用来说是不够的。”
此外,获得标记的口型同步数据以训练深度学习模型可能既昂贵又耗时。专业动画制作人员每分钟的演讲时间可花五到七个小时来手工制作视位序列。意识到这些限制,Li和Aneja开发了一种可以更快,更有效地生成训练数据的方法。
为了更有效地训练他们的LSTM模型,Li和Aneja引入了一项新技术,即使用音频时间扭曲来增强手工编写的训练数据。即使在较小的标记数据集上训练其模型时,此数据增强过程也能实现良好的口型同步。
为了评估他们的互动系统实时产生口型同步的有效性,研究人员要求人类观众对使用他们的模型和使用商业二维动画工具制作的实时动画的质量进行评估。他们发现,与其他技术相比,大多数观看者更喜欢他们的方法产生的口型同步。
有趣的是,研究人员发现,他们的LSTM模型可以根据训练的数据获得不同的口型同步样式,同时还可以在广泛的演讲者中广泛推广。该模型取得了令人鼓舞的结果,令他们印象深刻,Adobe决定将其版本集成到2018年秋季发布的Adobe Character Animator软件中。
研究人员认为,应用现代机器学习技术来改善二维动画工作流程的机会更多。Li和Aneja表示:“到目前为止,一个挑战是缺乏训练数据,这很昂贵。但是,正如我们在这项工作中所表明的那样,可能存在利用结构化数据和自动编辑算法(例如动态时间扭曲)来最大化利用的方法。手工制作的动画数据的实用性。”
尽管研究人员提出的数据增强策略可以大大减少设计用于产生实时口型同步的模型的训练数据需求,但是手动动画足够的口型同步内容以训练新模型仍然需要大量的工作和精力。然而,根据Li和Aneja的说法,可能不需要为每种新的口型同步样式重新训练整个模型。





























