











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






深度森林新探索,应用于多标签学习
2019年11月20日 由 TGS 发表
686141
0
 南京大学周志华教授团队提出的“深度森林”算法曾在人工智能学术界和工业界受到广泛关注,并已在大型互联网金融企业实施。
南京大学周志华教授团队提出的“深度森林”算法曾在人工智能学术界和工业界受到广泛关注,并已在大型互联网金融企业实施。该类技术是一种基于不可微分单元(即树/树集成)的方法,具备适合多核芯片架构加速等特点,并且能够比基于神经网络的感知器更好地处理离散数据或列表数据,利用如英特尔至强可扩展处理器这样的核心架构设备可以达到最大程度的优化。
近日,南京大学周志华团队最新研究首次将深度森林引入到多标签学习中,提出了多标签深度森林方法MLDF。
非神经网络模型——深度森林
 第三波人工智能浪潮兴起之后,深度学习技术大火,深度神经网络模型成为产业界和学界追捧的对象。但目前的深度神经网络也有诸多缺陷,比如太多超参数、需要大量训练数据、理论分析难、黑箱模型,以及模型一旦选定复杂度即确定,通常远大于任务“所需”复杂度等等问题。“深度森林”是人工智能领域的一大创新,为人工智能算法打开了一扇新的大门,它并不是要替代深度学习,因为它本身就是一种深度学习,是首个不使用BP算法来训练的深度学习模型。
第三波人工智能浪潮兴起之后,深度学习技术大火,深度神经网络模型成为产业界和学界追捧的对象。但目前的深度神经网络也有诸多缺陷,比如太多超参数、需要大量训练数据、理论分析难、黑箱模型,以及模型一旦选定复杂度即确定,通常远大于任务“所需”复杂度等等问题。“深度森林”是人工智能领域的一大创新,为人工智能算法打开了一扇新的大门,它并不是要替代深度学习,因为它本身就是一种深度学习,是首个不使用BP算法来训练的深度学习模型。从应用价值的角度讲,在图像、视频、语音之外的很多任务上深度神经网络往往并非最佳选择,不少时候甚至表现不佳,比如符号建模、混合建模、离散建模等问题上。“深度森林”在这些任务上可能有更好的表现,目前,深度森林模型已经有大型企业应用并取得了很好的效果。所以,它不仅仅只具有学术价值,还有实用价值。
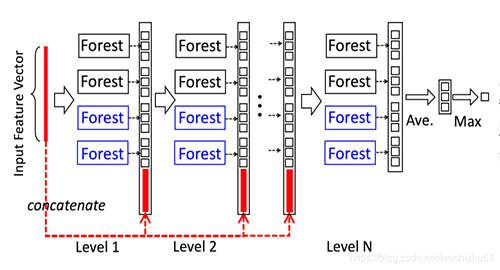 深度森林采用多层级结构,每层由四个随机森林组成,两个随机森林和两个极端森林,每个极端森林包含1000个完全随机树,每个森林都会对的数据进行训练,每个森林都输出结果,这个结果叫做森林生成的类向量。为了避免过拟合,喂给每个森林训练的数据都是通过k折交叉验证的,每一层最后生成四个类向量,下一层以上一层的四个类向量,以及原有的数据为新的train data进行训练,如此反复叠加,最后一层将类向量进行平均,得出预测结果。
深度森林采用多层级结构,每层由四个随机森林组成,两个随机森林和两个极端森林,每个极端森林包含1000个完全随机树,每个森林都会对的数据进行训练,每个森林都输出结果,这个结果叫做森林生成的类向量。为了避免过拟合,喂给每个森林训练的数据都是通过k折交叉验证的,每一层最后生成四个类向量,下一层以上一层的四个类向量,以及原有的数据为新的train data进行训练,如此反复叠加,最后一层将类向量进行平均,得出预测结果。通过对比不难发现,这种结构非常类似于神经网络,神经网络的每个单位是神经元,而深度森林的单位元却是随机森林,单个随机森林在性能上强于单个神经元的,这就是使得深度森林很多时候尽管层级和基础森林树不多,也能取得好的结果的主要原因。
然而从根本上来说,深度森林是完全有别于神经网络的,这就使它具备了全新的可能,拓展了深度学习的体系。
新探索——用于多标签学习
 最近,周志华教授团队拓展了深度森林的应用范围,将深度森林方法用于多标签学习,这是一次全新的大胆尝试。
最近,周志华教授团队拓展了深度森林的应用范围,将深度森林方法用于多标签学习,这是一次全新的大胆尝试。在多标签学习中,每个实例都与多个标签相关联,而关键的任务是如何在构建模型中利用标签相关性。深度神经网络方法通常将特征信息和标签信息一起嵌入到一个潜在空间中以利用标签的相关性。然而,这些方法的成功在很大程度上取决于对模型深度的精确选择。
深度森林则不同,它不依赖于反向传播。可能就是根据这种不同的特性,周志华团队认为深度森林模型的优点非常适合解决多标签问题,并用两种机制设计了多标签深度森林方法:
1、度量感知特性重用;2、度量感知层增长。
 在多标签学习中,每个实例都同时与多个标签相关联,多标签学习的任务是为未见过的实例预测一组相关标签。因此被广泛应用于文本分类、场景分类、功能基因组学、视频分类、化学品分类等多种问题。在现实问题中几乎无所不在,吸引了越来越多的研究关注。
在多标签学习中,每个实例都同时与多个标签相关联,多标签学习的任务是为未见过的实例预测一组相关标签。因此被广泛应用于文本分类、场景分类、功能基因组学、视频分类、化学品分类等多种问题。在现实问题中几乎无所不在,吸引了越来越多的研究关注。深度森林是建立在决策树之上的集成深度模型,在训练过程中不使用反向传播。具有级联结构的深度森林集成系统能够像深度神经模型一样进行表示学习。它更容易训练,因为它的超参数更少。
由于多标签学习中的评估比传统的分类任务更复杂,因此有多种性能度量方法。新方法MLDF能通过不同的多标签树方法创建深度森林的构建块,并通过逐层表示学习来利用标签相关性,首次将深度森林引入到多标签学习中,解决了两个具有挑战性的问题:根据用户需求优化不同的性能指标;在利用大量层的特征相关性时减少过拟合。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消