











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用深度学习预测Phish乐队接下来唱什么歌(下)
2019年12月01日 由 sunlei 发表
299356
0
下面我们继续做一个小实验:
关于昨天的内容请点击传送门《用深度学习预测Phish乐队接下来唱什么歌》(上)
在锁定模型组件的情况下,我通过对以下超参数的各种设置进行网格搜索来实现广域网:
[caption id="attachment_47448" align="aligncenter" width="1598"]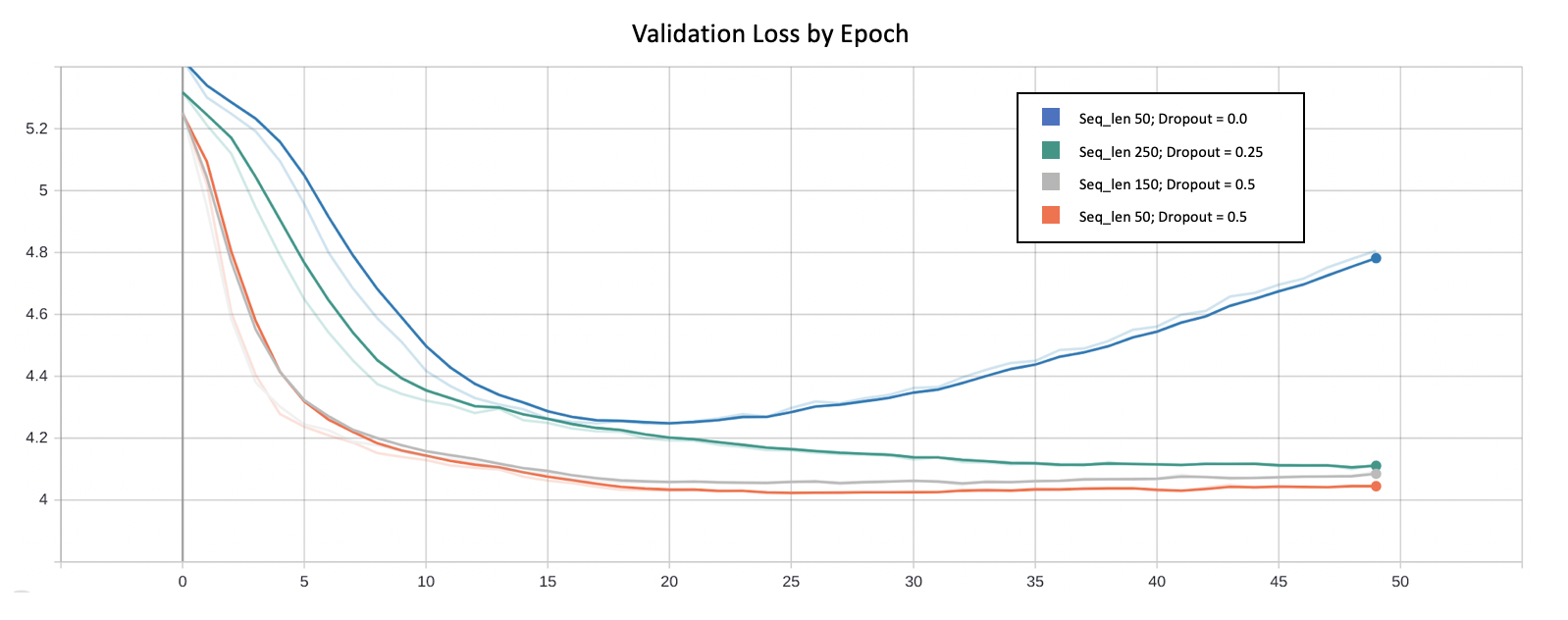 四个经过训练的模型的验证损失与历元(其他约100个经过训练的模型为可解释性而被隐藏)[/caption]
四个经过训练的模型的验证损失与历元(其他约100个经过训练的模型为可解释性而被隐藏)[/caption]
有了这些知识,我开始了解嵌入表示对我的模型的影响,并查看是否有改进的空间。我首先将嵌入向量的大小从固定长度50切换到100、150、200和250。很明显,较大的嵌入尺寸对整体分类精度(约21%)有轻微的改善,因为它允许模型为每首歌学习更多细微的特征。
这些学习过的嵌入实际上代表什么?
为了更好地理解模型所学习的内容,我提取了嵌入项,执行了主成分分析(PCA),将它们折叠成3维,并在3D中绘制它们。
[caption id="attachment_47450" align="aligncenter" width="640"]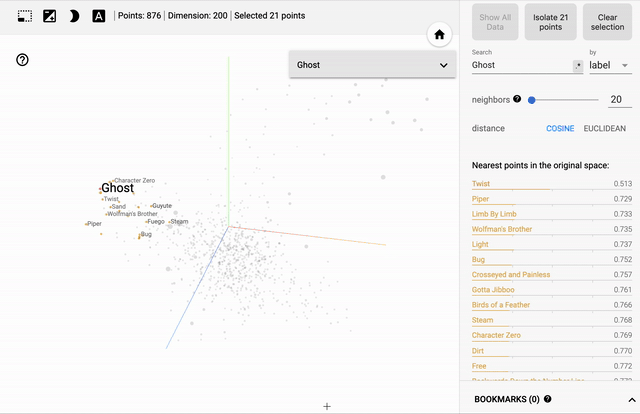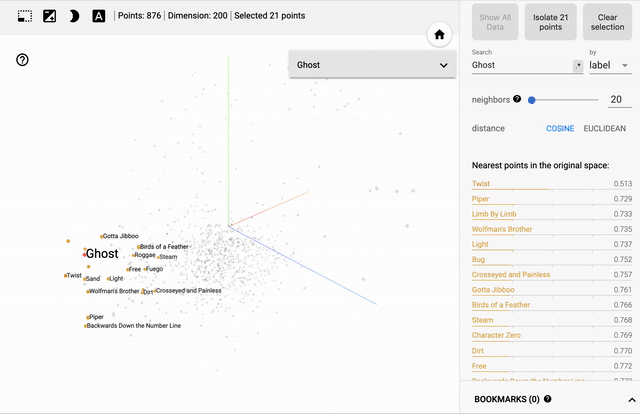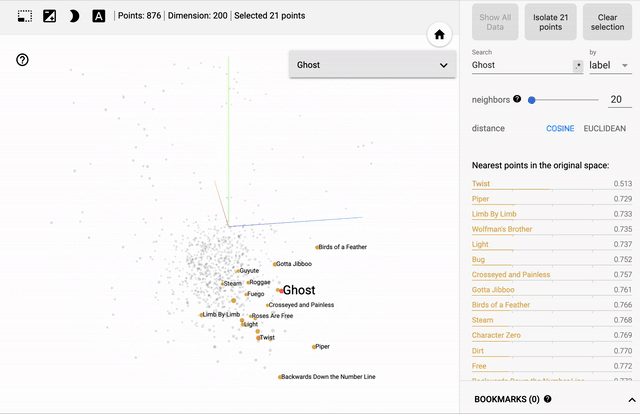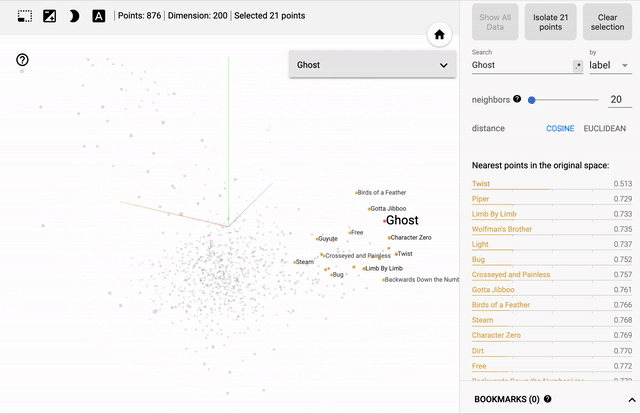 歌曲嵌入的主要组件的三维可视化-与“幽灵”相似的歌曲以黄色突出显示[/caption]
歌曲嵌入的主要组件的三维可视化-与“幽灵”相似的歌曲以黄色突出显示[/caption]
正如预期的那样,该模型已经学会了将出现在类似环境中的歌曲联系起来。上面的图像显示了20首与《Ghost》最相似的歌曲——Phish的粉丝们可以在这里找到明显的联系。注意它们在主元分析向量空间中出现的距离有多近……
看到这些学习向量确实有改进的空间,我通过分别创建自己的歌曲嵌入扩展了这个想法。通过训练一个名为CBOW(连续的单词包)的Word2Vec算法,我创建了包含双向上下文和神经网络仅向前上下文的向量。使用这些经过改进的歌曲向量之间的余弦相似性可以揭示一些非常有趣的模式。
[caption id="attachment_47451" align="aligncenter" width="1882"]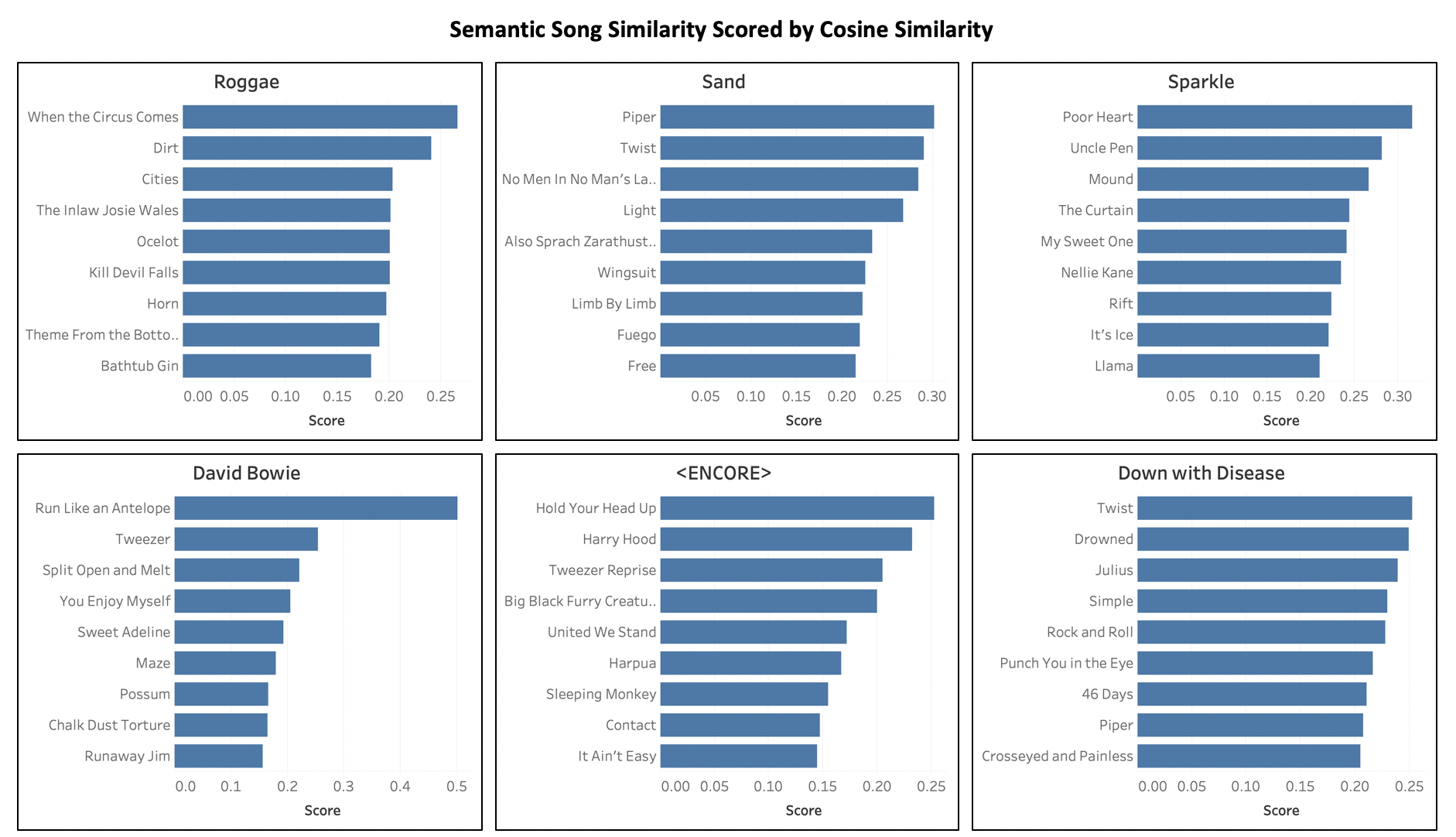 六首最相似的歌曲(按降序余弦相似性排序)[/caption]
六首最相似的歌曲(按降序余弦相似性排序)[/caption]
上面的图像显示了一首给定的歌曲以及它的9首最相似的歌曲,这些歌曲都是通过Word2Vec模型学习到的。在这个意义上,相似意味着歌曲出现在相同的背景或在一个固定列表的位置。对于熟悉这些歌曲的Phan来说,你会立刻认同:
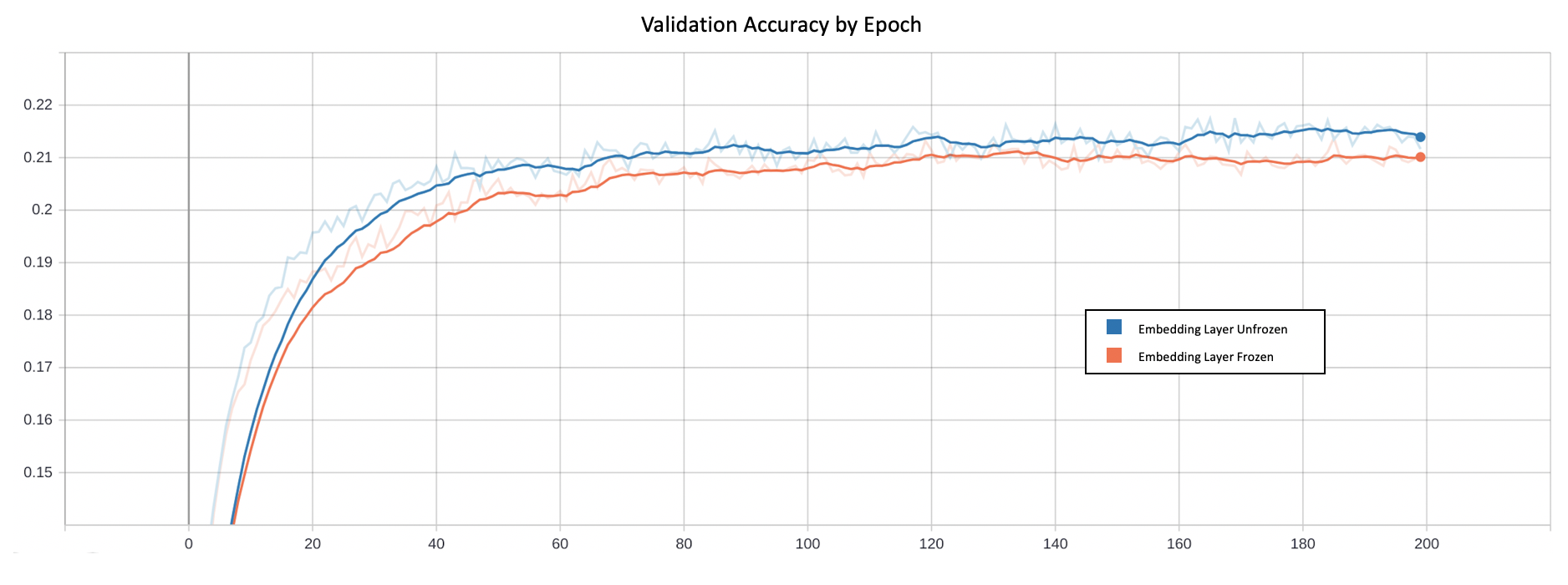
在转移学习的尝试中,我使用这些上下文丰富的嵌入作为我的神经网络嵌入层的初始化参数(而不是随机的)。该网络在嵌入层冻结和未冻结的情况下都进行了训练;后者证明更有效,使我可以将精度略微提高到21.8%。
21.8%的准确度有多好?
好吧,首先,这比随机的机会要好得多。一个统计模型能够理解和解释这些微妙的关系,这是相当惊人的,特别是考虑到它不知道这些歌曲实际上是什么样的。然而,现实情况是,这个模型(就像我们人类一样)非常擅长学习以一些特定模式出现的歌曲,而其他模式则相当糟糕。这些特定的模式发生在歌曲出现时:
[caption id="attachment_47453" align="aligncenter" width="1400"]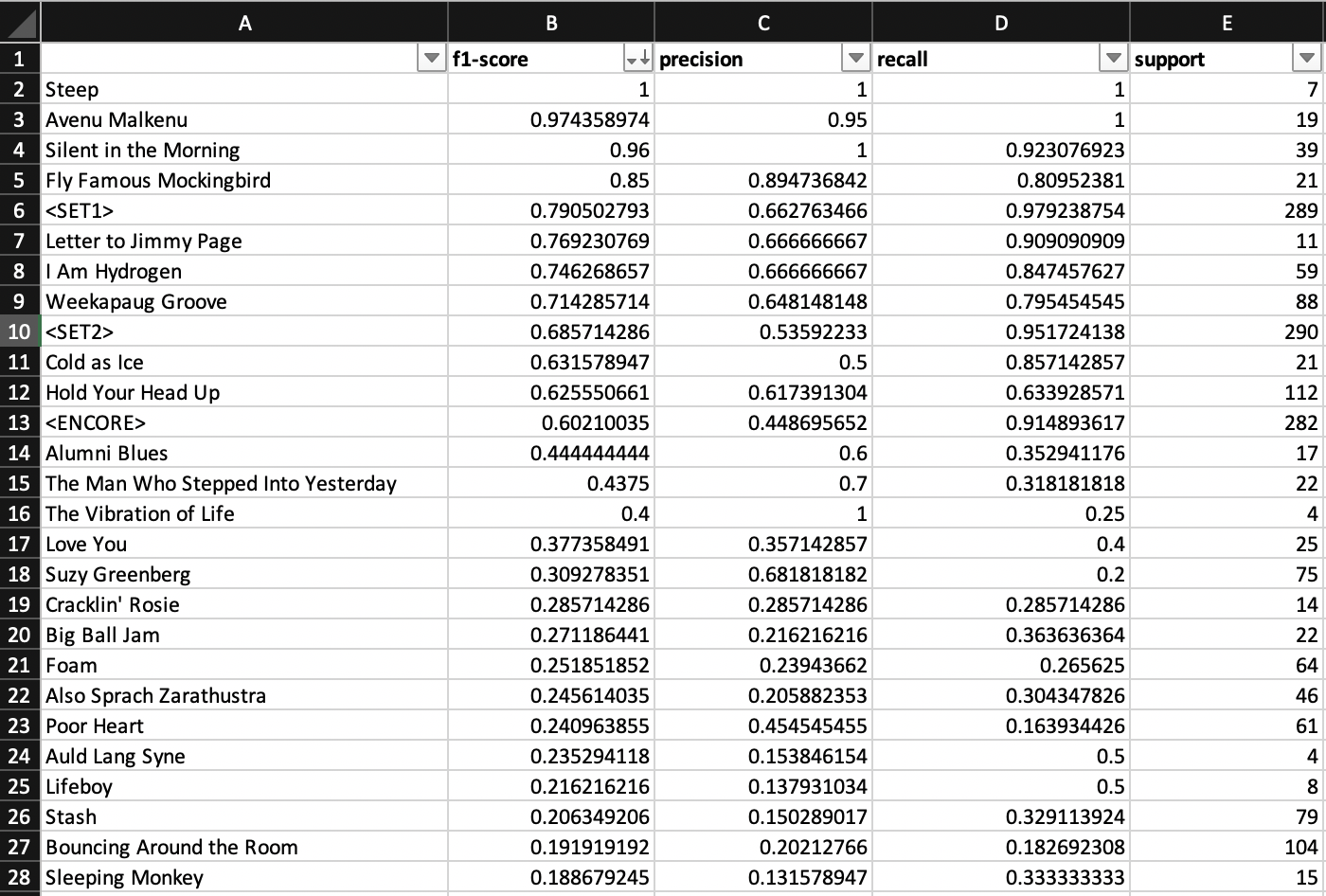 模型表现最好的歌曲(按F1评分排序)[/caption]
模型表现最好的歌曲(按F1评分排序)[/caption]
这种建模方法的一个大问题是它只关注顺序数据……这意味着它没有关于Phish的分类和抽象知识的概念。例如,该模型无法识别[较新的]3.0歌曲是什么,因此,无法理解这些歌曲现在比[较旧/较少见的]1.0歌曲更有可能播放。一个巨大的改进是将分类数据(年代、地点、年份、专辑等)与集合列表序列一起合并到神经网络中。
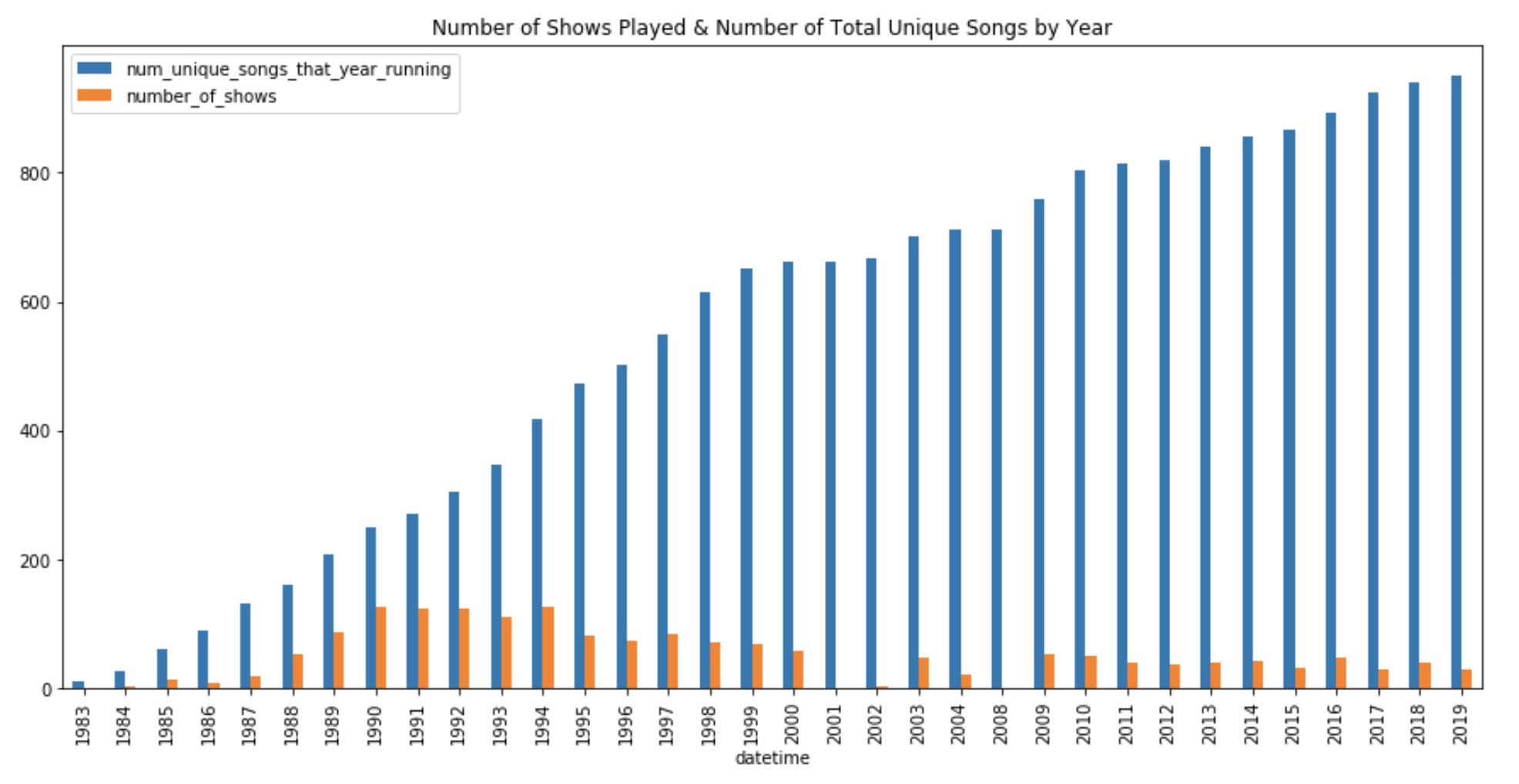
另一种改进方法(或至少改进相关性)可以是排除前10-15年的数据。如下图所示,Phish在90年代早期播放了大部分节目(1994年有128个节目!)当他们播放的独特歌曲相对较少时(今天超过850首歌曲中约375首),这意味着我们的大多数训练数据严重倾斜,无法学习与这375首歌曲相关的模式(在Phish 1.0期间)。一个很好的例子是" Cold as Ice " > " Cracklin Rosie " > " Cold as Ice ";在1992-1995年期间,它被演出了46次,之后只演出了4次。
 让事情变得更复杂的是,Phish经常演出一些歌曲,而这些歌曲现在很少出现了。更不用说,从Phish 1.0开始出现的新歌(而且还在继续出现)整体上播放频率更低,因此可以学习的模式也更少。因此,这是一个很难建模的问题。
让事情变得更复杂的是,Phish经常演出一些歌曲,而这些歌曲现在很少出现了。更不用说,从Phish 1.0开始出现的新歌(而且还在继续出现)整体上播放频率更低,因此可以学习的模式也更少。因此,这是一个很难建模的问题。
使用新训练的神经网络[巧妙地命名为TrAI],我们可以递归地进行预测,以根据最近播放的50首歌曲的输入生成Phish的下一个设置列表。在没有进一步告别的情况下,以下是TrAI对2019年11月29日在里约热内卢普罗维登斯举行的秋季巡回赛开幕式的预测:
[caption id="attachment_47455" align="aligncenter" width="2154"] TrAI预计将于2019年11月29日在佛罗里达州普罗维登斯举行下一场演出[/caption]
TrAI预计将于2019年11月29日在佛罗里达州普罗维登斯举行下一场演出[/caption]
这个项目使用的工具有:Python、Keras、Tensorflow、Gensim、Jupyter、Anaconda、Tableau和Tensorboard。所有支持代码都可以在我的Github repo中找到。
原文链接:https://towardsdatascience.com/predicting-what-song-phish-will-play-next-with-deep-learning-947ccce3824d
关于昨天的内容请点击传送门《用深度学习预测Phish乐队接下来唱什么歌》(上)
实验
迭代1-“撒网”
在锁定模型组件的情况下,我通过对以下超参数的各种设置进行网格搜索来实现广域网:
- 体系结构:一个LSTM层与两个LSTM层
- 序列长度:模型需要多长序列才能正确地知道接下来会出现什么歌曲?初始设置为25、50、100、150和250首歌曲。但请记住,这里的权衡是,序列越长,可用的训练示例数量就越少……
- LSTM单元的数量:我在50到100之间切换。
- LSTM前Dropout:0%-70%(增量)
- LSTM后Dropout:0%-70%(增量)
[caption id="attachment_47448" align="aligncenter" width="1598"]
四个经过训练的模型的验证损失与历元(其他约100个经过训练的模型为可解释性而被隐藏)[/caption]研究结果
- Dropout是至关重要的,但不是太重要。似乎50%的Dropout可以在不过度学习的情况下进行适当的学习。
- 正确的学习速度确实加快了收敛速度。
- 用更大的模型来解决这个问题并不一定有帮助。更多的参数(即层、LSTM单元)并不一定意味着学习的潜力更大,而且使模型更容易过度拟合。
- 输入序列长度为~50是该问题的理想建模方法。任何较短的模型都无法学习某些依赖项,任何较长的模型都会失去关注点,并强调学习不太重要的长期依赖项。
- 许多不同的超参数设置和模型大小似乎在相同的损失水平上趋同,相应的精度约为18%到20%。
迭代2-“嵌入深潜”
有了这些知识,我开始了解嵌入表示对我的模型的影响,并查看是否有改进的空间。我首先将嵌入向量的大小从固定长度50切换到100、150、200和250。很明显,较大的嵌入尺寸对整体分类精度(约21%)有轻微的改善,因为它允许模型为每首歌学习更多细微的特征。
解释
这些学习过的嵌入实际上代表什么?
为了更好地理解模型所学习的内容,我提取了嵌入项,执行了主成分分析(PCA),将它们折叠成3维,并在3D中绘制它们。
[caption id="attachment_47450" align="aligncenter" width="640"]
歌曲嵌入的主要组件的三维可视化-与“幽灵”相似的歌曲以黄色突出显示[/caption]正如预期的那样,该模型已经学会了将出现在类似环境中的歌曲联系起来。上面的图像显示了20首与《Ghost》最相似的歌曲——Phish的粉丝们可以在这里找到明显的联系。注意它们在主元分析向量空间中出现的距离有多近……
看到这些学习向量确实有改进的空间,我通过分别创建自己的歌曲嵌入扩展了这个想法。通过训练一个名为CBOW(连续的单词包)的Word2Vec算法,我创建了包含双向上下文和神经网络仅向前上下文的向量。使用这些经过改进的歌曲向量之间的余弦相似性可以揭示一些非常有趣的模式。
[caption id="attachment_47451" align="aligncenter" width="1882"]
六首最相似的歌曲(按降序余弦相似性排序)[/caption]上面的图像显示了一首给定的歌曲以及它的9首最相似的歌曲,这些歌曲都是通过Word2Vec模型学习到的。在这个意义上,相似意味着歌曲出现在相同的背景或在一个固定列表的位置。对于熟悉这些歌曲的Phan来说,你会立刻认同:
- 大卫·鲍伊(David Bowie)提到的乐观向上、精力充沛的“barn burners”
- 短,快节奏,蓝调小调像火花,作为连接更突出的歌曲
- 节奏较慢、旋律优美的乐曲与Roggae的节奏一致
- 老套而受欢迎的安可歌曲
在转移学习的尝试中,我使用这些上下文丰富的嵌入作为我的神经网络嵌入层的初始化参数(而不是随机的)。该网络在嵌入层冻结和未冻结的情况下都进行了训练;后者证明更有效,使我可以将精度略微提高到21.8%。
把一切都包起来
21.8%的准确度有多好?
好吧,首先,这比随机的机会要好得多。一个统计模型能够理解和解释这些微妙的关系,这是相当惊人的,特别是考虑到它不知道这些歌曲实际上是什么样的。然而,现实情况是,这个模型(就像我们人类一样)非常擅长学习以一些特定模式出现的歌曲,而其他模式则相当糟糕。这些特定的模式发生在歌曲出现时:
- 1、作为常见的segues, Phish有一些歌曲(几乎总是)同时出现,一个接一个。我们的模型在相当长的时间内都能正确地处理这些后续的歌曲。(例如“Mike的歌”>“I am Hydrogen”>“Weekapaug Groove”或“The Horse”>“Silent in The Morning”或“Away”> “Steep”)
- 2、作为开场曲
- 3、作为安可曲
- 4、当你猜到是时候休息一下了
[caption id="attachment_47453" align="aligncenter" width="1400"]
模型表现最好的歌曲(按F1评分排序)[/caption]改进空间
这种建模方法的一个大问题是它只关注顺序数据……这意味着它没有关于Phish的分类和抽象知识的概念。例如,该模型无法识别[较新的]3.0歌曲是什么,因此,无法理解这些歌曲现在比[较旧/较少见的]1.0歌曲更有可能播放。一个巨大的改进是将分类数据(年代、地点、年份、专辑等)与集合列表序列一起合并到神经网络中。
另一种改进方法(或至少改进相关性)可以是排除前10-15年的数据。如下图所示,Phish在90年代早期播放了大部分节目(1994年有128个节目!)当他们播放的独特歌曲相对较少时(今天超过850首歌曲中约375首),这意味着我们的大多数训练数据严重倾斜,无法学习与这375首歌曲相关的模式(在Phish 1.0期间)。一个很好的例子是" Cold as Ice " > " Cracklin Rosie " > " Cold as Ice ";在1992-1995年期间,它被演出了46次,之后只演出了4次。
让事情变得更复杂的是,Phish经常演出一些歌曲,而这些歌曲现在很少出现了。更不用说,从Phish 1.0开始出现的新歌(而且还在继续出现)整体上播放频率更低,因此可以学习的模式也更少。因此,这是一个很难建模的问题。设置列表生成
使用新训练的神经网络[巧妙地命名为TrAI],我们可以递归地进行预测,以根据最近播放的50首歌曲的输入生成Phish的下一个设置列表。在没有进一步告别的情况下,以下是TrAI对2019年11月29日在里约热内卢普罗维登斯举行的秋季巡回赛开幕式的预测:
[caption id="attachment_47455" align="aligncenter" width="2154"]
TrAI预计将于2019年11月29日在佛罗里达州普罗维登斯举行下一场演出[/caption]这个项目使用的工具有:Python、Keras、Tensorflow、Gensim、Jupyter、Anaconda、Tableau和Tensorboard。所有支持代码都可以在我的Github repo中找到。
原文链接:https://towardsdatascience.com/predicting-what-song-phish-will-play-next-with-deep-learning-947ccce3824d

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
如何处理缺失值








广告


写评论取消
回复取消