DeepMind最新AI程序使记忆内存化
2019年12月03日 由 KING 发表
904468
0
DeepMind科学家构建了一种计算机程序,该计算机程序以一种理论模型来提供从未来到过去的信号,就像人们从错误中吸取教训一样。例如不小心碰掉了桌子边缘的玻璃杯。你可能在把它放在桌子边缘的时候就意识到它会摔碎,但是只有摔碎之后你才会感到后悔。 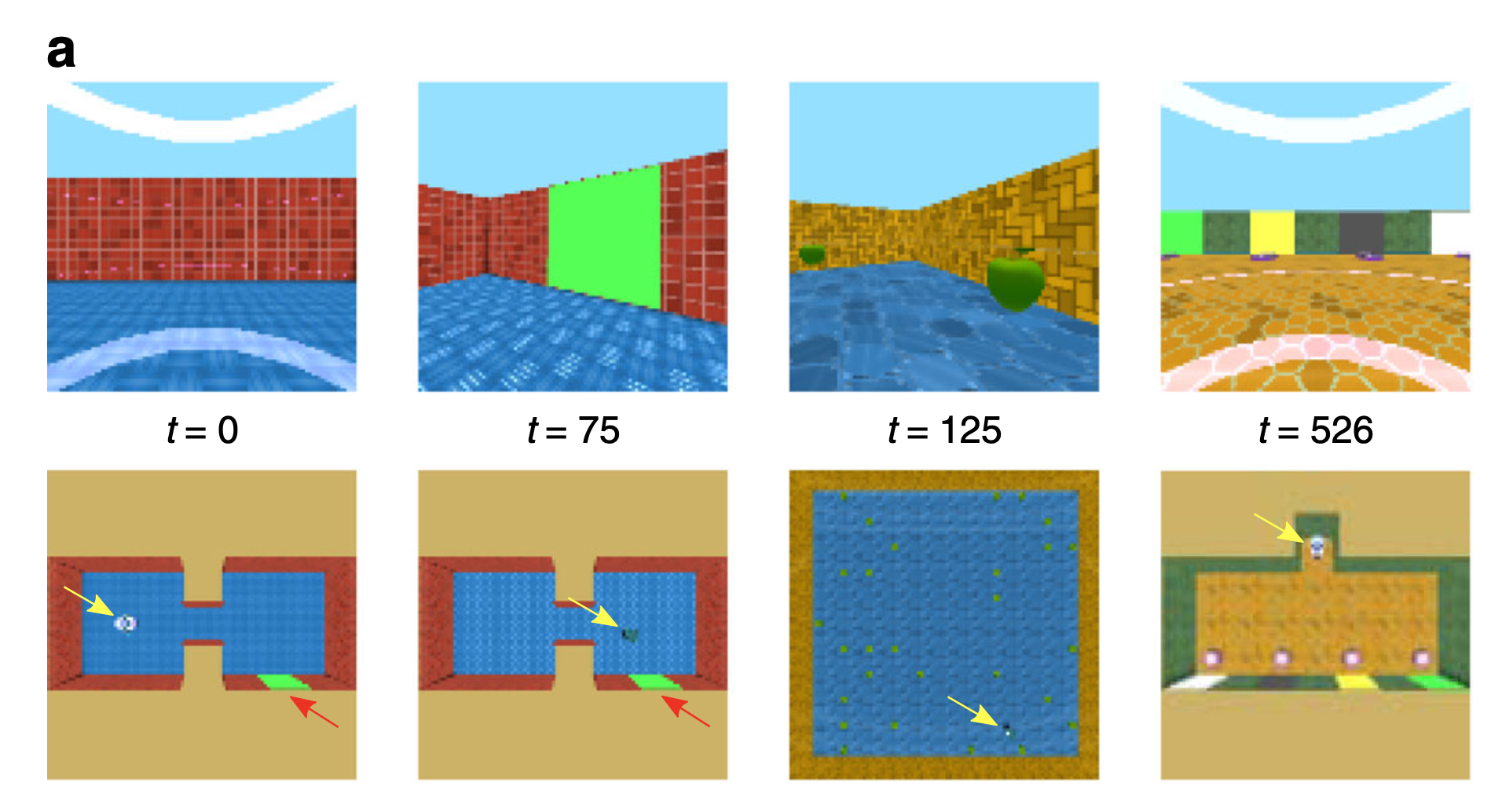 后悔心理是如何产生的这是Google DeepMind部门近期工作的主题。DeepMind的解决方案是一种深度学习程序,它们称为“时间价值传递”。简而言之,它是一种将未来的教训回传给过去(如果你愿意的话)的方法,它可以告知行动。从某种意义上说,这是在使行动和结果游戏化。
后悔心理是如何产生的这是Google DeepMind部门近期工作的主题。DeepMind的解决方案是一种深度学习程序,它们称为“时间价值传递”。简而言之,它是一种将未来的教训回传给过去(如果你愿意的话)的方法,它可以告知行动。从某种意义上说,这是在使行动和结果游戏化。
他们本身并没有创造记忆,也没有重建脑海中发生的事情。相反,正如他们所说的那样,他们“提供了一种可以激发神经科学,心理学和行为经济学模型的行为的机械描述”。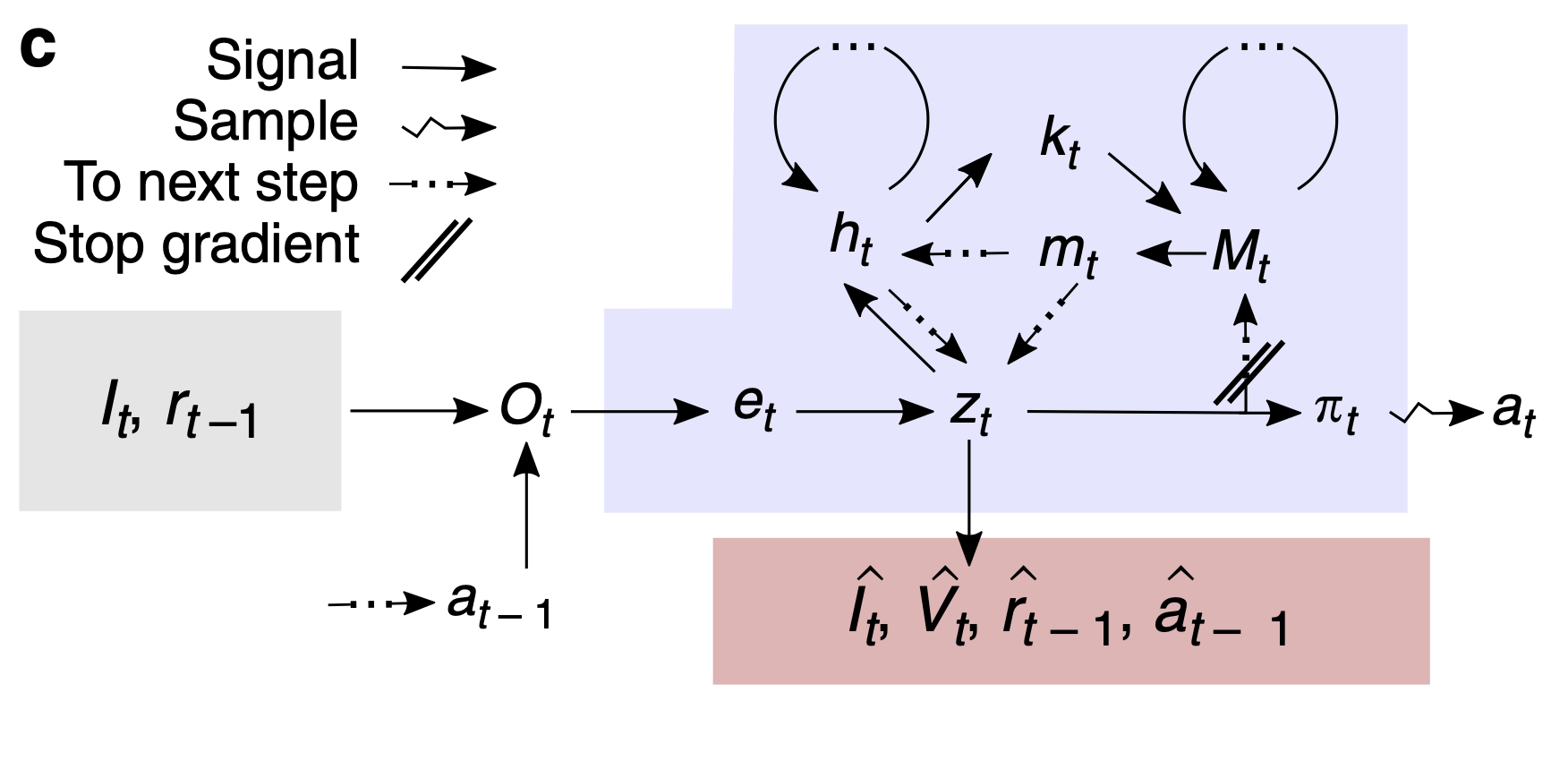 在这项工作中,研究人员改编了RL,以便它可以接收来自未来很远的信号,它使用这些信号在渠道开始时塑造动作,这是一种反馈回路。 换句话说,他们做了一个游戏。他们创造了一个模拟世界,模拟与现实进行交互。例如遇到彩色方块,以后有许多序列,如果模拟可以使用充当记忆的较早探索记录找到通往现实的方式,则将获得奖励。
在这项工作中,研究人员改编了RL,以便它可以接收来自未来很远的信号,它使用这些信号在渠道开始时塑造动作,这是一种反馈回路。 换句话说,他们做了一个游戏。他们创造了一个模拟世界,模拟与现实进行交互。例如遇到彩色方块,以后有许多序列,如果模拟可以使用充当记忆的较早探索记录找到通往现实的方式,则将获得奖励。
他们是如何做到这一点的呢?其实是Alex Graves及其同事利用了在2014年DeepMind上创建的一种有趣的改编作品,称为“神经图灵机”(NMT)。NMT是一种使计算机搜索内存寄存器不依靠显式指令而是仅依靠深度学习网络中的梯度下降的方法。(换句话说,了解存储和检索特定数据的功能)
他们现在采用了NMT的方法,并且在某种意义上将其固定在普通RL上。诸如AlphaZero之类的RL搜索一个潜在的奖励空间,以通过梯度下降“学习”一个价值函数,即所谓的最大回报系统。然后,价值函数会通知策略的构建,该策略指导计算机在游戏状态中进行时所采取的动作。 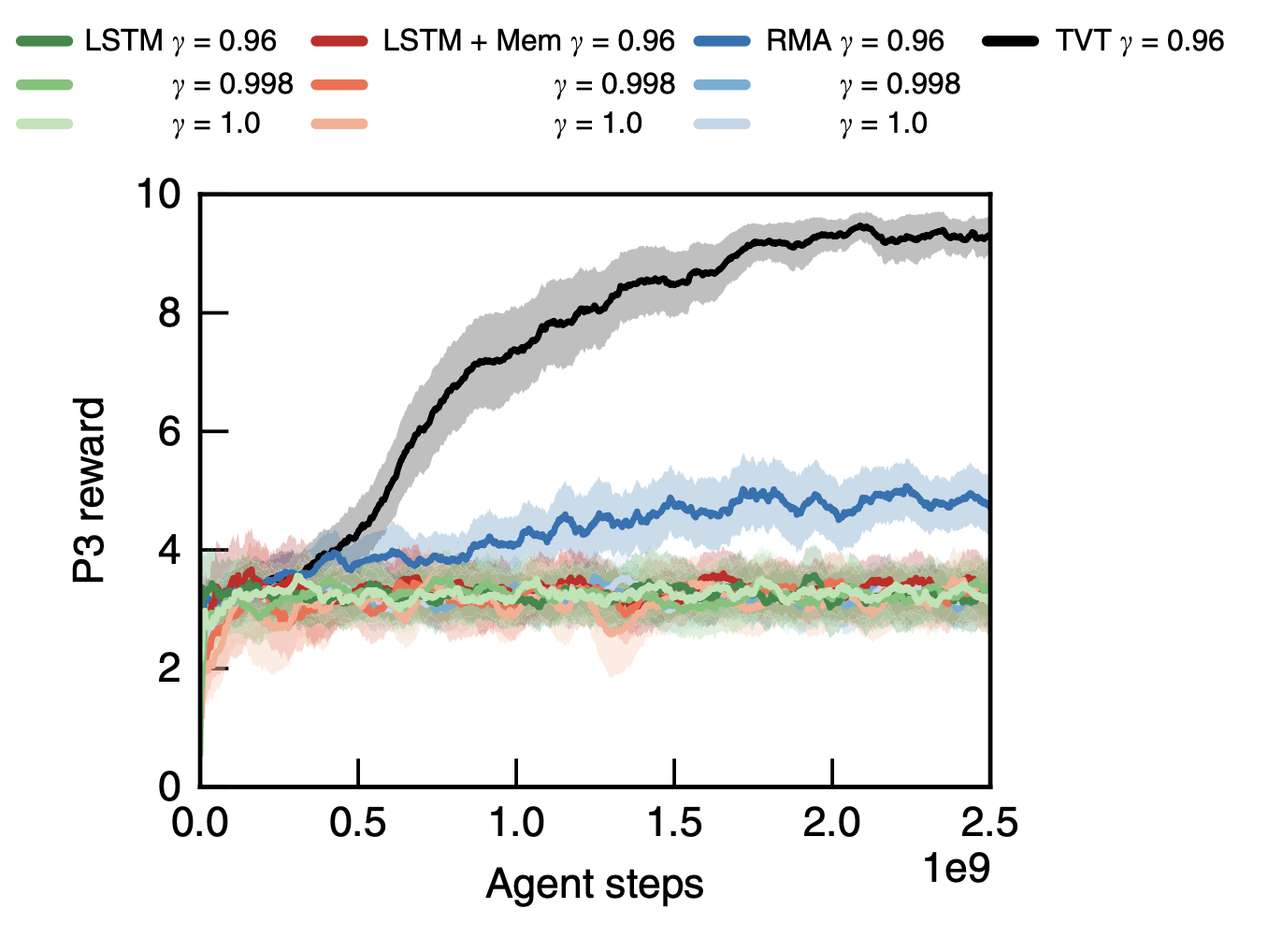 为此,研究增加了RL程序检索记忆的能力,这些记忆是过去动作的记录,例如先前遇到彩色方块的记录。他们称其为“重构内存代理”。所谓的RMA利用NMT功能通过梯度下降来存储和检索内存。顺便说一句,他们在这里开辟了新天地。他们写道,虽然其他方法试图使用内存访问来帮助RL,但这是第一次“对过去事件的所谓内存”进行“编码”。他们指的是在生成的神经网络中编码信息的方式,例如“变分自动编码器”,这是一种深度学习的通用方法,它是诸如OpenAI构建的“ GPT2”语言模型之类的基础。
为此,研究增加了RL程序检索记忆的能力,这些记忆是过去动作的记录,例如先前遇到彩色方块的记录。他们称其为“重构内存代理”。所谓的RMA利用NMT功能通过梯度下降来存储和检索内存。顺便说一句,他们在这里开辟了新天地。他们写道,虽然其他方法试图使用内存访问来帮助RL,但这是第一次“对过去事件的所谓内存”进行“编码”。他们指的是在生成的神经网络中编码信息的方式,例如“变分自动编码器”,这是一种深度学习的通用方法,它是诸如OpenAI构建的“ GPT2”语言模型之类的基础。
当一项任务确实带来了未来的回报时,TVT神经网络会向过去的行为发送信号,如果愿意的话,还可以决定如何改善这些行为。这样,典型的RL值函数就可以根据动作及其未来效用之间的长期依赖关系进行训练。
他们的结果表明,他们击败了基于“长期-短期记忆”或LSTM网络的典型RL方法。意思是,RMA和TVT的DeepMind组合击败了LTSM,甚至那些利用内存存储的LSTM。
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2019/12/Modeling-Expectation-Violation-in-Intuitive-Physics-with-Coarse-Probabilistic-Object-Representations-1.mp4"][/video]
重要的是要记住,这全都是游戏,而不是人类记忆的模型。在游戏中,DeepMind的RL代理运行在违抗物理的系统中,在该系统中,将来获得奖励的事件会向过去发出信号,以改善或“引导”先前采取的行动。
研究人员表示:“关于我们如何解决问题并在很长一段时间内表达连贯行为的完整解释仍然是一个深奥的谜,我们的工作仅能提供深刻的见解。”然而,他们确实相信,他们的工作可能有助于探索潜在的机制:“我们希望,一种认知机制方法来理解跨时选择(将选择偏好与刚性贴现模型脱钩)将启发前进的道路。”





























