











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






股市预测初步实践与体会
2019年12月08日 由 sunlei 发表
504446
0
[caption id="attachment_47767" align="aligncenter" width="400"] 图像来自 Pexels[/caption]
图像来自 Pexels[/caption]
当你开始你的第一个基本回归或分类模型的时候,它至少会在你的脑海里闪现。海量的时间序列数据,再加上让你提前退休的可能性,都有一种不可抗拒的吸引力,就像让你在祖父的阁楼里找到一张旧藏宝图。你怎么能不去努力呢?你能用机器学习来预测股票市场吗?
我至少得试一试。这就是我所做的,也是我所学到的。
网上有很多小范围的教程,是一个很好的起点。它们向您展示了如何提取股票的历史数据,可能还会计算一些指标,并将其输入回归算法,并尝试预测第二天的股价。或者,他们使用一个分类器来预测股票是上涨还是下跌,而不预测一个值。
关于今后的发展方向,我有两个想法。首先,我想做大一点。我的理论是,某些股票、货币和金融指标之间可能隐藏着微妙的关系,肉眼很难发现。我想一个机器学习算法也许能找出它们的关系。
其次,我不会选择我想预测的股票。我打算为他们所有人训练模型,看看哪些股票表现最好。我的想法是,有些公司可能比其他公司更容易预测,所以我需要找到它们。
我首先下载了标准普尔500指数中大多数股票的历史数据,一堆货币价值历史数据,以及几十个财务指标。一个Python脚本负责将它们转换成一致的格式,填充丢失的值,并删除至少不能追溯到2000年初的时间序列。总之,当尘埃散去时,我在一个漂亮的Pandas表中有超过1000列,其中有18年的数据。
完成后,我使用优秀的TA-lib库为5、10和30天的窗口计算每个时间序列的一系列指标。我没有金融背景,也不知道哪些会真正增加价值,所以我采取的方法是把它们加起来,让模型对它们进行分类。这使得列数激增。数据集已经准备好输入超过32000列的训练模型。
我之所以选择XGBoost作为我的算法,是因为它具有整体性能,并且能够方便地查看模型使用哪些特性进行预测。我将其设置为遍历数据集中的所有股票,并为每个股票训练两个模型。第一个是分类器,它可以预测第二天股票的涨跌。第二种是回归模型,预测第二天的收盘价。
对于每个模型,我都将它训练在95%的可用数据上,然后使用剩下的数据进行验证测试,以模拟它从未见过的股票数据。剩下的5%是大约3个月的交易数据。任何机器学习模型都能很好地预测它所训练的数据——关键是要让它更通用,并在它从未接触过的数据上表现良好。
对于验证运行,启动时进行了1000美元的模拟投资。如果预测该股会上涨,它就会买进;如果预测该股会下跌,它就会卖出。他们没有考虑交易成本,因为我想看看如果不考虑交易成本,结果会怎样。
我把Jetson TX2开了一个月。
正如预期的那样,对于大多数股票来说,结果都很糟糕——准确性并不比抛硬币好多少。不过,有一些似乎在验证数据上表现得特别好。有好几家公司在3到6个月的时间里把我的模拟资金翻了两倍甚至三倍,还有几家公司在那段时间里获得了20倍的利润。结果显示,一个图表可以让你的心率飙升。
请记住,这是算法之前从未见过的数据——最后的5%被保留在训练数据集之外。
[caption id="attachment_47768" align="aligncenter" width="2000"]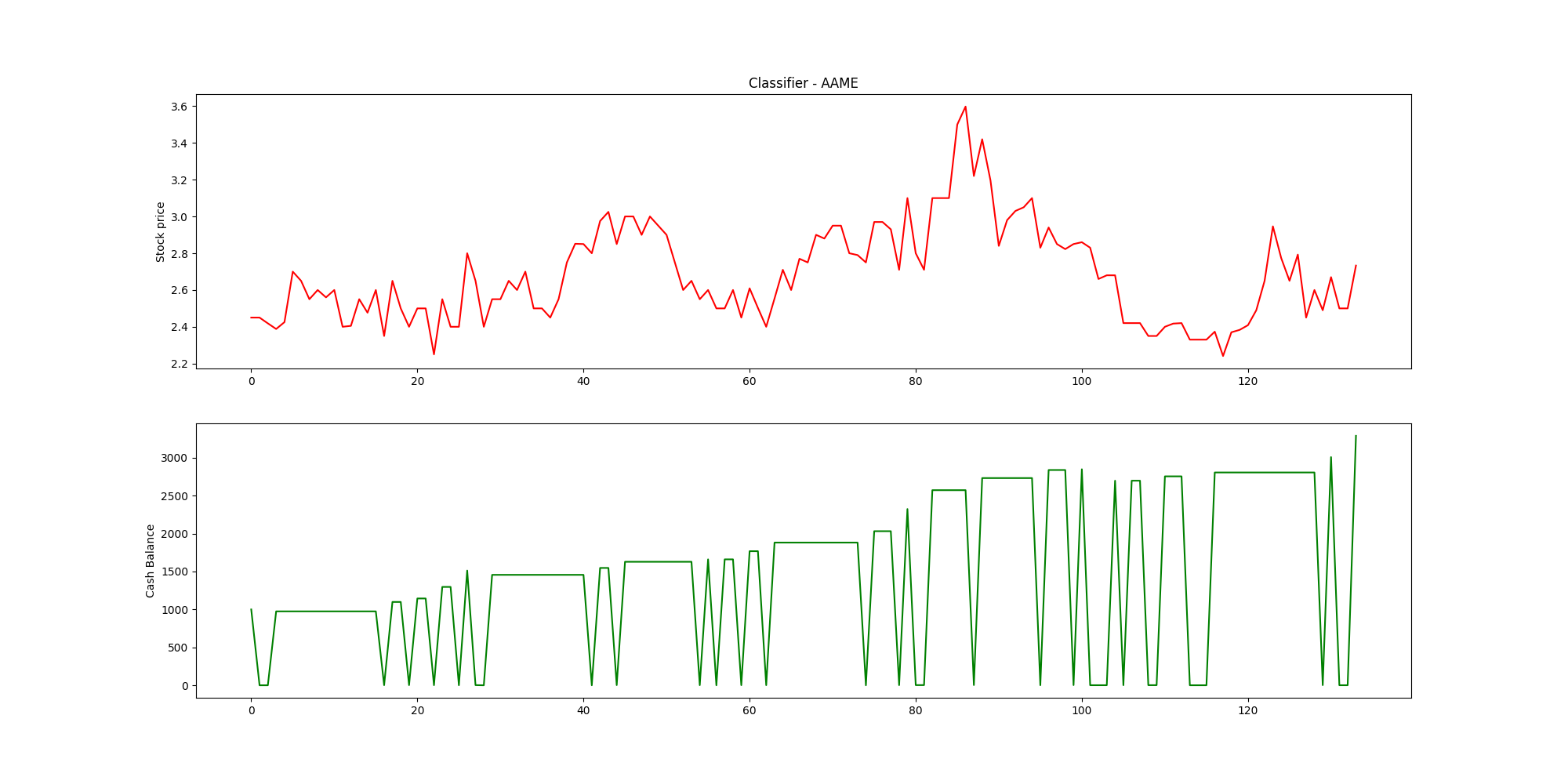 顶部是股票收盘价,底部是现金。跌到接近零是买入。[/caption]
顶部是股票收盘价,底部是现金。跌到接近零是买入。[/caption]
我找到了吗?是否有一些股票与市场指标微妙地联系在一起,从而可以预测?如果是这样,我可以从价格的波动中赚钱。
当我写完代码并运行它时,距离我下载巨大的数据集已经过去了几个月。我对它进行了更新,包括了最新的交易数据,并决定看看模型在这段时间内会做些什么。他们的验证运行做得很好——如果我在过去几个月里一直与他们进行实时交易,他们会有同样的表现吗?这一点让我很兴奋。
结果令人费解,令人沮丧。在最初的训练和验证运行中表现出色的模型,可能在以后的数据运行中表现良好,但也可能失败得很惨,并消耗掉所有的种子资金。一半的时间,模拟会赚钱,一半的时间,它会破产。有时候,这比掷硬币的效果好几个百分点,而有时候则糟糕得多。到底发生了什么事?它原本看起来充满希望的。
我终于明白了我所做的一切。
如果股票价格是随机波动,结果在50%左右循环正是你所期望的。通过让我的程序在数百只股票中寻找表现良好的股票,它确实偶然发现了一些股票,而这些股票恰好在验证时间范围内预测良好。然而,仅仅几周或几个月后,在随机游走的不同阶段,它失败了。
没有微妙的潜在模式。这个模型只是因为偶然的机会而幸运了几次,而我选择了那些实例。这是不可重复的。
因此,机器学习并不是魔术。它不能预测随机序列,在训练模型时你必须非常小心自己的偏见。仔细的验证是至关重要的。
我相信我不会是最后一个被阁楼里的旧藏宝图召唤的人,但是要小心。如果你想学习的话,随机的时间序列要少得多。仔细模拟、验证并意识到自己的偏见。
原文链接:https://towardsdatascience.com/what-happened-when-i-tried-market-prediction-with-machine-learning-4108610b3422
图像来自 Pexels[/caption]当你开始你的第一个基本回归或分类模型的时候,它至少会在你的脑海里闪现。海量的时间序列数据,再加上让你提前退休的可能性,都有一种不可抗拒的吸引力,就像让你在祖父的阁楼里找到一张旧藏宝图。你怎么能不去努力呢?你能用机器学习来预测股票市场吗?
我至少得试一试。这就是我所做的,也是我所学到的。
网上有很多小范围的教程,是一个很好的起点。它们向您展示了如何提取股票的历史数据,可能还会计算一些指标,并将其输入回归算法,并尝试预测第二天的股价。或者,他们使用一个分类器来预测股票是上涨还是下跌,而不预测一个值。
关于今后的发展方向,我有两个想法。首先,我想做大一点。我的理论是,某些股票、货币和金融指标之间可能隐藏着微妙的关系,肉眼很难发现。我想一个机器学习算法也许能找出它们的关系。
其次,我不会选择我想预测的股票。我打算为他们所有人训练模型,看看哪些股票表现最好。我的想法是,有些公司可能比其他公司更容易预测,所以我需要找到它们。
我首先下载了标准普尔500指数中大多数股票的历史数据,一堆货币价值历史数据,以及几十个财务指标。一个Python脚本负责将它们转换成一致的格式,填充丢失的值,并删除至少不能追溯到2000年初的时间序列。总之,当尘埃散去时,我在一个漂亮的Pandas表中有超过1000列,其中有18年的数据。
完成后,我使用优秀的TA-lib库为5、10和30天的窗口计算每个时间序列的一系列指标。我没有金融背景,也不知道哪些会真正增加价值,所以我采取的方法是把它们加起来,让模型对它们进行分类。这使得列数激增。数据集已经准备好输入超过32000列的训练模型。
我之所以选择XGBoost作为我的算法,是因为它具有整体性能,并且能够方便地查看模型使用哪些特性进行预测。我将其设置为遍历数据集中的所有股票,并为每个股票训练两个模型。第一个是分类器,它可以预测第二天股票的涨跌。第二种是回归模型,预测第二天的收盘价。
对于每个模型,我都将它训练在95%的可用数据上,然后使用剩下的数据进行验证测试,以模拟它从未见过的股票数据。剩下的5%是大约3个月的交易数据。任何机器学习模型都能很好地预测它所训练的数据——关键是要让它更通用,并在它从未接触过的数据上表现良好。
对于验证运行,启动时进行了1000美元的模拟投资。如果预测该股会上涨,它就会买进;如果预测该股会下跌,它就会卖出。他们没有考虑交易成本,因为我想看看如果不考虑交易成本,结果会怎样。
我把Jetson TX2开了一个月。
它发现了什么?
正如预期的那样,对于大多数股票来说,结果都很糟糕——准确性并不比抛硬币好多少。不过,有一些似乎在验证数据上表现得特别好。有好几家公司在3到6个月的时间里把我的模拟资金翻了两倍甚至三倍,还有几家公司在那段时间里获得了20倍的利润。结果显示,一个图表可以让你的心率飙升。
请记住,这是算法之前从未见过的数据——最后的5%被保留在训练数据集之外。
[caption id="attachment_47768" align="aligncenter" width="2000"]
顶部是股票收盘价,底部是现金。跌到接近零是买入。[/caption]我找到了吗?是否有一些股票与市场指标微妙地联系在一起,从而可以预测?如果是这样,我可以从价格的波动中赚钱。
当我写完代码并运行它时,距离我下载巨大的数据集已经过去了几个月。我对它进行了更新,包括了最新的交易数据,并决定看看模型在这段时间内会做些什么。他们的验证运行做得很好——如果我在过去几个月里一直与他们进行实时交易,他们会有同样的表现吗?这一点让我很兴奋。
结果令人费解,令人沮丧。在最初的训练和验证运行中表现出色的模型,可能在以后的数据运行中表现良好,但也可能失败得很惨,并消耗掉所有的种子资金。一半的时间,模拟会赚钱,一半的时间,它会破产。有时候,这比掷硬币的效果好几个百分点,而有时候则糟糕得多。到底发生了什么事?它原本看起来充满希望的。
经验教训
我终于明白了我所做的一切。
如果股票价格是随机波动,结果在50%左右循环正是你所期望的。通过让我的程序在数百只股票中寻找表现良好的股票,它确实偶然发现了一些股票,而这些股票恰好在验证时间范围内预测良好。然而,仅仅几周或几个月后,在随机游走的不同阶段,它失败了。
没有微妙的潜在模式。这个模型只是因为偶然的机会而幸运了几次,而我选择了那些实例。这是不可重复的。
因此,机器学习并不是魔术。它不能预测随机序列,在训练模型时你必须非常小心自己的偏见。仔细的验证是至关重要的。
我相信我不会是最后一个被阁楼里的旧藏宝图召唤的人,但是要小心。如果你想学习的话,随机的时间序列要少得多。仔细模拟、验证并意识到自己的偏见。
原文链接:https://towardsdatascience.com/what-happened-when-i-tried-market-prediction-with-machine-learning-4108610b3422

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
如何处理缺失值








广告


写评论取消
回复取消