











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






微软的FastSpeech AI加速真实声音的生成
2019年12月13日 由 TGS 发表
754761
0
 最先进的文本语音转换模型生成的声音,提起来与人类声音几乎相差无几。它们支持谷歌助手提供的神经声音,以及最近Alexa和亚马逊Polly服务提供的新闻播报员声音。但因为大多数模型共享相同的合成方法——生成一个mel-spectrogram的表示文本,然后使用声码器合成语音,所以,这些模型有一个相同的缺点。即——推理mel-spectrogram代缓慢,容易重复或跳过单词。
最先进的文本语音转换模型生成的声音,提起来与人类声音几乎相差无几。它们支持谷歌助手提供的神经声音,以及最近Alexa和亚马逊Polly服务提供的新闻播报员声音。但因为大多数模型共享相同的合成方法——生成一个mel-spectrogram的表示文本,然后使用声码器合成语音,所以,这些模型有一个相同的缺点。即——推理mel-spectrogram代缓慢,容易重复或跳过单词。为了解决这个问题,来自微软和浙江大学的研究人员开发了一种新型的机器学习模型,FastSpeech。据开发团队在温哥华的NeurIPS 2019会议上发表的论文介绍,该模型具有一个独特的体系结构,不仅能提高性能,还可以消除单词重复或跳过的问题。
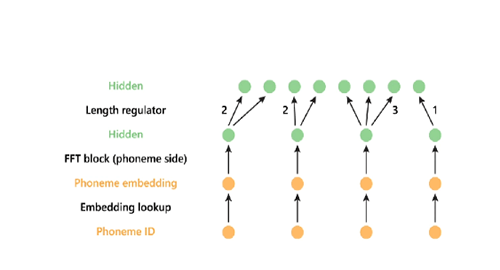 FastSpeech的长度调节器,可以调节mel-光谱图序列和音素序列之间的差异。由于音素序列的长度总是小于mel谱图序列的长度,所以一个音素对应几个mel谱图。然后,长度调整器根据持续时间扩展音素序列,使其与mel-光谱图序列的长度相匹配。(一个互补的持续时间预测成分决定了每个音素的持续时间。)最后,增加或减少与音素对齐的melb谱图数量或音素持续时间,按比例调整语速。
FastSpeech的长度调节器,可以调节mel-光谱图序列和音素序列之间的差异。由于音素序列的长度总是小于mel谱图序列的长度,所以一个音素对应几个mel谱图。然后,长度调整器根据持续时间扩展音素序列,使其与mel-光谱图序列的长度相匹配。(一个互补的持续时间预测成分决定了每个音素的持续时间。)最后,增加或减少与音素对齐的melb谱图数量或音素持续时间,按比例调整语速。为了验证FastSpeech的有效性,研究人员将其与开源的LJ语音数据集和相应的文本进行了测试。在将语料库随机分为12500个训练样本、300个验证样本和300个测试样本后,他们对语音质量、鲁棒性等进行了一系列详细的评估与检测。
该团队报告称,FastSpeech的质量几乎与谷歌的Tacotron 2文本语音转换模型的质量相当,并且在鲁棒性方面明显优于领先的、基于变压器的模型,有效错误率为0%,基线错误率为34%。此外,它还能够将生成声音的速度,从0.5倍提高到1.5倍且不损失准确性。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消