











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何用Python在笔记本电脑上分析100GB数据(下)
2019年12月15日 由 sunlei 发表
172411
0
前文回顾:如何用Python在笔记本电脑上分析100GB数据(上)
在本文的前一部分中,我们简要介绍了trip_distance列,在从异常值中清除它的同时,我们保留了所有小于100英里的行程值。这仍然是一个相当大的临界值,尤其是考虑到Yellow Taxi公司主要在曼哈顿运营。trip_distance列描述出租车从上客点到下客点的距离。然而,人们经常可以选择不同的路线,在两个确切的接送地点之间有不同的距离,例如为了避免交通堵塞或道路工程。因此,作为trip_distance列的一个对应项,让我们计算接送位置之间可能的最短距离,我们称之为arc_distance:
[caption id="attachment_48105" align="aligncenter" width="1340"]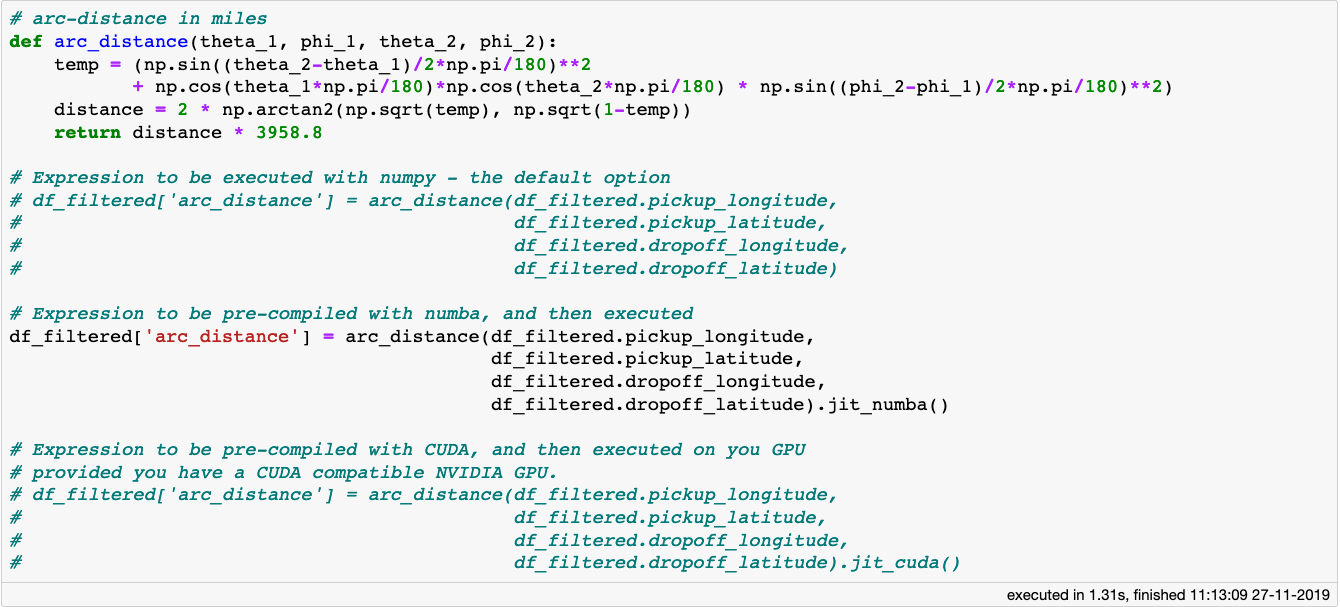 对于用numpy编写的复杂表达式,vaex可以在Numba、Pythran甚至CUDA(如果你有NVIDIA GPU的话)的帮助下使用即时编译来极大地提高你的计算速度。[/caption]
对于用numpy编写的复杂表达式,vaex可以在Numba、Pythran甚至CUDA(如果你有NVIDIA GPU的话)的帮助下使用即时编译来极大地提高你的计算速度。[/caption]
弧长计算公式涉及面广,包含了大量的三角函数和算法,特别是在处理大型数据集时,计算量大。如果表达式或函数只使用来自Numpy包的Python操作和方法编写,Vaex将使用机器的所有核心并行计算它。除此之外,通过使用Pythran(或通过C++加速)(通过使用C语言)加速,可以支持实时编译,提供更好的性能。如果您碰巧有一个NVIDIA图形卡,您可以通过jit_CUDA方法使用CUDA来获得更快的性能。
不管怎样,让我们来绘制行程距离和弧距离的分布:
[caption id="attachment_48109" align="aligncenter" width="1340"]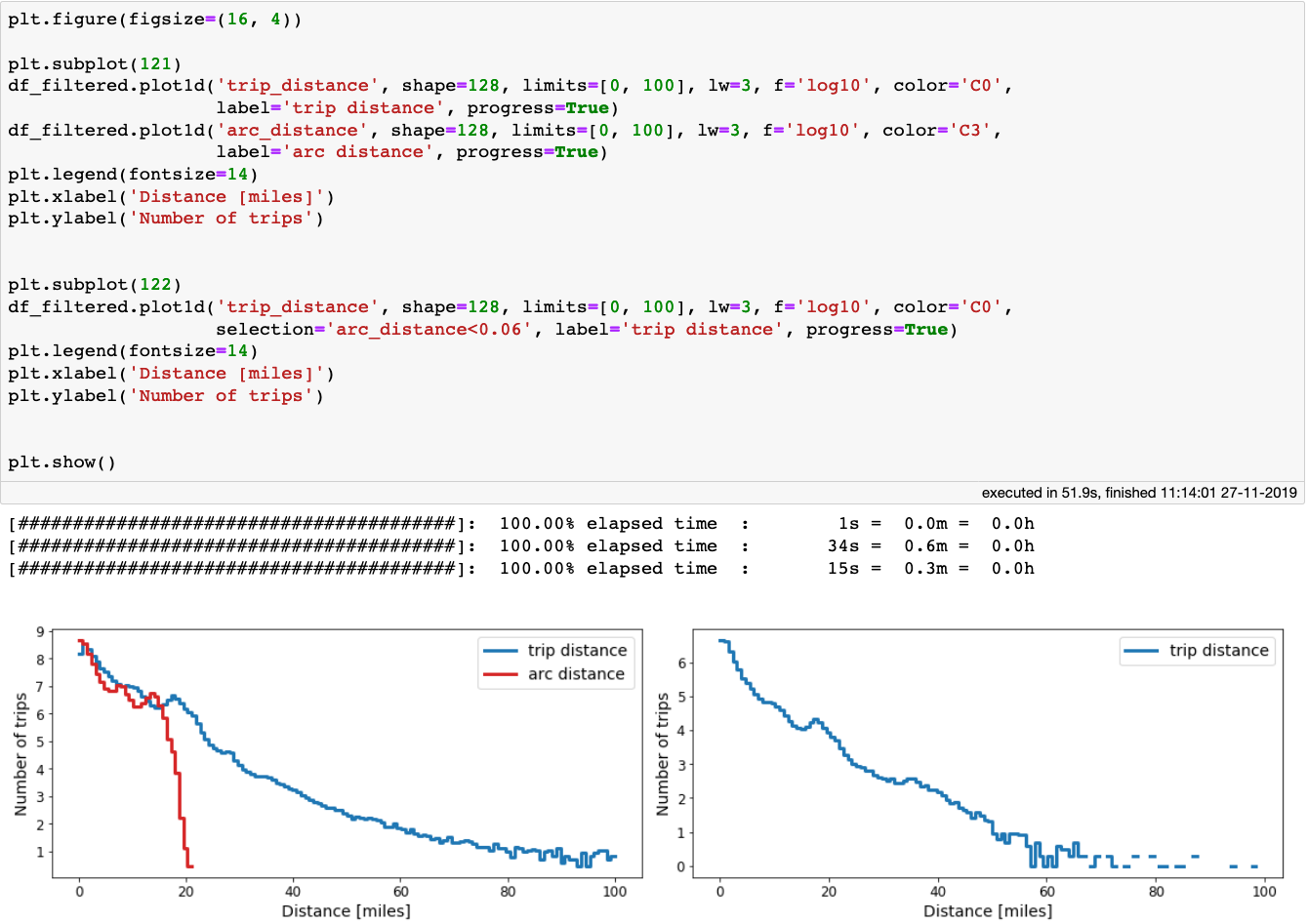 左:行程距离和弧距离的比较。右:弧距<100米的行程分布。[/caption]
左:行程距离和弧距离的比较。右:弧距<100米的行程分布。[/caption]
有趣的是,arc_distance从未超过21英里,但出租车实际行驶的距离可能是它的5倍。事实上,在数百万次的出租车行程中,落客点距离接客点只有100米(0.06英里)!
我们今天使用的数据集跨越7年。看看在那段时间里,人们对某些东西的兴趣是如何演变的,这可能会很有趣。使用Vaex,我们可以快速执行核心分组和聚合操作。让我们来探讨7年来票价和行程是如何演变的:
[caption id="attachment_48113" align="aligncenter" width="1340"] 对于一个超过10亿个样本的Vaex数据帧,在笔记本电脑上使用四核处理器进行8个聚合的分组操作只需不到2分钟。[/caption]
对于一个超过10亿个样本的Vaex数据帧,在笔记本电脑上使用四核处理器进行8个聚合的分组操作只需不到2分钟。[/caption]
在上面的单元格块中,我们执行分组操作,然后执行8个聚合,其中2个位于虚拟列上。上面的单元块在我的笔记本电脑上执行不到2分钟。考虑到我们使用的数据包含超过10亿个样本,这是相当令人印象深刻的。不管怎样,让我们看看结果。以下是多年来乘坐出租车的费用是如何演变的:
[caption id="attachment_48115" align="aligncenter" width="1340"]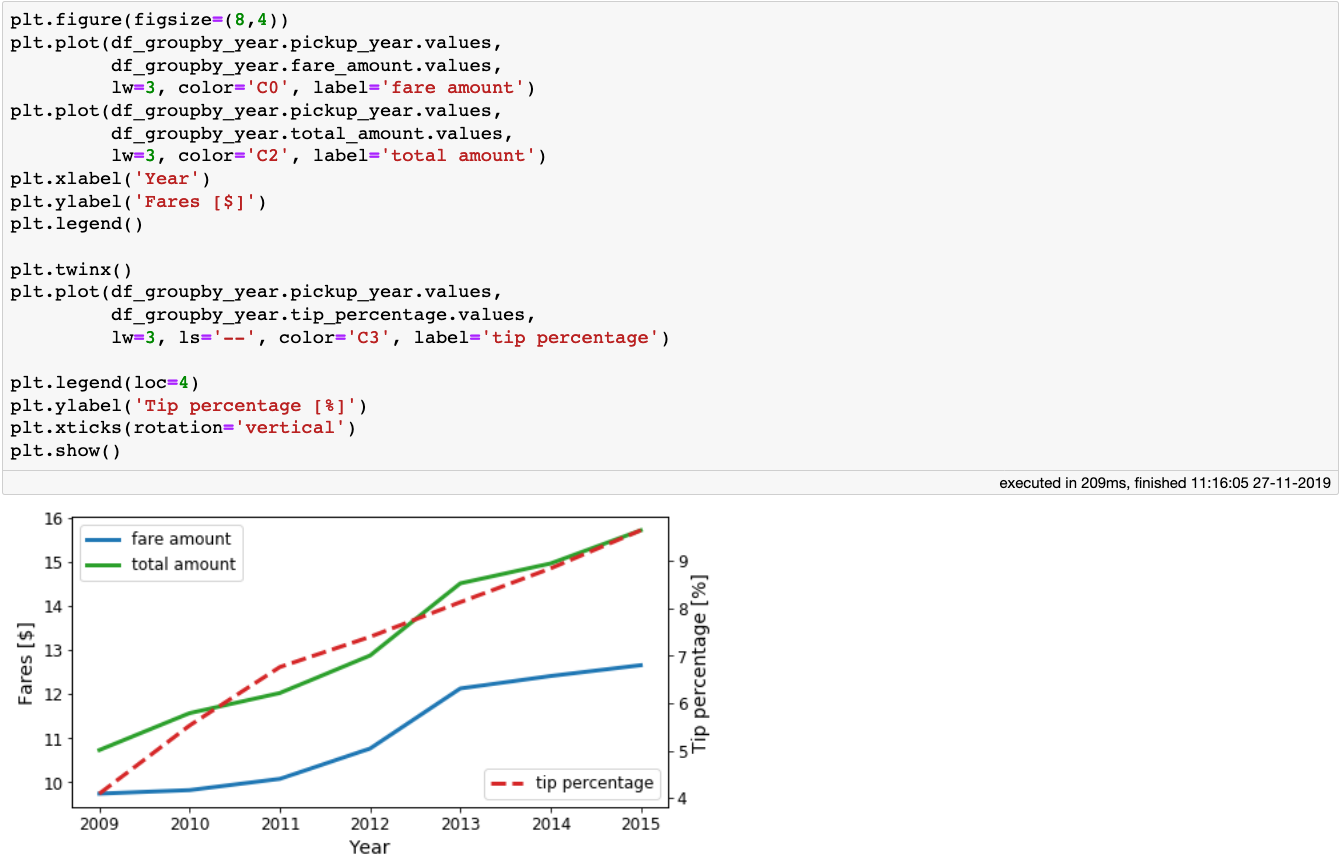 平均票价和总金额,以及乘客每年支付的小费百分比。[/caption]
平均票价和总金额,以及乘客每年支付的小费百分比。[/caption]
我们看到,随着时间的流逝,出租车费和小费都在上涨。现在让我们看看出租车的平均行驶距离和arc_distance,出租车是以年为单位行驶的:
[caption id="attachment_48116" align="aligncenter" width="1340"]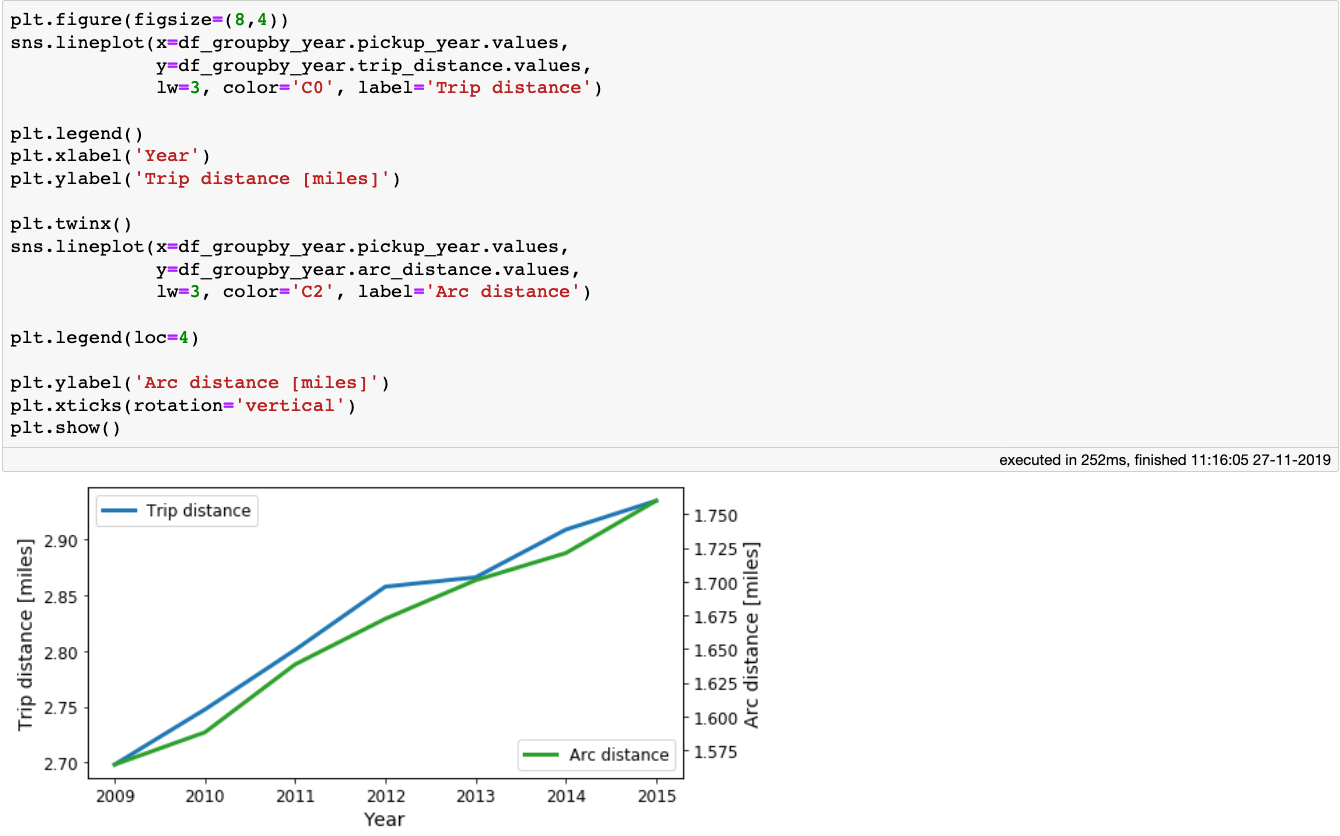 出租车每年的平均行程和弧距。[/caption]
出租车每年的平均行程和弧距。[/caption]
上图显示,出行距离和弧线距离都有小幅增加,这意味着,平均而言,人们每年的出行都会稍微远一点。
在我们的旅程结束之前,让我们再停一站,调查一下乘客如何支付乘车费用的。数据集包含付款类型列,因此让我们看看它包含的值:
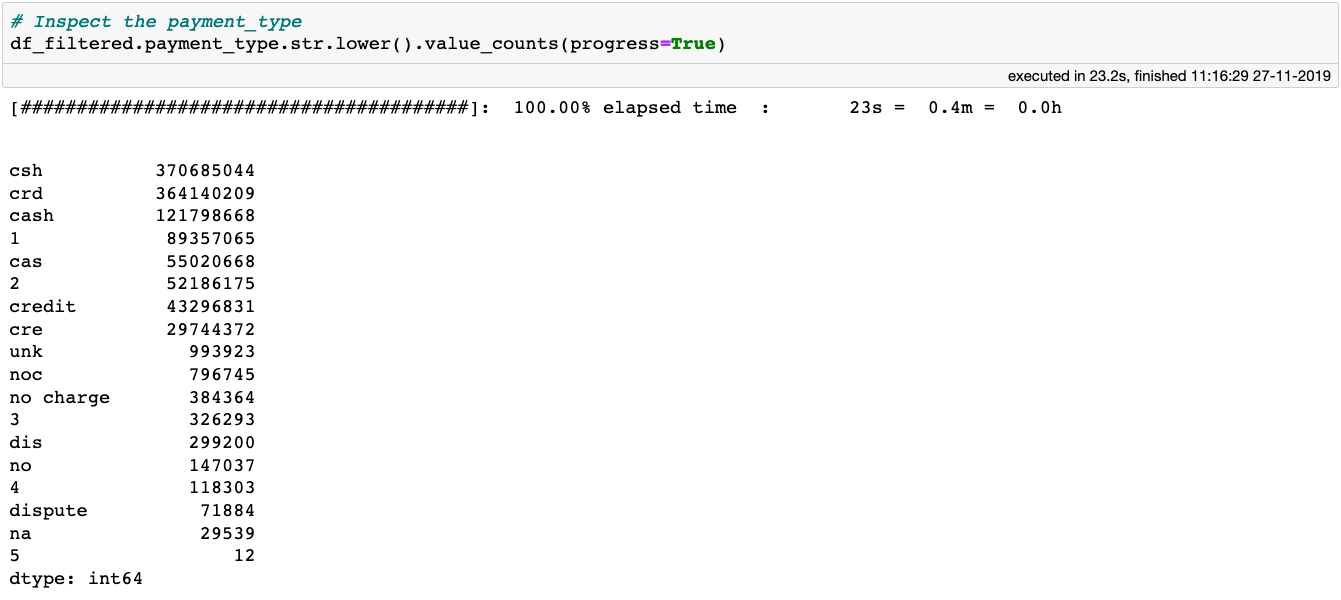 从数据集文档中,我们可以看到此列只有6个有效条目:
从数据集文档中,我们可以看到此列只有6个有效条目:
1=信用卡支付
2=现金支付
3=不收费
4=争议
5=未知
6=无效行程
因此,我们可以简单地将payment_type列中的条目映射为整数:
 现在,我们可以按每年的数据分组,看看纽约人在出租车租赁支付方面的习惯是如何改变的:
现在,我们可以按每年的数据分组,看看纽约人在出租车租赁支付方面的习惯是如何改变的:
[caption id="attachment_48119" align="aligncenter" width="1342"]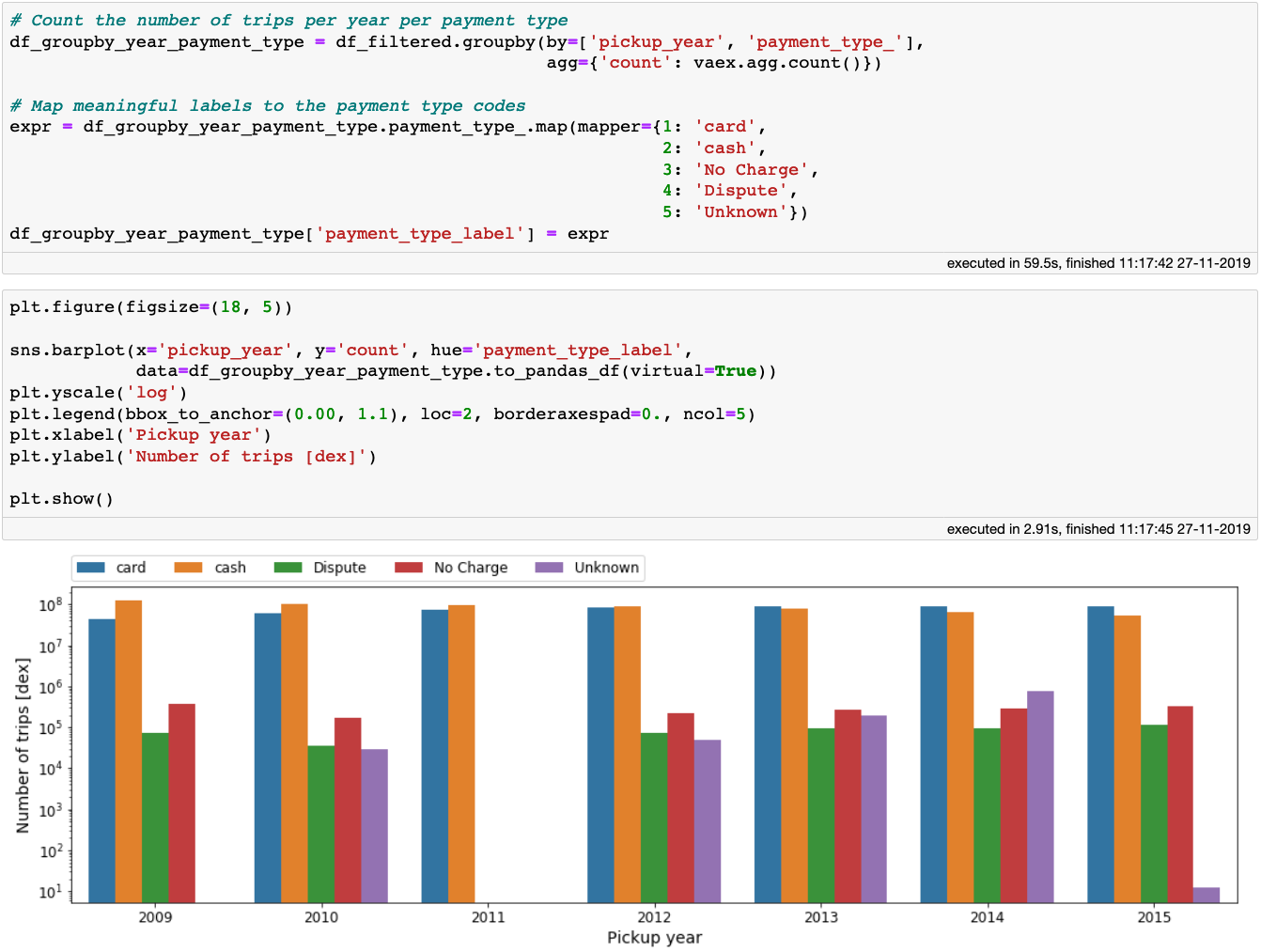 每年付款方式[/caption]
每年付款方式[/caption]
我们看到,随着时间的推移,信用卡支付慢慢变得比现金支付更频繁。我们真的生活在一个数字时代!注意,在上面的代码块中,一旦我们聚合了数据,小的Vaex数据帧可以很容易地转换为Pandas数据帧,我们可以方便地将其传递给Seaborn。
最后,让我们通过绘制现金支付与信用卡支付的比率来确定支付方式是取决于一天中的时间还是一周中的某一天。为此,我们将首先创建一个过滤器,它只选择用现金或卡支付的乘车。下一步是我最喜欢的Vaex特性之一:带有选择的聚合。其他库要求对以后合并为一个支付方法的每个单独筛选的数据帧进行聚合。另一方面,使用Vaex,我们可以通过在聚合函数中提供选择来一步完成此操作。这非常方便,只需要一次传递数据,就可以获得更好的性能。在此之后,我们只需以标准方式绘制结果数据帧:
[caption id="attachment_48120" align="aligncenter" width="1341"]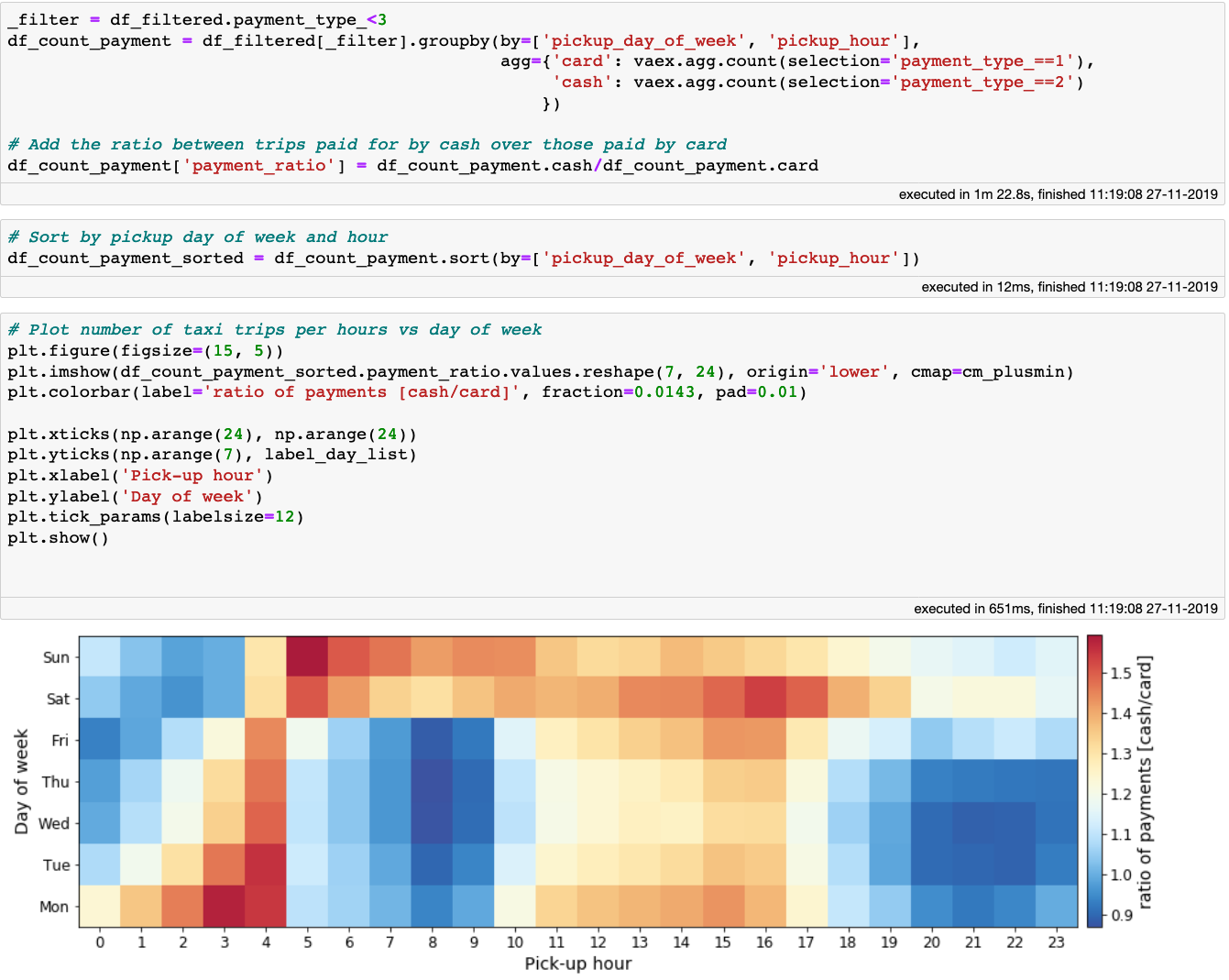 在一周的某一时间和某一天,现金对卡支付的一部分。[/caption]
在一周的某一时间和某一天,现金对卡支付的一部分。[/caption]
看上面的图表,我们可以发现一个类似的模式,显示小费百分比作为一周中的一天和一天中的时间的函数。从这两个图中,数据表明,用卡支付的乘客往往比用现金支付的乘客小费更多。为了弄清这是否真的是这样,我想请你试着去弄清楚,因为现在你已经掌握了知识、工具和数据!你也可以看看这个Jupyter notebook来获得一些额外的提示。
我希望这篇文章是对Vaex的一个有用的介绍,它将帮助您缓解您可能面临的一些“不舒服的数据”问题,至少在涉及表格数据集时是这样。如果您对本文中使用的数据集感兴趣,可以直接从S3使用Vaex。请参阅完整的Jupyter notebook,以了解如何做到这一点。
有了Vaex,你可以在短短几秒钟内浏览超过10亿行数据,计算各种统计数据、聚合信息,并生成信息图表,而这一切都是在你自己的笔记本电脑上完成的。它是免费和开源的,我希望你会给它一个机会!
数据科学快乐!
原文链接:https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94
发动引擎!
在本文的前一部分中,我们简要介绍了trip_distance列,在从异常值中清除它的同时,我们保留了所有小于100英里的行程值。这仍然是一个相当大的临界值,尤其是考虑到Yellow Taxi公司主要在曼哈顿运营。trip_distance列描述出租车从上客点到下客点的距离。然而,人们经常可以选择不同的路线,在两个确切的接送地点之间有不同的距离,例如为了避免交通堵塞或道路工程。因此,作为trip_distance列的一个对应项,让我们计算接送位置之间可能的最短距离,我们称之为arc_distance:
[caption id="attachment_48105" align="aligncenter" width="1340"]
对于用numpy编写的复杂表达式,vaex可以在Numba、Pythran甚至CUDA(如果你有NVIDIA GPU的话)的帮助下使用即时编译来极大地提高你的计算速度。[/caption]弧长计算公式涉及面广,包含了大量的三角函数和算法,特别是在处理大型数据集时,计算量大。如果表达式或函数只使用来自Numpy包的Python操作和方法编写,Vaex将使用机器的所有核心并行计算它。除此之外,通过使用Pythran(或通过C++加速)(通过使用C语言)加速,可以支持实时编译,提供更好的性能。如果您碰巧有一个NVIDIA图形卡,您可以通过jit_CUDA方法使用CUDA来获得更快的性能。
不管怎样,让我们来绘制行程距离和弧距离的分布:
[caption id="attachment_48109" align="aligncenter" width="1340"]
左:行程距离和弧距离的比较。右:弧距<100米的行程分布。[/caption]有趣的是,arc_distance从未超过21英里,但出租车实际行驶的距离可能是它的5倍。事实上,在数百万次的出租车行程中,落客点距离接客点只有100米(0.06英里)!
多年来的黄色出租车
我们今天使用的数据集跨越7年。看看在那段时间里,人们对某些东西的兴趣是如何演变的,这可能会很有趣。使用Vaex,我们可以快速执行核心分组和聚合操作。让我们来探讨7年来票价和行程是如何演变的:
[caption id="attachment_48113" align="aligncenter" width="1340"]
对于一个超过10亿个样本的Vaex数据帧,在笔记本电脑上使用四核处理器进行8个聚合的分组操作只需不到2分钟。[/caption]在上面的单元格块中,我们执行分组操作,然后执行8个聚合,其中2个位于虚拟列上。上面的单元块在我的笔记本电脑上执行不到2分钟。考虑到我们使用的数据包含超过10亿个样本,这是相当令人印象深刻的。不管怎样,让我们看看结果。以下是多年来乘坐出租车的费用是如何演变的:
[caption id="attachment_48115" align="aligncenter" width="1340"]
平均票价和总金额,以及乘客每年支付的小费百分比。[/caption]我们看到,随着时间的流逝,出租车费和小费都在上涨。现在让我们看看出租车的平均行驶距离和arc_distance,出租车是以年为单位行驶的:
[caption id="attachment_48116" align="aligncenter" width="1340"]
出租车每年的平均行程和弧距。[/caption]上图显示,出行距离和弧线距离都有小幅增加,这意味着,平均而言,人们每年的出行都会稍微远一点。
给我看看钱的方面
在我们的旅程结束之前,让我们再停一站,调查一下乘客如何支付乘车费用的。数据集包含付款类型列,因此让我们看看它包含的值:
从数据集文档中,我们可以看到此列只有6个有效条目:1=信用卡支付
2=现金支付
3=不收费
4=争议
5=未知
6=无效行程
因此,我们可以简单地将payment_type列中的条目映射为整数:
现在,我们可以按每年的数据分组,看看纽约人在出租车租赁支付方面的习惯是如何改变的:[caption id="attachment_48119" align="aligncenter" width="1342"]
每年付款方式[/caption]我们看到,随着时间的推移,信用卡支付慢慢变得比现金支付更频繁。我们真的生活在一个数字时代!注意,在上面的代码块中,一旦我们聚合了数据,小的Vaex数据帧可以很容易地转换为Pandas数据帧,我们可以方便地将其传递给Seaborn。
最后,让我们通过绘制现金支付与信用卡支付的比率来确定支付方式是取决于一天中的时间还是一周中的某一天。为此,我们将首先创建一个过滤器,它只选择用现金或卡支付的乘车。下一步是我最喜欢的Vaex特性之一:带有选择的聚合。其他库要求对以后合并为一个支付方法的每个单独筛选的数据帧进行聚合。另一方面,使用Vaex,我们可以通过在聚合函数中提供选择来一步完成此操作。这非常方便,只需要一次传递数据,就可以获得更好的性能。在此之后,我们只需以标准方式绘制结果数据帧:
[caption id="attachment_48120" align="aligncenter" width="1341"]
在一周的某一时间和某一天,现金对卡支付的一部分。[/caption]看上面的图表,我们可以发现一个类似的模式,显示小费百分比作为一周中的一天和一天中的时间的函数。从这两个图中,数据表明,用卡支付的乘客往往比用现金支付的乘客小费更多。为了弄清这是否真的是这样,我想请你试着去弄清楚,因为现在你已经掌握了知识、工具和数据!你也可以看看这个Jupyter notebook来获得一些额外的提示。
我们到达了你的目的地
我希望这篇文章是对Vaex的一个有用的介绍,它将帮助您缓解您可能面临的一些“不舒服的数据”问题,至少在涉及表格数据集时是这样。如果您对本文中使用的数据集感兴趣,可以直接从S3使用Vaex。请参阅完整的Jupyter notebook,以了解如何做到这一点。
有了Vaex,你可以在短短几秒钟内浏览超过10亿行数据,计算各种统计数据、聚合信息,并生成信息图表,而这一切都是在你自己的笔记本电脑上完成的。它是免费和开源的,我希望你会给它一个机会!
数据科学快乐!
原文链接:https://towardsdatascience.com/how-to-analyse-100s-of-gbs-of-data-on-your-laptop-with-python-f83363dda94

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消