盘点 NeurIPS 2019上各大公司发布的最新AI算法
2019年12月18日 由 KING 发表
618396
0
Nvidia:2D到3D
Nvidia提出了一种逆向渲染框架,该框架基于2D照片和视频来预测有关对象的3D信息。
Nvidia的AI团队已经构建了一个逆向渲染器,对于机器学习至关重要,它可以产生不同的结果。渲染是计算机图形世界中众所周知的过程,它根据3D数据生成对象和场景的2D投影。这里的目的是做相反的事情:从2D到3D。 Nvidia的算法称为DIB-R(可微分基于插值的渲染器)是“迄今为止最完善的算法”。它可以预测对象的几何形状,颜色和纹理,并推断场景中的照明。
Nvidia的算法称为DIB-R(可微分基于插值的渲染器)是“迄今为止最完善的算法”。它可以预测对象的几何形状,颜色和纹理,并推断场景中的照明。
EETimes论文的作者、Nvidia的AI主管Sanja Fidler教授说:“由于所有参数都是经过解析计算的,因此它可以非常有效地完成此任务,这对于机器学习非常重要。在该领域中已经存在的较旧的技术依赖于手工设计渐变和近似渐变,并且很难训练。”
在单个V100 GPU上训练Nvidia的模型需要花费两天的时间,而推理只需不到100毫秒的时间。通过连续更改多边形球体来创建3D对象。
Intel:教机器人团队合作
来自英特尔、俄勒冈州立大学和加利福尼亚大学的研究人员发表了一篇有关新型强化学习的论文,该论文可以教机器人团体进行协作。
在强化学习中,两个AI代理(执行某种动作的算法)一起工作以改善它们的综合效果。一个代理产生结果,而另一个则评估那些结果,从而以更高的分数奖励与预期结果非常相似的结果。 新技术MERL(多主体进化强化学习)建立在英特尔现有的CERL(协同进化强化学习)研究之上,该技术使代理能够学习具有挑战性的连续控制问题,例如训练人形机器人从头开始。
新技术MERL(多主体进化强化学习)建立在英特尔现有的CERL(协同进化强化学习)研究之上,该技术使代理能够学习具有挑战性的连续控制问题,例如训练人形机器人从头开始。
MERL可以训练机器人团队共同解决任务。这是一个棘手的问题,因为单个代理的目标可能与团队的总体目标有所不同。单个目标通常也比较密集,这意味着它们更快,更容易实现,因此更具吸引力。培训代理人同时努力实现两组结果特别困难。
该团队还在研究类似的问题,这些问题涉及在没有明确的奖励反馈的情况下的多任务学习,以及沟通在这些任务中的作用。
IBM:使用8位数据进行培训
IBM提交的论文之一是低精度培训的技术。虽然通常使用低精度数据进行推理,但在训练系统中使用较高精度的数字可以保持所得模型中权重的准确性。但是,切换到较低的精度数字(称为量化的过程)很有吸引力,因为需要较少的计算量,较少的存储量和较少的电量。 去年,IBM在NeurIPS上展示了首批8位训练技术,其中包括8位浮点方案。今年,它提出了一种混合方法(混合8位浮点数或HFP8),旨在提高计算性能,同时保持最具挑战性的最新深度神经网络的准确性。
去年,IBM在NeurIPS上展示了首批8位训练技术,其中包括8位浮点方案。今年,它提出了一种混合方法(混合8位浮点数或HFP8),旨在提高计算性能,同时保持最具挑战性的最新深度神经网络的准确性。
这项工作改进了去年的发展,因为新格式HFP8克服了以前因量化而导致信息丢失的模型对训练精度的损失。HFP8在前向路径中使用新颖的FP8位格式来获得更高的分辨率,在后向路径中使用另一种FP8位格式来实现更大范围的渐变。
Google:培训巨型网络
随着深度神经网络(DNN)规模的不断增加,它们正在推动处理芯片中的内存限制,甚至包括专门用于Google自己的TPU(张量处理单元)的芯片。可以使用多个加速器,但是DNN的顺序性质意味着,如果操作不当,则任何时候只有一个加速器处于活动状态,这是无效的。可以使用数据并行性,其中使用每个芯片上不同的数据子集来训练相同的模型,但这并不能扩展到更大的模型。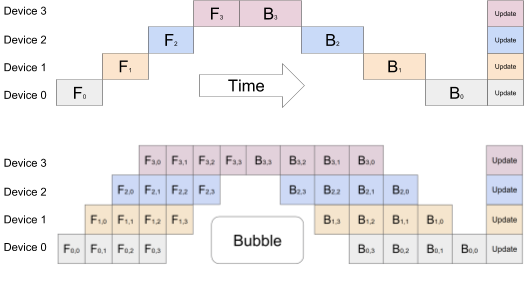 Google的团队已使用管道并行性来尝试解决此问题。他们创建了GPipe,这是一个新的机器学习库,可在可表示为层序列的任何神经网络上工作。新的库使研究人员可以轻松部署更多的加速器来训练更大的模型并扩展性能,而无需调整超参数。
Google的团队已使用管道并行性来尝试解决此问题。他们创建了GPipe,这是一个新的机器学习库,可在可表示为层序列的任何神经网络上工作。新的库使研究人员可以轻松部署更多的加速器来训练更大的模型并扩展性能,而无需调整超参数。
GPipe在多个加速器之间划分了要训练的模型,使用新颖的批量拆分流水线算法将批量数据拆分为较小的微批量。研究人员说,当模型训练被分配到多个加速器时,这可以导致几乎线性的加速。
Facebook:SuperGLUE
来自Facebook、纽约大学、华盛顿大学和DeepMind的研究团队一直在为理解语言的算法制定新的基准。基准最初称为GLUE,它基于一组九种自然语言处理(NLP)任务,为模型性能提供了一个单一指标。 去年,用于理解语言的算法突飞猛进,在某些情况下超过了非专家的性能。因此,GLUE需要发展。团队已将他们的工作更新为新的基准,其中包括更严格的NLP任务,软件工具包和公共排行榜。他们已将其重命名为SuperGLUE。
去年,用于理解语言的算法突飞猛进,在某些情况下超过了非专家的性能。因此,GLUE需要发展。团队已将他们的工作更新为新的基准,其中包括更严格的NLP任务,软件工具包和公共排行榜。他们已将其重命名为SuperGLUE。
根据最新的基准评分,Google的T5模型目前处于领先地位,得分为88.9(接近人类基线的89.8)。Facebook的RoBERTa模型的时钟频率为84.6,IBM的BERT-mtl模型的时钟频率为73.5。





























