











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






2019深度学习语音合成指南(上)
2019年12月21日 由 sunlei 发表
551389
0
人工生成的人类语音被称为语音合成。这种基于机器学习的技术适用于文本到语音转换、音乐生成、语音生成、启用语音的设备、导航系统以及视障人士的可访问性。
在本文中,我们将研究使用深度学习编写和开发的研究和模型体系结构。
但在我们开始之前,有几个具体的,传统的语音合成策略,我们需要简要概述:连接和参数。
在串联方法中,使用来自大型数据库的语音生成新的、可听的语音。在需要不同风格的语音的情况下,将使用一个新的音频声音数据库。这限制了这种方法的可伸缩性。
参数化方法使用录制的人声和具有一组参数的函数,可以修改这些参数来更改声音。
这两种方法代表了旧的语音合成方法。现在让我们看看使用深度学习的新方法。下面是我们将介绍的研究,目的是研究当前流行的语音合成方法:
文章链接: https://arxiv.org/abs/1609.03499
这篇文章的作者来自谷歌。他们提出了一种能产生原始音频波的神经网络。他们的模型是完全概率的和自回归的,在英语和汉语的text-to-speech上都取得了最先进的结果。

WaveNET是基于PixelCNN的音频生成模型,它能够产生类似于人类发出的声音。
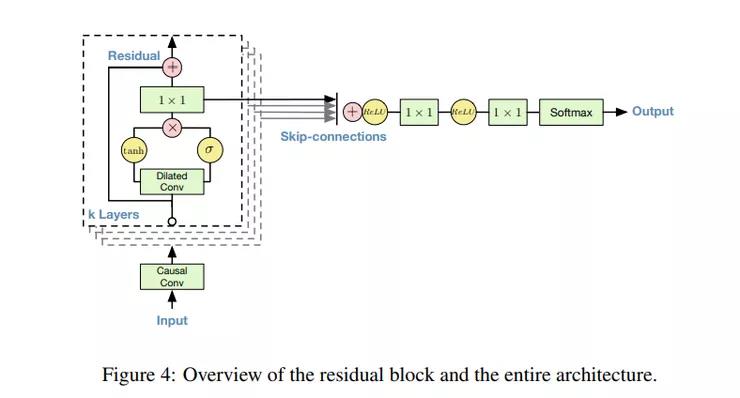
在这个生成模型中,每个音频样本都以先前的音频样本为条件。条件概率用一组卷积层来建模。这个网络没有池化层,模型的输出与输入具有相同的时间维数。
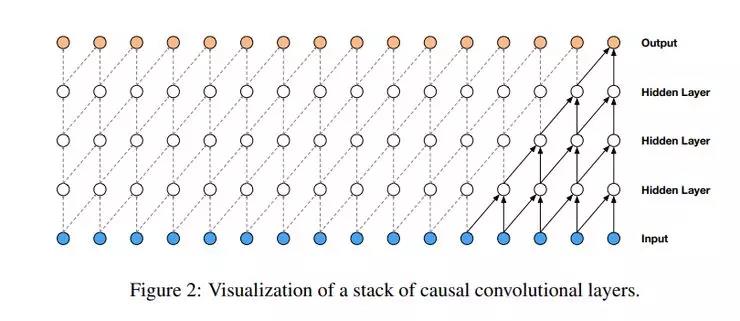
在模型架构中使用临时卷积可以确保模型不会违反数据建模的顺序。在该模型中,每个预测语音样本被反馈到网络上用来帮助预测下一个语音样本。由于临时卷积没有周期性连接,因此它们比RNN训练地更快。
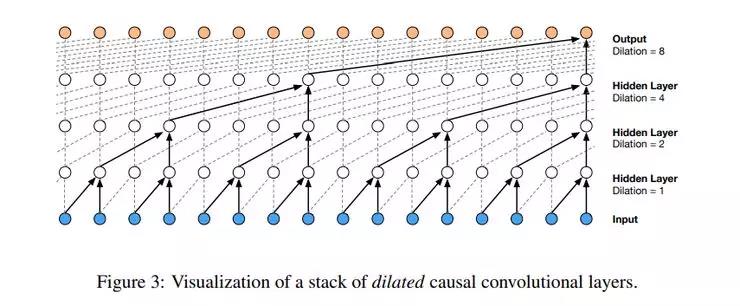
使用临时卷积的主要挑战之一是,它们需要很多层来增加感受野。为了解决这一难题,作者使用了加宽的卷积。加宽的卷积使只有几层的网络能有更大的感受野。模型使用了Softmax分布对各个音频样本的条件分布建模。
这个模型在多人情景的语音生成、文本到语音的转换、音乐音频建模等方面进行了评估。测试中使用的是平均意见评分(MOS),MOS可以评测声音的质量,本质上就是一个人对声音质量的评价一样。它有1到5之间的数字,其中5表示质量最好。
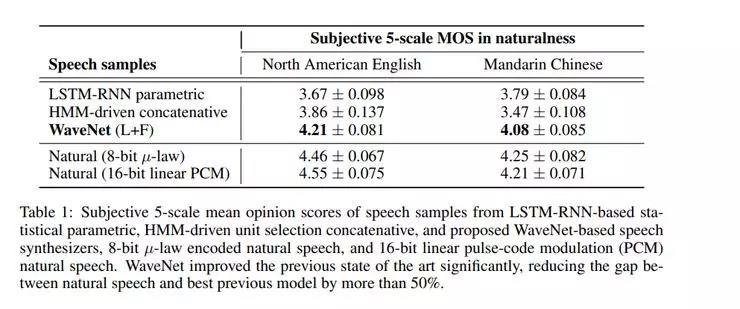
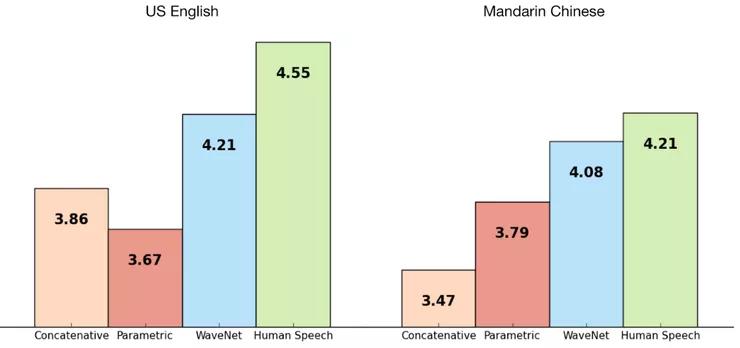
下图显示了1-5级waveNet的语音质量
文章链接:https://arxiv.org/abs/1703.10135
这篇文章的作者来自谷歌。Tacotron是一种端到端的生成性文本转化语音的模型,可直接从文本和音频对合形成语音。Tacotron在美式英语上获得3.82分的平均得分。Tacotron是在帧级生成语音,因此比样本级自回归的方法更快。
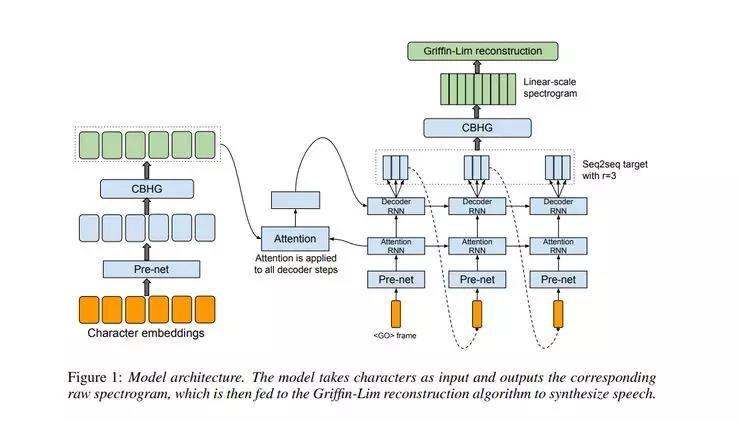
这个模型是在音频和文本对上进行的训练,因此它可以非常方便地应用到新的数据集上。Tacotron是一个seq2seq模型,该模型包括一个编码器、一个基于注意力的解码器以及一个后端处理网络(post-processing net)。如下框架图所示,该模型输入字符,输出原始谱图。然后把这个谱图转换成波形图。
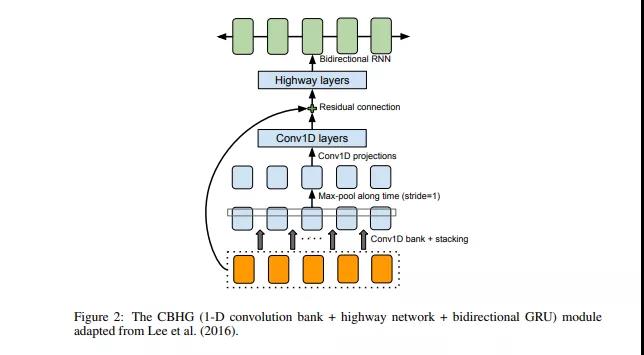
下图显示了CBHG模块的结构。它由1-D卷积滤波器,highway networks和双向GRU(Gated Recurrent Unit)组成。
将字符序列输入编码器,编码器将提取出文本的顺序表示。每个字符被表示为一个独热向量嵌入到连续向量中。然后加入非线性变换,再然后加上一个dropout,以减少过度拟合。这在本质上减少了单词的发音错误。
模型所用的解码器是基于内容注意力的tanh解码器。然后使用Griffin-Lim算法生成波形图。该模型使用的超参数如下所示。

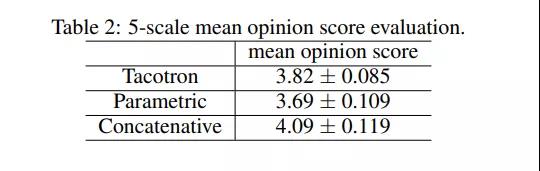
下图显示了与其他替代方案相比,Tacotron的性能优势。
文章链接:https://arxiv.org/abs/1702.07825
这篇文章的作者来自百度硅谷人工智能实验室。Deep Voice是一个利用深度神经网络开发的文本到语音的系统.
它有五个重要的组成模块:
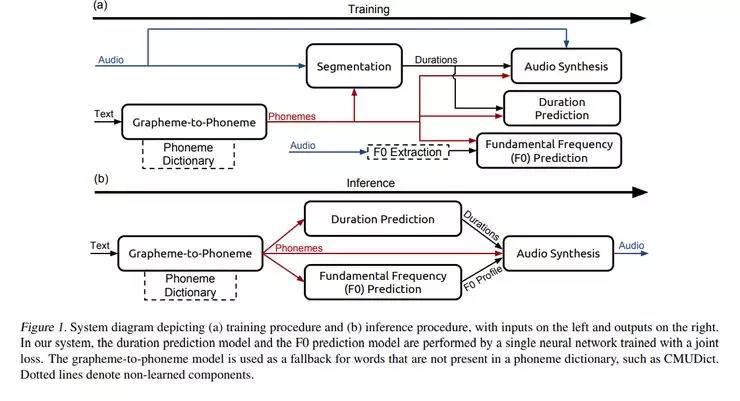
字母到音素模型将英文字符转换为音素。分割模型识别每个音素在音频文件中开始和结束的位置。音素持续时间模型预测音素序列中每个音素的持续时间。
基频模型预测音素是否发声。音频合成模型则综合了字母到音素转换模型、音素持续时间模型、基频预测模型等的输出进行音频合成。
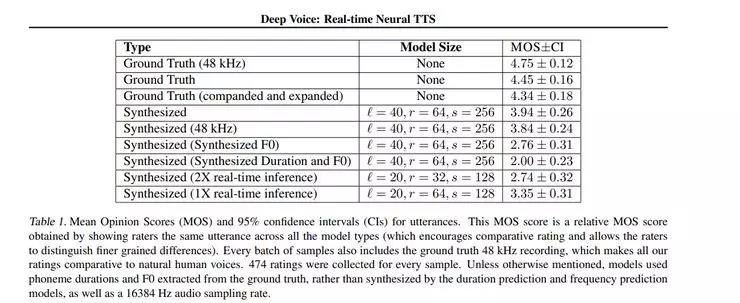
以下是它与其他模型的对比情况
文章链接:https://arxiv.org/abs/1705.08947
这篇文章是百度硅谷人工智能实验室在Deep Voice上的二次迭代。他们介绍了一种利用低维可训练说话人嵌入来增强神经文本到语音的方法,这可以从单个模型产生不同的声音。
该模型与DeepVoice 1有类似的流水线,但它在音频质量上却有显著的提高。该模型能够从每个说话人不到半个小时的语音数据中学习数百种独特的声音。
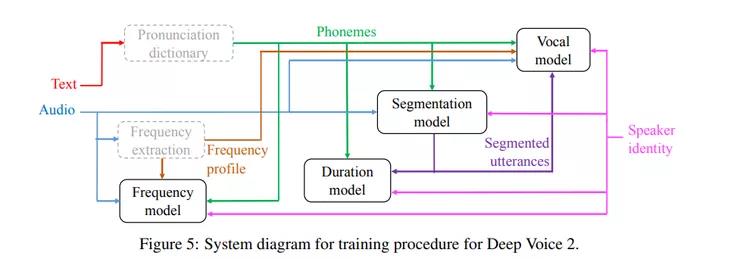
作者还介绍了一种基于WaveNet的声谱到音频的神经声码器,并将其与Taco tron结合,代替Griffin-Lim音频生成。这篇文章的重点是处理多个说话人而每个说话人的数据有非常少的情况。模型的架构类似于Deep Voice 1,训练过程如下图所示。
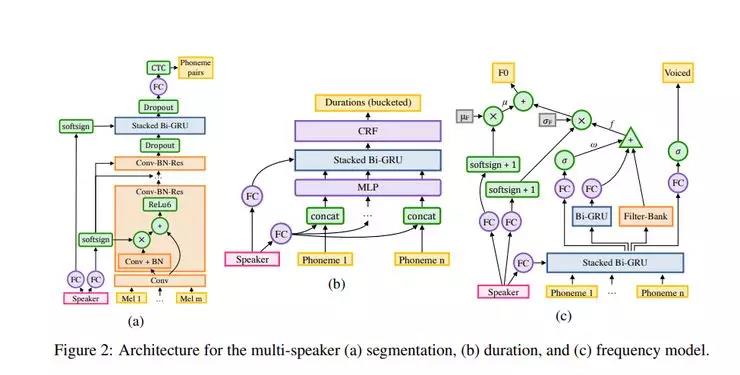
Deep Voice 2和Deep Voice 1之间的主要区别在于音素持续时间模型和频率模型的分离。Deep Voice 1有一个用于联合预测音素持续时间和频率曲线的单一模型; 而在Deep Voice 2中,则先预测音素持续时间,然后将它们用作频率模型的输入。
Deep Voice 2中的分割模型使用一种卷积递归结构(采用连接时间分类(CTC)损失函数)对音素对进行分类。Deep Voice 2的主要修改是在卷积层中添加了大量的归一化和残余连接。它的发声模型是基于WaveNet架构的。
从多个说话人合成语音,主要通过用每个说话人的单个低维级说话人嵌入向量增强每个模型来完成的。说话人之间的权重分配,则是通过将与说话人相关的参数存储在非常低维的矢量中来实现。
递归神经网络(RNN)的初始状态由说话人声音的嵌入产生。采用均匀分布的方法随机初始化说话人声音的嵌入,并用反向传播对其进行联合训练。说话人声音的嵌入包含在模型的多个部分中,以确保能考虑到每个说话人的声音特点。
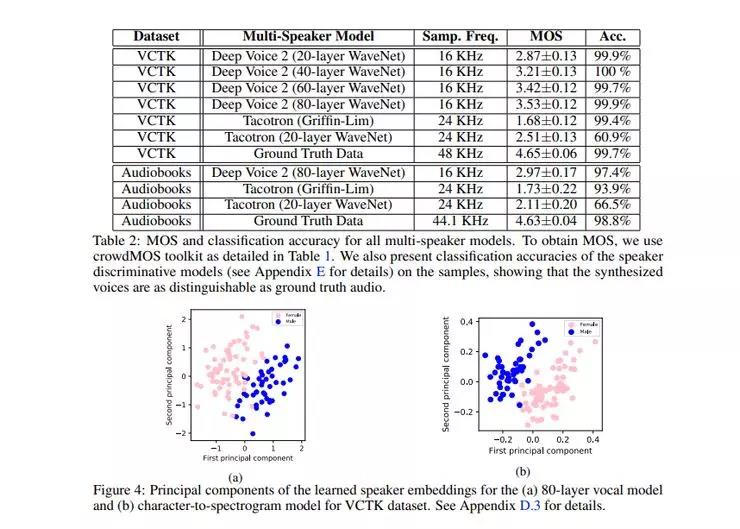
接下来让我们看看与其他模型相比它的性能如何
原文链接:https://heartbeat.fritz.ai/a-2019-guide-to-speech-synthesis-with-deep-learning-630afcafb9dd
在本文中,我们将研究使用深度学习编写和开发的研究和模型体系结构。
但在我们开始之前,有几个具体的,传统的语音合成策略,我们需要简要概述:连接和参数。
在串联方法中,使用来自大型数据库的语音生成新的、可听的语音。在需要不同风格的语音的情况下,将使用一个新的音频声音数据库。这限制了这种方法的可伸缩性。
参数化方法使用录制的人声和具有一组参数的函数,可以修改这些参数来更改声音。
这两种方法代表了旧的语音合成方法。现在让我们看看使用深度学习的新方法。下面是我们将介绍的研究,目的是研究当前流行的语音合成方法:
- WaveNet: 原始音频生成模型
- Tacotron:端到端的语音合成
- Deep Voice 1: 实时神经文本语音转换
- Deep Voice 2: 多说话人神经文本语音转换
- Deep Voice 3: 带有卷积序列学习的尺度文本语音转换
- Parallel WaveNet: 快速高保真语音合成
- 利用小样本的神经网络语音克隆
- VoiceLoop: 通过语音循环进行语音拟合与合成
- 利用梅尔图谱预测上的条件WaveNet进行自然TTS合成
WaveNet: 原始音频生成模型
文章链接: https://arxiv.org/abs/1609.03499
这篇文章的作者来自谷歌。他们提出了一种能产生原始音频波的神经网络。他们的模型是完全概率的和自回归的,在英语和汉语的text-to-speech上都取得了最先进的结果。
WaveNET是基于PixelCNN的音频生成模型,它能够产生类似于人类发出的声音。
在这个生成模型中,每个音频样本都以先前的音频样本为条件。条件概率用一组卷积层来建模。这个网络没有池化层,模型的输出与输入具有相同的时间维数。
在模型架构中使用临时卷积可以确保模型不会违反数据建模的顺序。在该模型中,每个预测语音样本被反馈到网络上用来帮助预测下一个语音样本。由于临时卷积没有周期性连接,因此它们比RNN训练地更快。
使用临时卷积的主要挑战之一是,它们需要很多层来增加感受野。为了解决这一难题,作者使用了加宽的卷积。加宽的卷积使只有几层的网络能有更大的感受野。模型使用了Softmax分布对各个音频样本的条件分布建模。
这个模型在多人情景的语音生成、文本到语音的转换、音乐音频建模等方面进行了评估。测试中使用的是平均意见评分(MOS),MOS可以评测声音的质量,本质上就是一个人对声音质量的评价一样。它有1到5之间的数字,其中5表示质量最好。
下图显示了1-5级waveNet的语音质量
Tacotron: 端到端的语音合成
文章链接:https://arxiv.org/abs/1703.10135
这篇文章的作者来自谷歌。Tacotron是一种端到端的生成性文本转化语音的模型,可直接从文本和音频对合形成语音。Tacotron在美式英语上获得3.82分的平均得分。Tacotron是在帧级生成语音,因此比样本级自回归的方法更快。
这个模型是在音频和文本对上进行的训练,因此它可以非常方便地应用到新的数据集上。Tacotron是一个seq2seq模型,该模型包括一个编码器、一个基于注意力的解码器以及一个后端处理网络(post-processing net)。如下框架图所示,该模型输入字符,输出原始谱图。然后把这个谱图转换成波形图。
下图显示了CBHG模块的结构。它由1-D卷积滤波器,highway networks和双向GRU(Gated Recurrent Unit)组成。
将字符序列输入编码器,编码器将提取出文本的顺序表示。每个字符被表示为一个独热向量嵌入到连续向量中。然后加入非线性变换,再然后加上一个dropout,以减少过度拟合。这在本质上减少了单词的发音错误。
模型所用的解码器是基于内容注意力的tanh解码器。然后使用Griffin-Lim算法生成波形图。该模型使用的超参数如下所示。
下图显示了与其他替代方案相比,Tacotron的性能优势。
Deep Voice 1: 实时神经文本到语音合成
文章链接:https://arxiv.org/abs/1702.07825
这篇文章的作者来自百度硅谷人工智能实验室。Deep Voice是一个利用深度神经网络开发的文本到语音的系统.
它有五个重要的组成模块:
- 定位音素边界的分割模型(基于使用连接时间分类(CTC)损失函数的深度神经网络);
- 字母到音素的转换模型(字素到音素是在一定规则下产生单词发音的过程);
- 音素持续时间预测模型;
- 基频预测模型;
- 音频合成模型(一个具有更少参数的WaveNet变体)。
字母到音素模型将英文字符转换为音素。分割模型识别每个音素在音频文件中开始和结束的位置。音素持续时间模型预测音素序列中每个音素的持续时间。
基频模型预测音素是否发声。音频合成模型则综合了字母到音素转换模型、音素持续时间模型、基频预测模型等的输出进行音频合成。
以下是它与其他模型的对比情况
Deep Voice 2: 多说话人神经文本语音转换
文章链接:https://arxiv.org/abs/1705.08947
这篇文章是百度硅谷人工智能实验室在Deep Voice上的二次迭代。他们介绍了一种利用低维可训练说话人嵌入来增强神经文本到语音的方法,这可以从单个模型产生不同的声音。
该模型与DeepVoice 1有类似的流水线,但它在音频质量上却有显著的提高。该模型能够从每个说话人不到半个小时的语音数据中学习数百种独特的声音。
作者还介绍了一种基于WaveNet的声谱到音频的神经声码器,并将其与Taco tron结合,代替Griffin-Lim音频生成。这篇文章的重点是处理多个说话人而每个说话人的数据有非常少的情况。模型的架构类似于Deep Voice 1,训练过程如下图所示。
Deep Voice 2和Deep Voice 1之间的主要区别在于音素持续时间模型和频率模型的分离。Deep Voice 1有一个用于联合预测音素持续时间和频率曲线的单一模型; 而在Deep Voice 2中,则先预测音素持续时间,然后将它们用作频率模型的输入。
Deep Voice 2中的分割模型使用一种卷积递归结构(采用连接时间分类(CTC)损失函数)对音素对进行分类。Deep Voice 2的主要修改是在卷积层中添加了大量的归一化和残余连接。它的发声模型是基于WaveNet架构的。
从多个说话人合成语音,主要通过用每个说话人的单个低维级说话人嵌入向量增强每个模型来完成的。说话人之间的权重分配,则是通过将与说话人相关的参数存储在非常低维的矢量中来实现。
递归神经网络(RNN)的初始状态由说话人声音的嵌入产生。采用均匀分布的方法随机初始化说话人声音的嵌入,并用反向传播对其进行联合训练。说话人声音的嵌入包含在模型的多个部分中,以确保能考虑到每个说话人的声音特点。
接下来让我们看看与其他模型相比它的性能如何
原文链接:https://heartbeat.fritz.ai/a-2019-guide-to-speech-synthesis-with-deep-learning-630afcafb9dd

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
透过AI足球教练,看人工智能拐点








广告


写评论取消
回复取消