











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






神经机器翻译与代码(上)
2019年12月28日 由 sunlei 发表
513097
0
目录
机器翻译
统计机器翻译
神经机器翻译
编码器
解码器
注意机制
训练
为翻译德语短语英译的Keras完整代码
机器翻译
机器翻译是将一种语言的源文本自动转换成另一种语言的文本的任务。
在机器翻译任务中,输入已经由某种语言中的符号序列组成,计算机程序必须将其转换成另一种语言中的符号序列。
给定源语言中的文本序列,就没有将该文本翻译成另一种语言的最佳方法。这是因为人类语言天生的模糊性和灵活性。这使得自动机器翻译的挑战变得困难,也许是人工智能中最困难的挑战之一:
事实是,准确的翻译需要背景知识,以解决歧义和建立句子的内容。
经典的机器翻译方法通常涉及将源语言中的文本转换为目标语言的规则。这些规则通常是由语言学家开发的,可以在词汇、句法或语义层面进行操作。对规则的关注为这一研究领域命名:基于规则的机器翻译,简称RBMT。
RBMT的特点是明确使用和手动创建语言规则和表示。
经典的机器翻译方法的主要局限性既有开发规则所需的专业知识,也有大量的规则和例外。
统计机器翻译
统计机器翻译(Statistical machine translation,简称SMT)是使用统计模型,学习将文本从源语言翻译成目标语言,给出大量实例的语料库。
使用统计模型的这一任务可以正式表述如下:
给定目标语中的一个句子T,我们从句子中求出译者所产生的句子S。我们知道,通过选择给定T中可能性最大的句子S,我们的出错几率会降到最低。因此,我们希望选择S,以最大化Pr(S|T)。
神经机器翻译
神经机器翻译,简称NMT,是利用神经网络模型来学习机器翻译的统计模型。
这种方法的主要好处是,可以直接对单个系统进行源文本和目标文本的培训,不再需要统计机器学习中使用的专门系统的流水线。
与传统的基于短语的翻译系统不同,基于短语的翻译系统由许多单独调整的小的子组件组成,神经机器翻译试图建立和训练一个单一的、大的神经网络,它可以读取一个句子并输出正确的翻译。
——联合学习对齐和翻译的神经机器翻译,2014
因此,神经机器翻译系统被称为端到端系统,因为翻译只需要一个模型。
NMT的优点在于它能够以端到端方式直接学习从输入文本到相关输出文本的映射。
事实上,准确的翻译需要背景知识,以解决歧义和建立句子的内容。
——谷歌的神经机器翻译系统:弥补人与机器翻译之间的鸿沟,2016

编码器
编码器的任务是提供输入语句的表示形式。输入句子是一个单词序列,我们首先参考嵌入矩阵。然后,和前面描述的基本语言模型一样,我们使用递归神经网络处理这些单词。这就产生了用每个单词的左上下文编码的隐藏状态,即,前面所有的单词。为了得到正确的上下文,我们还构建了一个从右到左的递归神经网络,或者更准确地说,从句子的结尾到开头。具有两个向两个方向运行的递归神经网络称为双向递归神经网络。
解码器
解码器是一个递归神经网络。它对输入上下文和先前的隐藏状态和输出单词预测进行某种表示,并生成新的隐藏解码器状态和新的输出单词预测。
如果我们使用LSTMs作为编码器,那么我们也使用LSTMs作为解码器,作为隐藏的状态。我们现在预测输出单词。这种预测以概率分布的形式出现在整个输出词汇表中。如果我们有一个50000字的词汇表,那么预测是一个50000维向量,每个元素对应于词汇表中一个字的预测概率
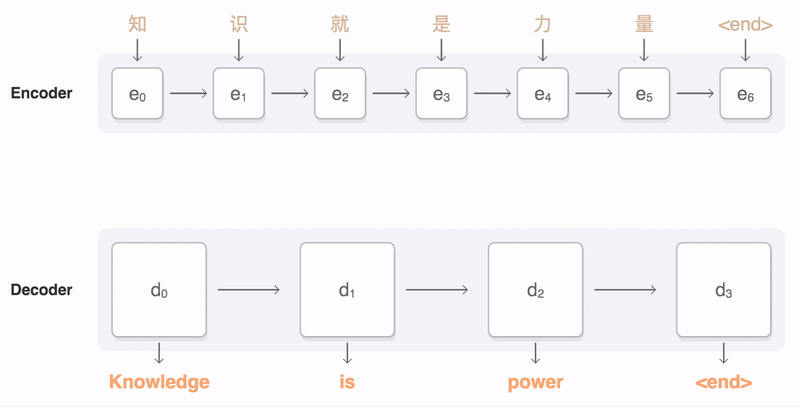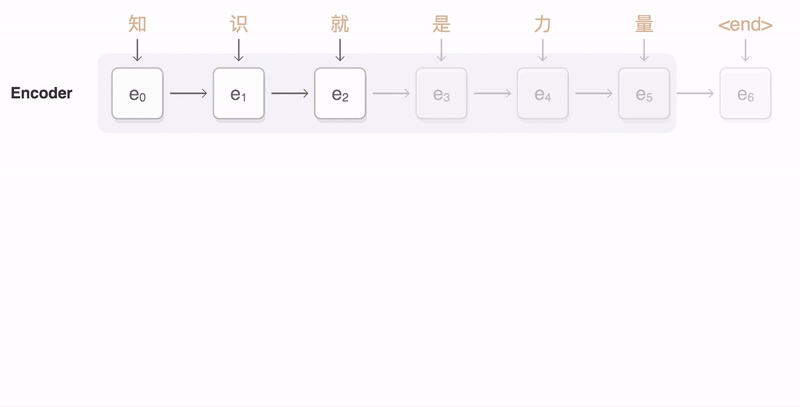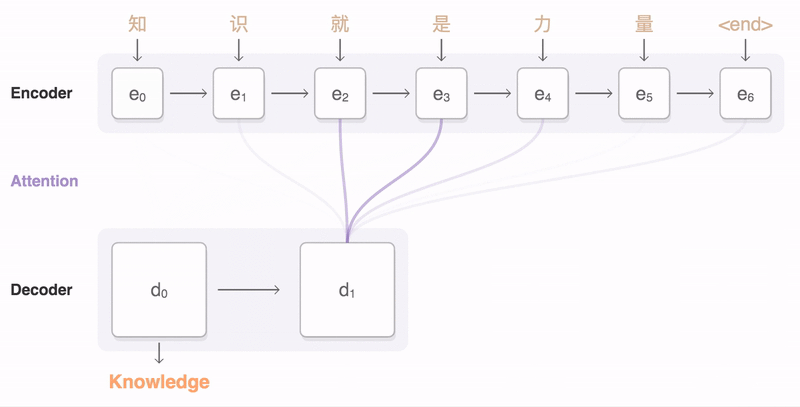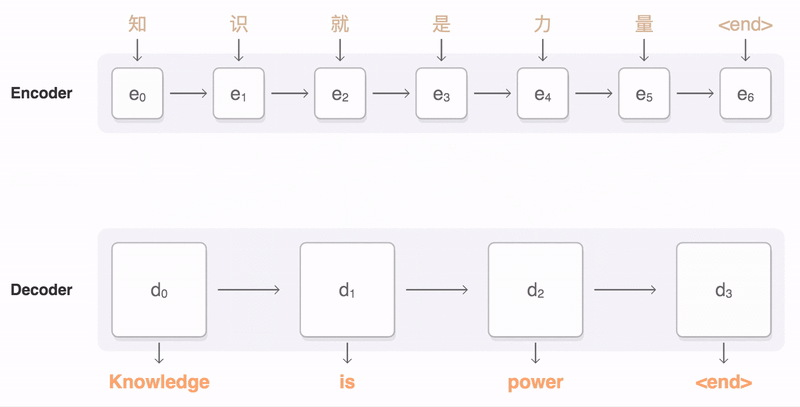
注意机制
我们目前有两个未解决的问题。解码器给我们一个单词表示序列hj =(←- hj,−→hj),解码器期望每一步i有一个上下文ci。我们现在描述将这些末端连接在一起的注意机制。使用典型的神经网络图很难将注意力机制可视化,但图至少给出了输入和输出关系的概念。该注意机制由所有输入字表示(←- hj,−→hj)和解码器si−1的前一隐藏状态通知,并产生上下文状态ci。这样做的动机是,我们希望计算解码器状态(其中包含我们在输出语句生产中的位置信息)和每个输入单词之间的关联。基于这种关联有多强,或者换句话说,每个特定的输入单词与产生下一个输出单词有多相关,我们想要衡量它的单词表示的影响根据这种关联的强度,或者换句话说,每个特定的输入单词与生成下一个输出单词之间的关联程度,我们希望权衡其单词表示的影响
训练
有了完整的模型在手,我们现在可以更仔细地查看训练。一个挑战是,解码器中的步骤数和编码器中的步骤数随着每个训练示例的不同而不同。句子对由不同长度的句子组成,因此我们不能为每个训练示例创建相同的计算图,而是必须为每个训练示例动态创建计算图。这种技术被称为展开递归神经网络,我们已经在语言模型中讨论过了
神经机器翻译模型的实际训练要求gpu很好地适应这些深度学习模型所固有的高度并行性(只要考虑许多矩阵乘法)。为了进一步增加并行度,我们一次处理几个句子对(比如100个)。这意味着我们增加了所有状态张量的维数。举个例子。我们用向量hj表示特定句子对中的每个输入词。因为我们已经有了一个输入单词的序列,这些单词被排列在一个矩阵中。当我们处理一批句子对时,我们再次把这些矩阵排列成一个三维张量。同样,再举一个例子,解码器的隐藏状态si是每个输出字的向量。因为我们处理了一批句子,所以我们将它们的隐藏状态排列成一个矩阵。注意,在这种情况下,将所有输出单词的状态排列起来是没有帮助的,因为状态是按顺序计算的。
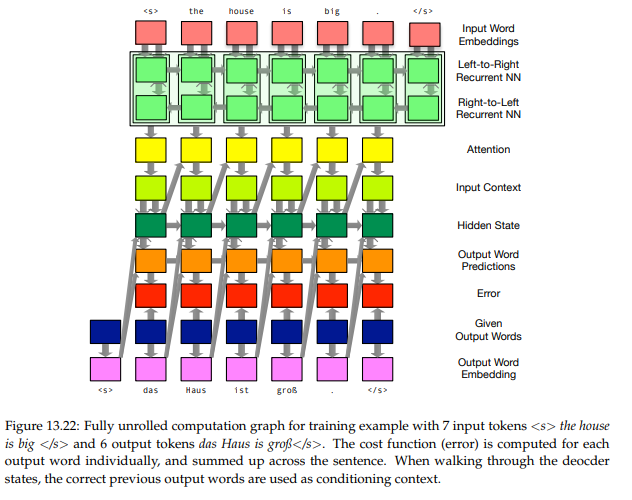
综上所述,训练包括以下步骤:洗牌培训语料库(以避免由于时间或局部顺序造成的过度偏差)•语料库的分解成maxi-batches•每个maxi-batch分解成每个mini-batch mini-batches•过程,收集梯度•所有渐变申请maxi-batch更新参数通常,训练神经机器翻译模型大约需要5 - 15时代(穿过整个训练语料库)。一种常见的停止标准是检查验证集(不属于训练数据的一部分)上模型的进度,并在验证集上的错误没有改进时停止。训练时间过长不会导致任何进一步的改善,甚至可能由于过度拟合而降低性能。
原文链接:https://medium.com/@umerfarooq_26378/neural-machine-translation-with-code-68c425044bbd

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
标签平滑与深度学习








广告


写评论取消
回复取消