











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Flyte,一个维护人工智能工作流程的平台
2020年01月08日 由 TGS 发表
12031
0
 Uber最新发布了一款开源的人工智能调试工具,Lyft随即就发布了Flyte。Flyte是一个结构化、分布式的平台,支持并发、可扩展和可维护的机器学习工作流。该公司表示,Flyte已经在内部为人工智能模型培训和数据处理提供了三年多的服务,成为团队进一步推进Lyft的定价、位置、估计到达时间、地图和自动驾驶产品的选择工具。
Uber最新发布了一款开源的人工智能调试工具,Lyft随即就发布了Flyte。Flyte是一个结构化、分布式的平台,支持并发、可扩展和可维护的机器学习工作流。该公司表示,Flyte已经在内部为人工智能模型培训和数据处理提供了三年多的服务,成为团队进一步推进Lyft的定价、位置、估计到达时间、地图和自动驾驶产品的选择工具。Lyft表示:“数据现在是公司的主要资产,执行大规模的计算任务对业务来说至关重要,但从运营的角度来看,这是有问题的。扩展、监视和管理计算集群,是所有产品团队的负担,这减慢了迭代和随后的产品创新。此外,这些工作流通常具有复杂的数据依赖关系,Flyte的任务就是通过简化这个流程,来提高机器学习和数据处理的开发速度。事实上,Flyte现在管理着7000多个独特的工作流,总计每月执行超过10万次、完成100万个任务、具有1000万个容器。”
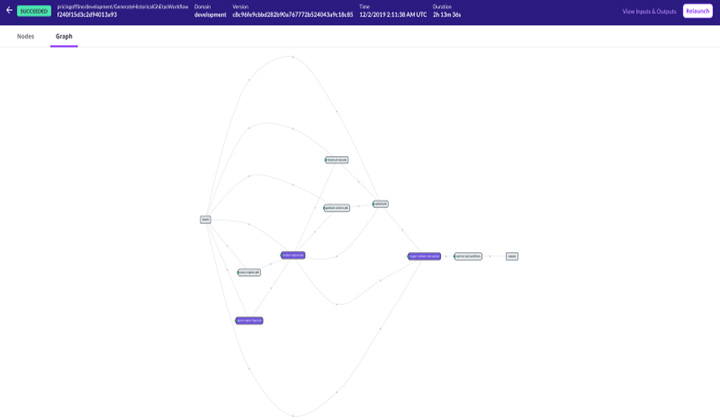 Flyte支持多用户服务,允许团队在独立的存储库上工作并部署它们,而不会影响平台的其他部分。其代码的版本化和依赖关系的容器化,确保了所有的执行都是可重复的。工作流可以被参数化,并具有丰富的数据沿袭,例如,允许开发人员在每次运行时调用不同的参数。Flyte会智能地使用以前执行时缓存的输出,以节省时间和内存。
Flyte支持多用户服务,允许团队在独立的存储库上工作并部署它们,而不会影响平台的其他部分。其代码的版本化和依赖关系的容器化,确保了所有的执行都是可重复的。工作流可以被参数化,并具有丰富的数据沿袭,例如,允许开发人员在每次运行时调用不同的参数。Flyte会智能地使用以前执行时缓存的输出,以节省时间和内存。Flyte任务可以是任意复杂的——从单个容器执行到Hive集群中的远程查询。更好的是,它们可以通过FlyteKit扩展或是后端插件进行扩展,从而允许贡献者提供与第三方服务和系统的集成,同时,提供对资源的细粒度控制。它的构建是为了在现代产品、公司和应用程序所需的规模方面,为机器学习和数据编排提供动力和加速。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消