











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






华为诺亚方舟开源预训练模型“哪吒”,多项任务均达到SOTA
2020年01月14日 由 TGS 发表
446735
0
 BERT之后,新的预训练语言模型XLnet、RoBERTa、ERNIE不断推出,这次,华为诺亚方舟实验室开源了基于BERT的中文预训练语言模型NEZHA(哪吒),寓意模型能像哪吒那样三头六臂、大力出奇迹,可以处理很多不同的自然语言任务。
BERT之后,新的预训练语言模型XLnet、RoBERTa、ERNIE不断推出,这次,华为诺亚方舟实验室开源了基于BERT的中文预训练语言模型NEZHA(哪吒),寓意模型能像哪吒那样三头六臂、大力出奇迹,可以处理很多不同的自然语言任务。据介绍,当前版本的NEZHA基于BERT模型,并进行了多处优化,能够在一系列中文自然语言理解任务达到先进水平。
NEZHA模型的实验中采用了5个中文自然语言理解任务,即CMRC(中文阅读理解)、XNLI(自然语言推断)、LCQMC(句义匹配)、PD-NER (命名实体识别任务)、ChnSenti(情感分类)。
研究人员在中文维基百科、中文新闻、百度百科数据上训练NEZHA模型,并且和谷歌发布的中文BERT,以及哈工大和科大讯飞联合发布的BERT-WWM,还有百度发布的ERNIE-Baidu进行了比较。从下表可以看出,NEZHA在XNLI,LCQMC,PeoplesDaily NER,ChnSenti任务上达到了先进水平(SOTA)。表中NEZHA,NEZHA-WWM和NEZHA-Span分别代表由原始的BERT预训练任务训练得到的,加入全词Mask训练得到的以及加入Span预测任务训练得到的NEZHA模型(三者均使用了全函数式相对位置编码)。
此外,诺亚方舟实验室还开源了TinyBERT预训练语言模型。
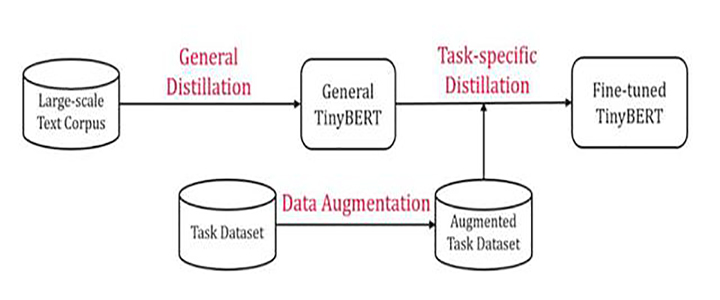 尽管语言模型预训练(例如BERT)大大改善了许多自然语言处理任务的性能。但是,预训练语言模型通常在计算上昂贵且占用了大量内存,因此很难在某些资源受限的设备上有效执行它们。为了加快推理速度、减小模型大小并同时保持精度,华为研究人员提出了一种新颖的transformer蒸馏方法,该方法是针对基于transformer模型专门设计的知识蒸馏(KD)方法。
尽管语言模型预训练(例如BERT)大大改善了许多自然语言处理任务的性能。但是,预训练语言模型通常在计算上昂贵且占用了大量内存,因此很难在某些资源受限的设备上有效执行它们。为了加快推理速度、减小模型大小并同时保持精度,华为研究人员提出了一种新颖的transformer蒸馏方法,该方法是针对基于transformer模型专门设计的知识蒸馏(KD)方法。通过利用这种新的知识蒸馏方法,可以将BERT中编码的大量知识很好地转移到TinyBERT。此外,他们为TinyBERT引入了一个新的两阶段学习框架,该框架在预训练阶段和特定任务的学习阶段都执行transformer蒸馏方法。该框架确保TinyBERT可以捕获BERT的一般领域知识和特定任务知识。在GLUE基准测试中,TinyBERT相比BERT小7.5倍,比其推理的速度快9.4倍,并且在自然语言理解任务中具有竞争优势。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消