











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






DeepMind用人工智能解开多巴胺的秘密
2020年01月16日 由 TGS 发表
297971
0
 Demis Hassabis创立了DeepMind,其目标是通过重新创造智能本身,解开世界上一些棘手的问题。本周的《自然》杂志上,DeepMind发表了一篇论文,该论文解决了生物医学领域的艰巨挑战。
Demis Hassabis创立了DeepMind,其目标是通过重新创造智能本身,解开世界上一些棘手的问题。本周的《自然》杂志上,DeepMind发表了一篇论文,该论文解决了生物医学领域的艰巨挑战。论文来自DeepMind的神经科学团队,提出了这样一个观点:人工智能研究的发展可以作为理解大脑如何学习的框架。研究是在DeepMind将人工智能应用于预测急性肾损伤(即AKI)、具有挑战性的游戏环境,如围棋、shogi、国际象棋、数十款雅达利游戏,以及动视暴雪(Activision Blizzard)的《星际争霸2》之后进行的。
在一篇关于多巴胺的论文中,来自DeepMind和哈佛大学的研究团队调查了大脑是否以概率分布而非单一平均值来代表未来可能的奖励——这是一个数学函数,提供了不同结果发生的概率。他们从腹侧被盖区的录音中发现了“分布强化学习”的证据。最近,DeepMind将注意力转向了理性机制,产生了能够将类人推理技能和逻辑应用于解决问题的合成神经网络。2018年,DeepMind的研究人员进行了一项实验,表明前额叶皮层并不像之前认为的那样,依靠突触重量的变化来学习规则结构,而是使用直接编码在多巴胺中。
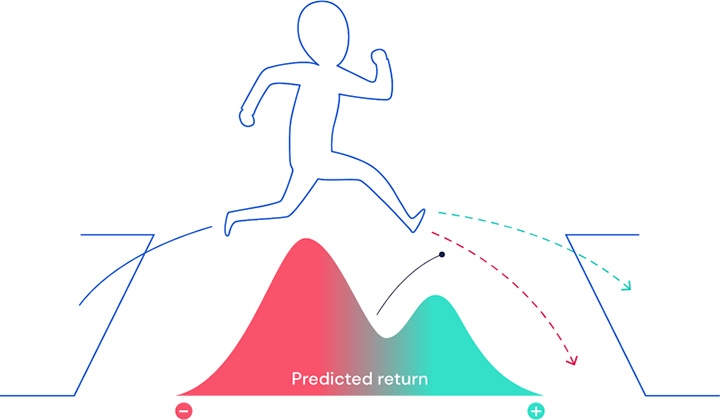 研究人员利用分布强化学习扩展多巴胺的典范奖励预测误差理论。多巴胺细胞改变它们的放电率来表示预测错误,这意味着当收到奖励时,预测错误应该为零,是预测的细胞大小。考虑到这一点,研究人员确定了每个细胞的换向点——多巴胺细胞没有改变其放电率的奖赏大小——并将它们进行比较,看看是否有什么不同。
研究人员利用分布强化学习扩展多巴胺的典范奖励预测误差理论。多巴胺细胞改变它们的放电率来表示预测错误,这意味着当收到奖励时,预测错误应该为零,是预测的细胞大小。考虑到这一点,研究人员确定了每个细胞的换向点——多巴胺细胞没有改变其放电率的奖赏大小——并将它们进行比较,看看是否有什么不同。在最后一项实验中,研究人员试图从多巴胺细胞的放电率来解码奖赏分布。结果是成功的:通过执行推理,他们成功重建了一个与老鼠实验任务中奖励实际分配相匹配的分配。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消